Fine-Tuning LLMs to Generate Economical and Reliable Actions for the Power Grid
作者: Mohamad Chehade, Hao Zhu
分类: eess.SY, cs.AI
发布日期: 2026-02-17
💡 一句话要点
提出多阶段适应管道以优化电网的可靠性与经济性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电力系统 大型语言模型 微调 电压控制 公共安全电力关闭 优化算法 实时调度
📋 核心要点
- 核心问题:现有方法在应对PSPS引发的快速拓扑变化时,难以有效识别和执行可靠的切换操作。
- 方法要点:提出一种多阶段适应管道,通过微调LLM生成符合电压约束的切换计划,提升了决策的可靠性。
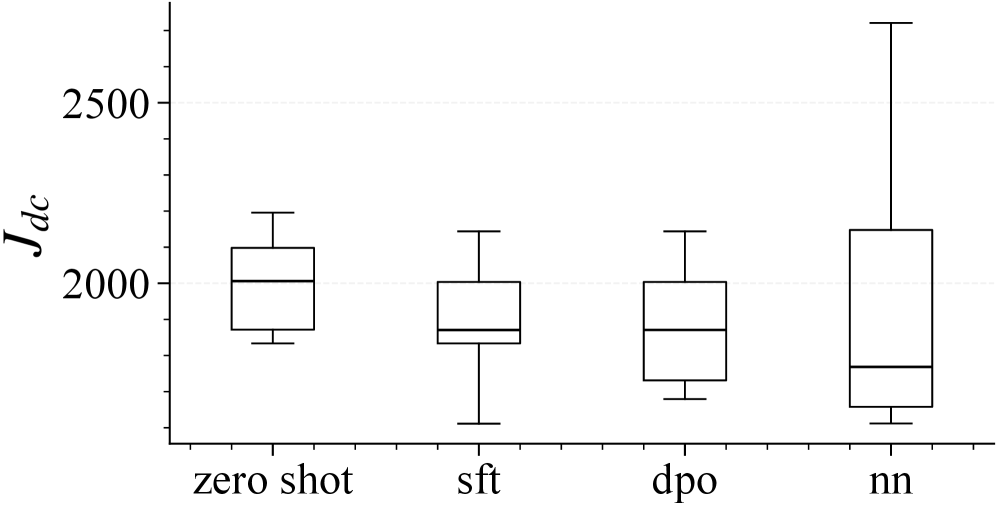
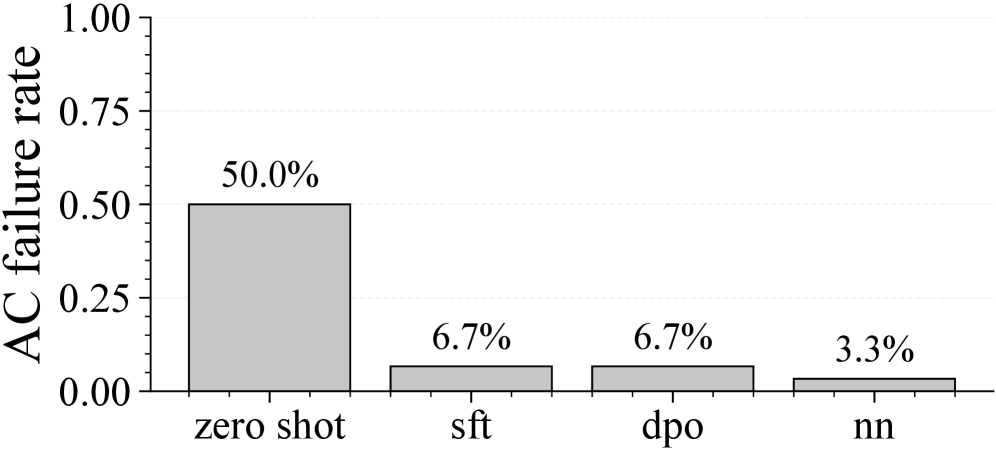
- 实验或效果:在IEEE 118-bus PSPS场景中,微调后DC目标值显著提升,AC功率流故障率从50%降至个位数。
📝 摘要(中文)
公共安全电力关闭(PSPS)会导致快速的拓扑变化,使得标准操作点不可行,要求操作员迅速识别纠正的传输切换操作,以减少负荷削减并保持可接受的电压行为。本文提出了一种可验证的多阶段适应管道,微调指令调优的大型语言模型(LLM),从紧凑的PSPS场景摘要中生成仅开放的纠正切换计划,并在明确的切换预算下进行。首先,通过监督微调将DC-OPF MILP预言机提炼为受限动作语法,以实现可靠的解析和可行性检查。其次,直接偏好优化利用基于电压惩罚指标排名的AC评估偏好对政策进行细化,注入电压意识。最后,最佳选择在推理时选择目标指标下的最佳可行候选。实验结果表明,微调显著提高了DC目标值,减少了AC功率流故障率,并改善了电压惩罚结果。
🔬 方法详解
问题定义:本文旨在解决公共安全电力关闭(PSPS)导致的电网拓扑快速变化问题。现有方法在此情况下难以快速识别有效的切换操作,导致负荷削减和电压问题。
核心思路:论文提出了一种多阶段适应管道,通过微调大型语言模型(LLM),生成符合电压约束的纠正切换计划,从而提高决策的可靠性和经济性。
技术框架:整体架构包括三个主要阶段:首先进行监督微调,将DC-OPF MILP预言机提炼为受限动作语法;其次通过直接偏好优化,利用AC评估的偏好对政策进行细化;最后在推理时进行最佳选择,选出最佳可行候选。
关键创新:最重要的技术创新在于引入了电压意识的直接偏好优化,超越了传统的DC模仿方法,使得生成的切换计划在电压控制方面更为可靠。
关键设计:在微调过程中,采用了特定的损失函数来平衡电压惩罚和切换成本,并设计了适合电网特性的网络结构,以确保生成计划的可行性和有效性。
🖼️ 关键图片
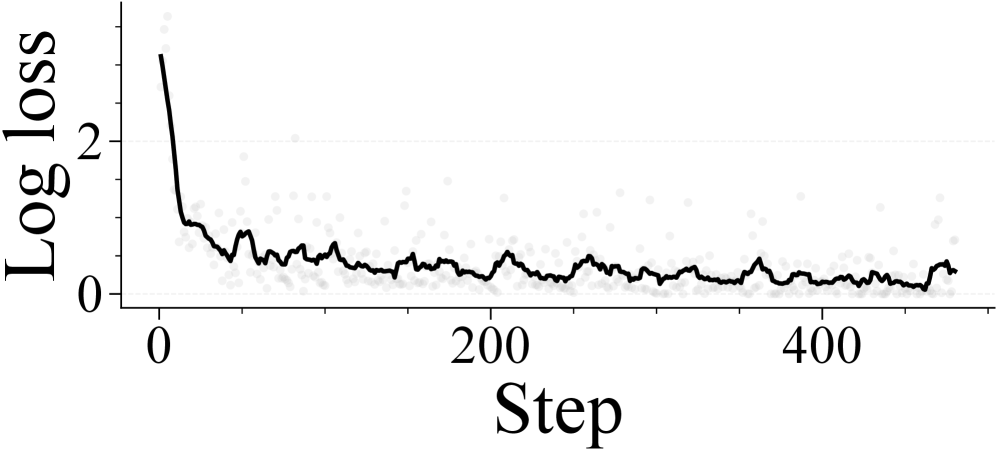
📊 实验亮点
实验结果显示,微调后的模型在IEEE 118-bus PSPS场景中,DC目标值显著提高,AC功率流故障率从50%降至个位数,电压惩罚结果也有明显改善,表明该方法在实际应用中的有效性和可靠性。
🎯 应用场景
该研究的潜在应用领域包括电力系统的实时调度与管理,特别是在应对自然灾害或突发事件时的电网稳定性维护。通过优化切换计划,可以有效降低负荷削减的风险,提升电网的经济性和可靠性,具有重要的实际价值和社会影响。
📄 摘要(原文)
Public Safety Power Shutoffs (PSPS) force rapid topology changes that can render standard operating points infeasible, requiring operators to quickly identify corrective transmission switching actions that reduce load shedding while maintaining acceptable voltage behavior. We present a verifiable, multi-stage adaptation pipeline that fine-tunes an instruction-tuned large language model (LLM) to generate \emph{open-only} corrective switching plans from compact PSPS scenario summaries under an explicit switching budget. First, supervised fine-tuning distills a DC-OPF MILP oracle into a constrained action grammar that enables reliable parsing and feasibility checks. Second, direct preference optimization refines the policy using AC-evaluated preference pairs ranked by a voltage-penalty metric, injecting voltage-awareness beyond DC imitation. Finally, best-of-$N$ selection provides an inference-time addition by choosing the best feasible candidate under the target metric. On IEEE 118-bus PSPS scenarios, fine-tuning substantially improves DC objective values versus zero-shot generation, reduces AC power-flow failure from 50\% to single digits, and improves voltage-penalty outcomes on the common-success set. Code and data-generation scripts are released to support reproducibility.