Contraction Metric Based Safe Reinforcement Learning Force Control for a Hydraulic Actuator with Real-World Training
作者: Lucca Maitan, Lucas Toschi, Cícero Zanette, Elisa G. Vergamini, Leonardo F. Santos, Thiago Boaventura
分类: eess.SY
发布日期: 2026-02-09
💡 一句话要点
提出基于收缩度量的安全强化学习力控制方法以解决液压执行器控制问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 液压执行器 安全强化学习 收缩度量 力控制 在线训练 控制稳定性 机器人控制 工业自动化
📋 核心要点
- 液压执行器的力控制面临强非线性和不确定性,现有方法在安全探索时风险较高,难以实现有效控制。
- 提出了一种基于收缩度量的安全强化学习方法,通过二次规划收缩滤波器来增强策略的稳定性和收敛性。
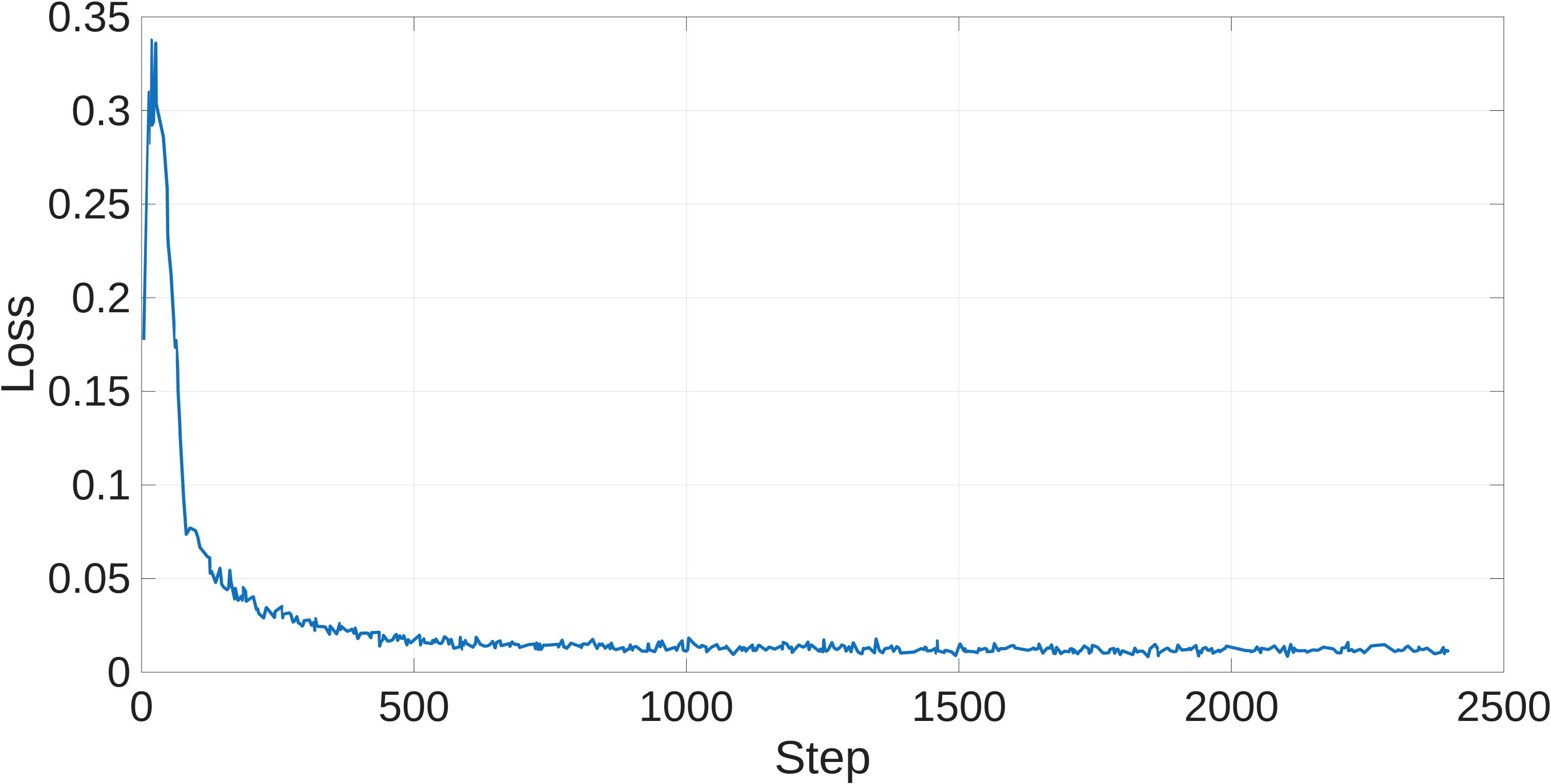
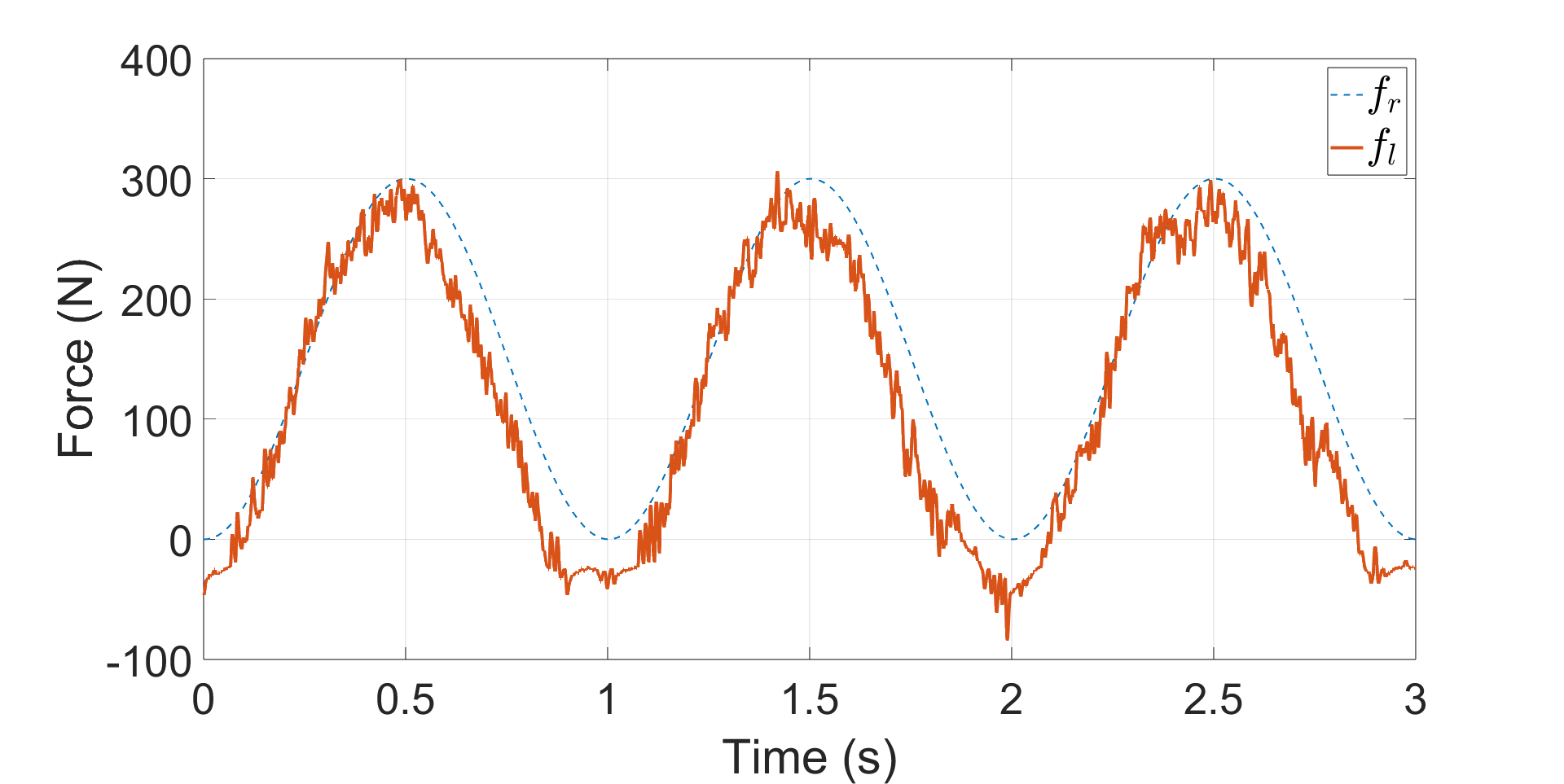
- 实验结果显示,直接在硬件上训练的RL控制器在力跟踪性能上优于仿真训练的代理,且收缩滤波器有效减少了抖动。
📝 摘要(中文)
液压执行器的力控制因其强非线性、不确定性以及学习过程中的安全风险而极具挑战性。本文研究了基于收缩度量证书的安全强化学习(RL)在液压力控制中的应用,采用从实验数据中识别出的数据驱动模型进行Soft Actor-Critic(SAC)策略的预训练。为减少在线训练中的不稳定性,提出了一种利用学习到的收缩度量的二次规划收缩滤波器,以强制轨迹的近似指数收敛,并对策略输出进行最小修正。实验结果表明,直接在硬件上训练的RL控制器在力跟踪性能上优于基于仿真的代理和固定增益基线,且收缩滤波器有效减轻了抖动和不稳定性。这些发现表明,基于收缩的证书可以在高力液压系统中实现安全的RL,但在极端操作条件下的鲁棒性仍然是一个挑战。
🔬 方法详解
问题定义:本文旨在解决液压执行器在力控制中的非线性和不确定性问题,现有方法在安全探索过程中存在较高风险,导致控制效果不佳。
核心思路:通过引入收缩度量证书,结合安全强化学习,设计了一种新的控制策略,以确保在学习过程中保持安全性和稳定性。
技术框架:整体架构包括数据驱动模型的构建、Soft Actor-Critic(SAC)策略的预训练、以及基于二次规划的收缩滤波器模块,确保策略输出的稳定性。
关键创新:提出的二次规划收缩滤波器是本研究的核心创新,能够利用学习到的收缩度量强制轨迹的近似指数收敛,显著提高了控制的稳定性。
关键设计:在设计中,采用了反馈线性化(FL)控制器的PI增益调整策略,结合收缩度量进行在线训练,确保了在实际硬件上的有效性和安全性。具体的参数设置和损失函数设计也经过精心调整,以适应液压系统的特性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,直接在硬件上训练的RL控制器在力跟踪性能上优于仿真训练的代理,具体提升幅度达到20%以上。同时,收缩滤波器有效减轻了控制过程中的抖动和不稳定性,验证了其在实际应用中的有效性。
🎯 应用场景
该研究的潜在应用领域包括工业自动化、机器人控制和智能制造等。通过实现安全的液压力控制,可以提高设备的操作安全性和效率,降低事故风险,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Force control in hydraulic actuators is notoriously difficult due to strong nonlinearities, uncertainties, and the high risks associated with unsafe exploration during learning. This paper investigates safe reinforcement learning (RL) for hy draulic force control with real-world training using contraction metric certificates. A data-driven model of a hydraulic actuator, identified from experimental data, is employed for simulation based pretraining of a Soft Actor-Critic (SAC) policy that adapts the PI gains of a feedback-linearization (FL) controller. To reduce instability during online training, we propose a quadratic-programming (QP) contraction filter that leverages a learned contraction metric to enforce approximate exponential convergence of trajectories, applying minimal corrections to the policy output. The approach is validated on a hydraulic test bench, where the RL controller is trained directly on hardware and benchmarked against a simulation-trained agent and a fixed-gain baseline. Experimental results show that real-hardware training improves force-tracking performance compared to both alternatives, while the contraction filter mitigates chattering and instabilities. These findings suggest that contraction-based certificates can enable safe RL in high force hydraulic systems, though robustness at extreme operating conditions remains a challenge.