Certifying Hamilton-Jacobi Reachability Learned via Reinforcement Learning
作者: Prashant Solanki, Isabelle El-Hajj, Jasper J. van Beers, Erik-Jan van Kampen, Coen C. de Visser
分类: eess.SY
发布日期: 2026-02-18
💡 一句话要点
提出一种可认证的强化学习Hamilton-Jacobi可达性分析框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Hamilton-Jacobi可达性 形式化验证 安全关键系统 可认证性
📋 核心要点
- 现有强化学习方法在安全关键系统中的应用受限于缺乏形式化验证手段,难以保证策略的安全性。
- 该论文提出一种基于Hamilton-Jacobi可达性分析的框架,将强化学习误差转化为可认证的安全边界。
- 通过在双积分器系统上的实验,验证了该框架能够生成可证明正确的后向可达集内外包络。
📝 摘要(中文)
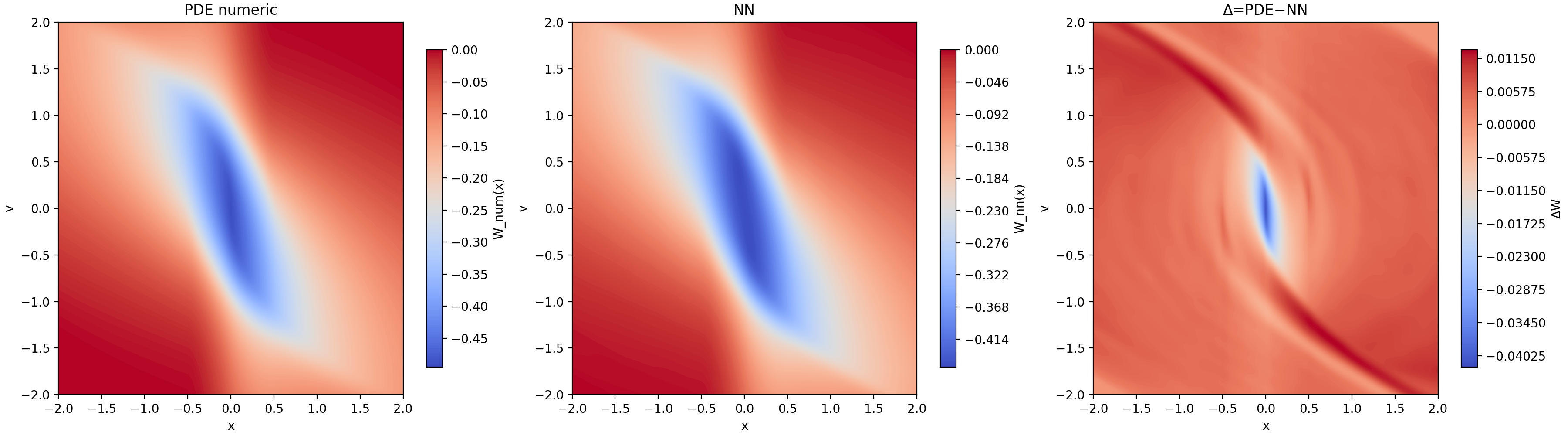
本文提出了一个框架,用于认证通过强化学习(RL)学习到的Hamilton-Jacobi (HJ)可达性。该框架基于一种折扣初始时间旅行成本公式,该公式使小步RL值迭代在理论上等价于具有阻尼的前向Hamilton-Jacobi (HJ)方程。我们将经过认证的学习误差转换为严格后向可达管的校准内外包络。核心方法是一个加性偏移恒等式:如果$W_λ$解决了折扣旅行成本Hamilton-Jacobi-Bellman (HJB)方程,那么$W_ε:=W_λ+ ε$解决了具有恒定偏移$λε$的相同PDE。这意味着均匀值误差完全等于一个常数HJB偏移。我们通过两种途径建立这种均匀值误差:(A) Bellman算子残差界,和(B) HJB PDE松弛界。我们的框架保留了HJ级别的安全语义,并且与深度RL兼容。我们通过可满足性模理论(SMT)正式认证,通过强化学习学习到的值函数,以在感兴趣的紧凑区域上诱导可证明正确的内部和外部后向可达集包络,从而在双积分器系统上演示了该方法。
🔬 方法详解
问题定义:论文旨在解决如何对通过强化学习得到的控制策略进行形式化验证,特别是针对安全关键系统。现有强化学习方法缺乏可认证性,难以保证策略在所有情况下的安全性,尤其是在状态空间较大时,难以进行穷举测试。因此,需要一种方法来验证强化学习策略的安全性,并提供可信赖的安全边界。
核心思路:论文的核心思路是将强化学习过程与Hamilton-Jacobi (HJ)可达性分析相结合,利用HJ可达性分析的严格数学基础来认证强化学习策略的安全性。通过将强化学习中的值函数误差转化为HJ方程中的偏移量,从而建立强化学习策略的安全边界。这种方法允许将强化学习的灵活性与HJ可达性分析的可靠性相结合。
技术框架:该框架主要包含以下几个阶段: 1. 强化学习训练:使用强化学习算法(如深度强化学习)训练控制策略,得到值函数$W_λ$。 2. 误差界定:通过Bellman算子残差界或HJB PDE松弛界来估计值函数$W_λ$的误差。 3. 安全边界计算:利用加性偏移恒等式,将值函数误差转化为HJ方程的偏移量,从而计算后向可达集的内外包络。 4. 形式化验证:使用可满足性模理论(SMT)等形式化验证工具,验证计算得到的安全边界的正确性。
关键创新:该论文的关键创新在于建立了强化学习值函数误差与HJ方程偏移量之间的精确关系,即加性偏移恒等式。该恒等式允许将强化学习的不确定性转化为可认证的安全边界,从而实现了对强化学习策略的形式化验证。此外,该框架兼容深度强化学习,使其能够应用于复杂系统。
关键设计: * 折扣初始时间旅行成本公式:该公式将强化学习值迭代与前向HJ方程联系起来。 * 加性偏移恒等式:$W_ε:=W_λ+ ε$解决了具有恒定偏移$λε$的相同HJB方程。 * 误差界定方法:使用Bellman算子残差界和HJB PDE松弛界来估计值函数误差。 * 形式化验证工具:使用SMT求解器来验证安全边界的正确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架能够在双积分器系统上成功认证通过强化学习学习到的值函数,并生成可证明正确的后向可达集内外包络。通过SMT验证,证明了该方法能够有效地保证系统的安全性。该方法为强化学习在安全关键领域的应用提供了有力的支持。
🎯 应用场景
该研究成果可应用于安全关键领域,如自动驾驶、航空航天和机器人控制。通过认证强化学习策略的安全性,可以提高这些系统在复杂环境中的可靠性和安全性。该方法还有助于开发更安全、更可靠的自主系统,并降低潜在的风险。
📄 摘要(原文)
We present a framework to \emph{certify} Hamilton--Jacobi (HJ) reachability learned by reinforcement learning (RL). Building on a discounted initial time \emph{travel-cost} formulation that makes small-step RL value iteration provably equivalent to a forward Hamilton--Jacobi (HJ) equation with damping, we convert certified learning errors into calibrated inner/outer enclosures of strict backward reachable tube. The core device is an additive-offset identity: if $W_λ$ solves the discounted travel-cost Hamilton--Jacobi--Bellman (HJB) equation, then $W_\varepsilon:=W_λ+ \varepsilon$ solves the same PDE with a constant offset $λ\varepsilon$. This means that a uniform value error is \emph{exactly} equal to a constant HJB offset. We establish this uniform value error via two routes: (A) a Bellman operator-residual bound, and (B) a HJB PDE-slack bound. Our framework preserves HJ-level safety semantics and is compatible with deep RL. We demonstrate the approach on a double-integrator system by formally certifying, via satisfiability modulo theories (SMT), a value function learned through reinforcement learning to induce provably correct inner and outer backward-reachable set enclosures over a compact region of interest.