Data-Driven Network LQG Mean Field Games with Heterogeneous Populations via Integral Reinforcement Learning
作者: Jean Zhu, Shuang Gao
分类: eess.SY
发布日期: 2026-02-15
备注: 8 pages
💡 一句话要点
提出基于积分强化学习的网络化异构智能体LQG均场博弈数据驱动解法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 均场博弈 积分强化学习 数据驱动 网络耦合 异构智能体
📋 核心要点
- 现有方法难以处理智能体动态未知情况下的网络化异构智能体均场博弈问题。
- 利用积分强化学习和Kleinman迭代,从轨迹数据中学习网络耦合的均场博弈策略。
- 在一定条件下,证明了学习到的策略能够收敛到真实策略,无需智能体动态参数。
📝 摘要(中文)
本文针对具有网络耦合异构智能体群体的无限时域线性二次高斯(LQG)均场博弈,建立了一种数据驱动的解决方案,其中智能体的动态特性是未知的。该解决方案依赖于积分强化学习和Kleinman迭代来求解代数Riccati方程(ARE)。所提出的算法利用轨迹数据为智能体生成网络耦合的MFG策略,并且不需要智能体动态的参数。在关于持续激励和相应ARE的唯一稳定解存在的特定技术条件下,所学习的网络耦合MFG策略被证明收敛到它们的真实值。
🔬 方法详解
问题定义:论文旨在解决网络耦合的异构智能体群体下的线性二次高斯(LQG)均场博弈问题,尤其是在智能体的动态特性未知的情况下。现有方法通常需要精确的智能体动态模型,这在实际应用中往往难以获得,限制了其应用范围。因此,如何仅通过数据学习到有效的均场博弈策略是一个关键挑战。
核心思路:论文的核心思路是利用积分强化学习(Integral Reinforcement Learning, IRL)来绕过对智能体动态模型的直接依赖。IRL通过直接学习最优控制策略的积分形式,避免了对系统动态的显式建模。结合Kleinman迭代,可以有效地求解代数Riccati方程(ARE),从而获得最优策略。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集:通过智能体的轨迹数据来估计系统状态和控制输入之间的关系。2) 策略迭代:使用Kleinman迭代求解ARE,逐步改进控制策略。3) 积分强化学习:利用IRL更新策略参数,使其更好地适应观测到的数据。4) 收敛性分析:在满足一定条件下,证明学习到的策略收敛到最优策略。
关键创新:最重要的技术创新在于将积分强化学习应用于网络耦合的异构智能体均场博弈问题,并证明了在智能体动态未知的情况下,可以通过数据驱动的方式学习到有效的均场博弈策略。与传统方法相比,该方法不需要智能体的动态模型,更具实用性。
关键设计:论文的关键设计包括:1) 使用Kleinman迭代加速ARE的求解过程。2) 引入持续激励条件,保证数据能够充分覆盖系统状态空间,从而保证学习算法的收敛性。3) 针对网络耦合的异构智能体,设计了相应的策略更新规则,考虑了智能体之间的相互影响。
🖼️ 关键图片
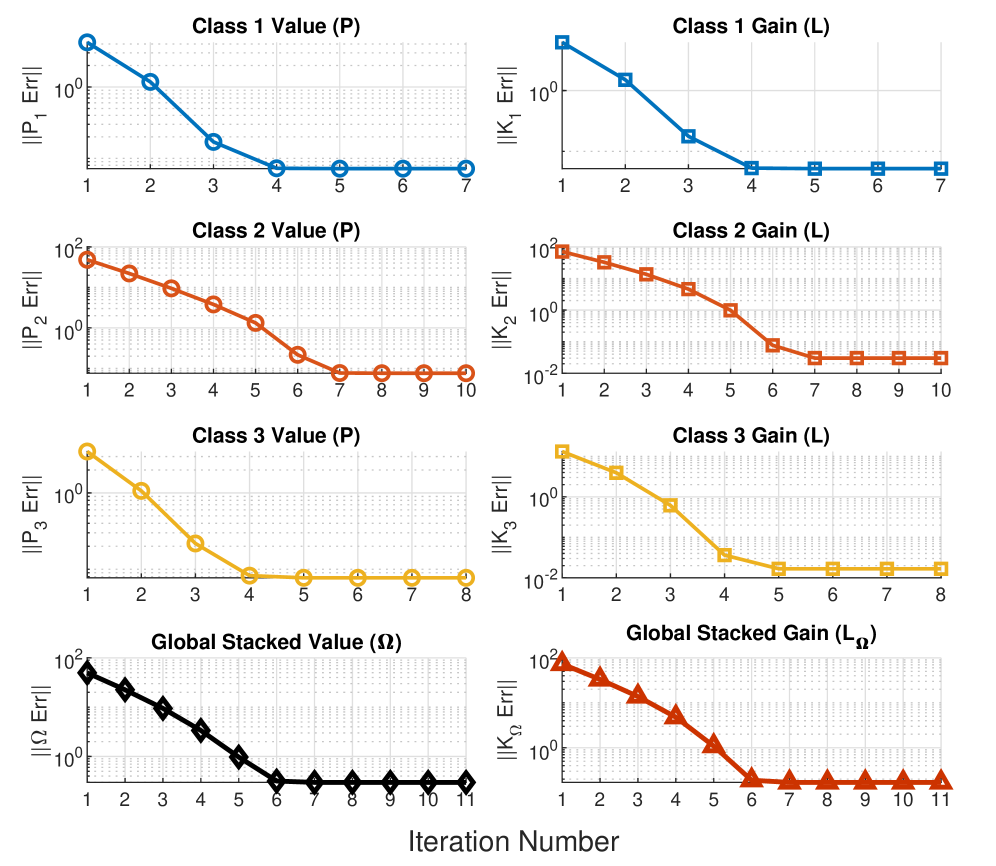
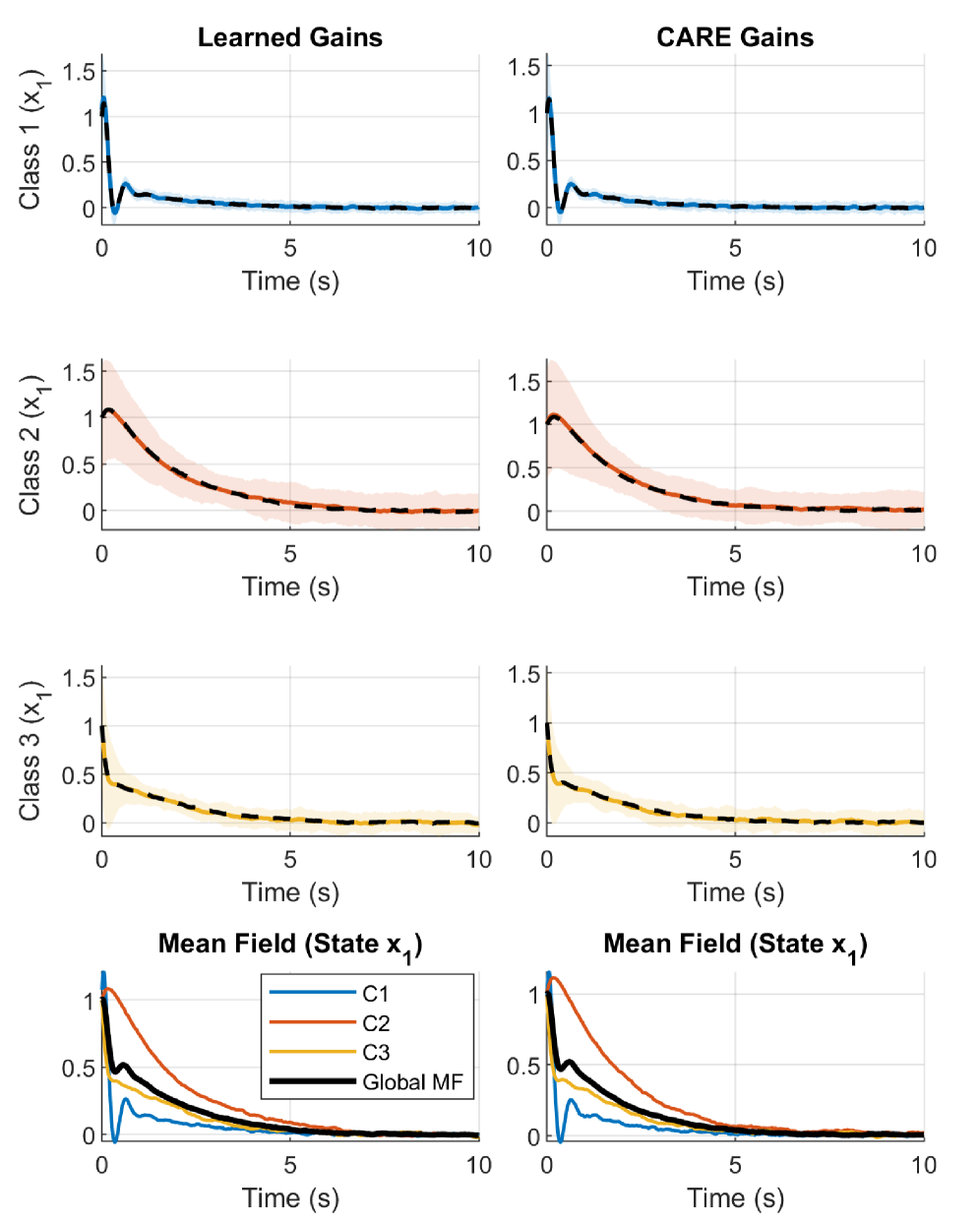
📊 实验亮点
论文通过理论分析证明了所提出的数据驱动方法能够收敛到最优策略,并在一定条件下保证了算法的稳定性。虽然论文中没有明确给出具体的数值实验结果,但理论证明表明该方法具有良好的性能和潜力。未来的工作可以进一步通过仿真实验验证该方法的有效性,并与其他基线方法进行比较。
🎯 应用场景
该研究成果可应用于智能交通系统、分布式能源管理、金融市场等领域。例如,在智能交通系统中,可以利用该方法设计车辆的协同控制策略,从而提高交通效率和安全性。在分布式能源管理中,可以优化各个能源节点的运行策略,实现能源的高效利用。该研究为解决复杂系统的协同控制问题提供了一种新的思路。
📄 摘要(原文)
This paper establishes a data-driven solution for infinite horizon linear quadratic Gaussian Mean Field Games with network-coupled heterogeneous agent populations where the dynamics of the agents are unknown. The solution technique relies on Integral Reinforcement Learning and Kleinman's iteration for solving algebraic Riccati equations (ARE). The resulting algorithm uses trajectory data to generate network-coupled MFG strategies for agents and does not require parameters of agents' dynamics. Under technical conditions on the persistency of excitation and on the existence of unique stabilizing solution to the corresponding AREs, the learned network-coupled MFG strategies are shown to converge to their true values.