Interpretable Attention-Based Multi-Agent PPO for Latency Spike Resolution in 6G RAN Slicing
作者: Kavan Fatehi, Mostafa Rahmani Ghourtani, Amir Sonee, Poonam Yadav, Alessandra M Russo, Hamed Ahmadi, Radu Calinescu
分类: eess.SY, cs.AI, eess.SP
发布日期: 2026-02-11
备注: This work has been accepted to appear in the IEEE International Conference on Communications (ICC)
💡 一句话要点
提出AE-MAPPO,解决6G RAN切片中延迟高峰问题,实现可解释的实时自动化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 6G RAN切片 多智能体强化学习 近端策略优化 注意力机制 可解释性 延迟高峰解决 服务级别协议 O-RAN
📋 核心要点
- 传统DRL和XRL方法难以有效诊断和解决6G RAN切片中突发的延迟高峰问题,影响SLA的严格执行。
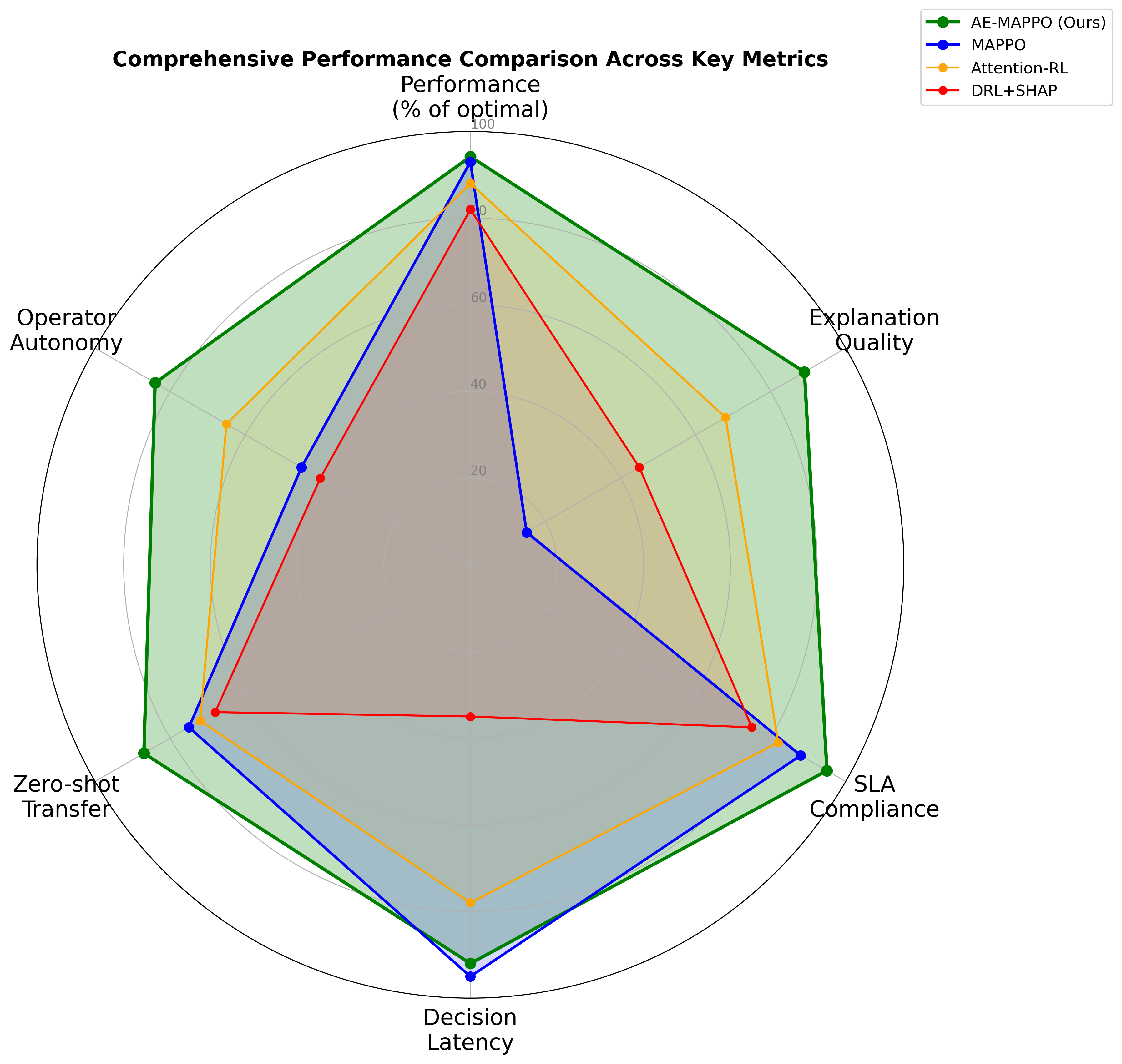
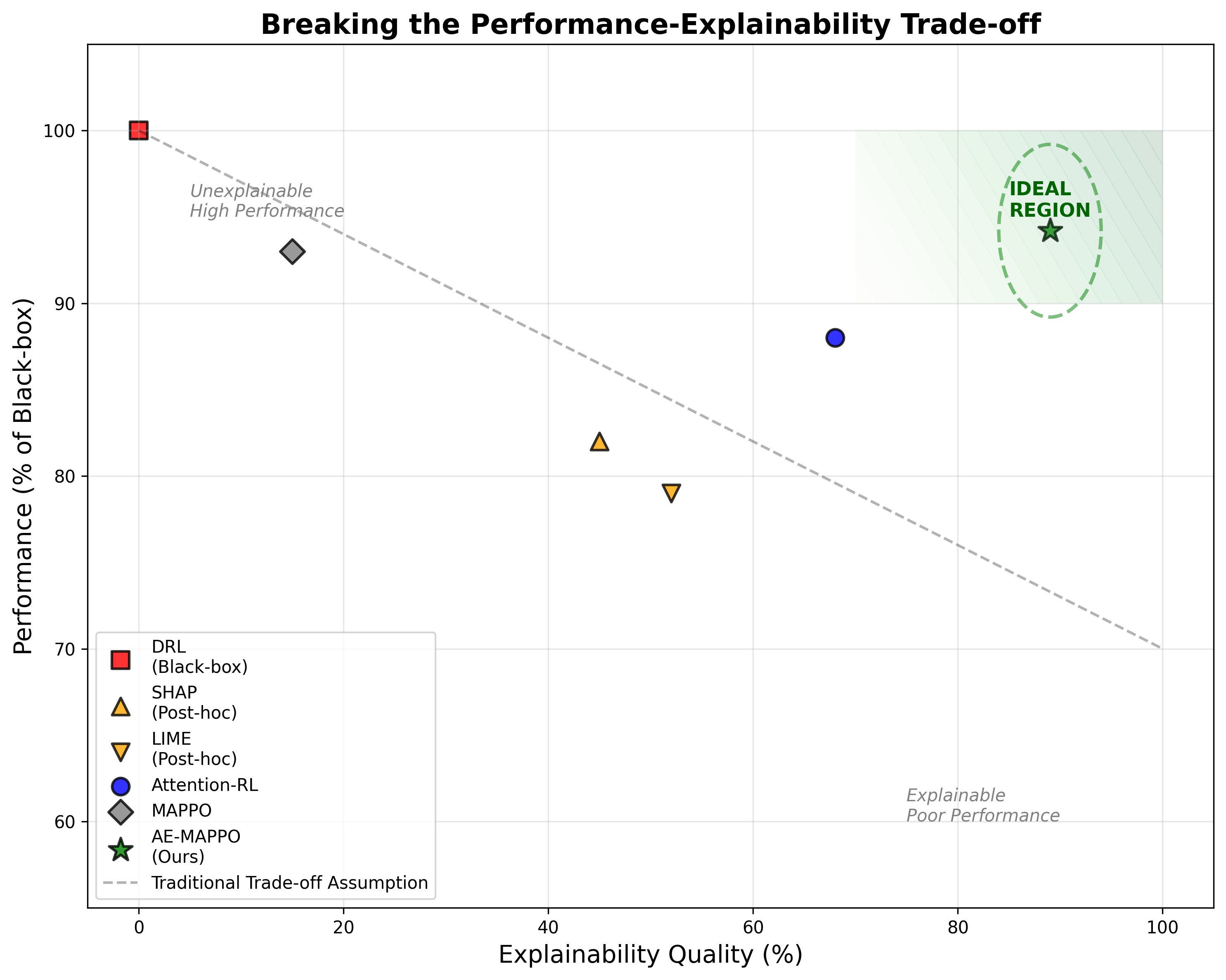
- AE-MAPPO通过集成六种注意力机制到多智能体控制中,提供零成本的、可信的解释,实现快速响应和优化。
- 实验表明,AE-MAPPO能快速解决延迟高峰,显著降低故障排除时间,并保证高可靠性和其他业务的连续性。
📝 摘要(中文)
第六代(6G)无线接入网络(RAN)必须为异构切片强制执行严格的服务级别协议(SLA),然而,传统的深度强化学习(DRL)或可解释RL(XRL)难以诊断和解决突发的延迟高峰。我们提出了Attention增强的多智能体近端策略优化(AE-MAPPO),它将六种专门的注意力机制集成到多智能体切片控制中,并将它们作为零成本、忠实的解释呈现。该框架在O-RAN时间尺度上运行,采用三阶段策略:预测、反应和切片间优化。URLLC案例研究表明,AE-MAPPO在18毫秒内解决了延迟高峰,将延迟恢复到0.98毫秒,可靠性达到99.9999%,并将故障排除时间减少了93%,同时保持了eMBB和mMTC的连续性。这些结果证实了AE-MAPPO能够将SLA合规性与固有的可解释性相结合,从而为6G RAN切片实现可信赖的实时自动化。
🔬 方法详解
问题定义:论文旨在解决6G RAN切片中,由于网络负载波动等因素引起的突发延迟高峰问题。现有方法,如传统的DRL和XRL,在诊断和解决此类问题时存在局限性,无法在保证SLA的同时提供足够的可解释性,导致难以进行实时自动化控制。
核心思路:论文的核心思路是将注意力机制融入到多智能体近端策略优化(MAPPO)框架中,利用注意力机制提取关键特征,从而实现对延迟高峰的快速诊断和响应。同时,注意力权重可以作为模型决策的解释,提高模型的可信度。通过多智能体协同控制,实现对RAN切片的优化管理。
技术框架:AE-MAPPO框架包含三个主要阶段:预测阶段、反应阶段和切片间优化阶段。预测阶段利用历史数据预测潜在的延迟高峰;反应阶段通过调整资源分配等方式,快速响应并解决延迟高峰;切片间优化阶段则考虑不同切片之间的相互影响,进行全局优化。整个框架基于O-RAN架构,能够在不同的时间尺度上运行。
关键创新:该论文的关键创新在于将六种专门设计的注意力机制集成到MAPPO框架中。这些注意力机制能够关注不同类型的输入特征,例如用户需求、网络状态等,从而更准确地识别导致延迟高峰的原因。此外,注意力权重可以作为模型决策的解释,提高了模型的可解释性和可信度。
关键设计:论文中使用了Proximal Policy Optimization (PPO)算法作为多智能体控制的基础。注意力机制的具体实现细节(如注意力头的数量、维度等)以及损失函数的设计(如如何平衡SLA合规性和资源利用率)在论文中进行了详细描述。此外,论文还针对不同的O-RAN时间尺度,设计了不同的控制策略。
🖼️ 关键图片

📊 实验亮点
URLLC案例研究表明,AE-MAPPO能够在18毫秒内解决延迟高峰,并将延迟恢复到0.98毫秒,可靠性达到99.9999%。与传统方法相比,AE-MAPPO能够将故障排除时间减少93%,同时保证eMBB和mMTC业务的连续性。这些结果表明AE-MAPPO在SLA合规性和可解释性方面具有显著优势。
🎯 应用场景
AE-MAPPO可应用于各种需要实时SLA保障的6G RAN切片场景,例如URLLC(超可靠低延迟通信)业务。该方法能够提高网络自动化程度,降低运维成本,并提升用户体验。未来,该研究可以扩展到其他网络管理任务,例如网络安全和能源效率优化。
📄 摘要(原文)
Sixth-generation (6G) radio access networks (RANs) must enforce strict service-level agreements (SLAs) for heterogeneous slices, yet sudden latency spikes remain difficult to diagnose and resolve with conventional deep reinforcement learning (DRL) or explainable RL (XRL). We propose \emph{Attention-Enhanced Multi-Agent Proximal Policy Optimization (AE-MAPPO)}, which integrates six specialized attention mechanisms into multi-agent slice control and surfaces them as zero-cost, faithful explanations. The framework operates across O-RAN timescales with a three-phase strategy: predictive, reactive, and inter-slice optimization. A URLLC case study shows AE-MAPPO resolves a latency spike in $18$ms, restores latency to $0.98$ms with $99.9999\%$ reliability, and reduces troubleshooting time by $93\%$ while maintaining eMBB and mMTC continuity. These results confirm AE-MAPPO's ability to combine SLA compliance with inherent interpretability, enabling trustworthy and real-time automation for 6G RAN slicing.