Accuracy-Delay Trade-Off in LLM Offloading via Token-Level Uncertainty
作者: Yumin Kim, Hyeonsu Lyu, Minjae Lee, Hyun Jong Yang
分类: eess.SY, cs.AI, cs.DC
发布日期: 2026-02-08
备注: This paper has been accepted at 2025 IEEE Globecom Workshop: WS02-GAIMC: Mutual Facilitation of Generative Artificial Intelligence and Mobile Communications
💡 一句话要点
提出基于Token不确定性的LLM卸载框架,优化精度-延迟权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 移动边缘计算 模型卸载 不确定性估计 精度-延迟权衡
📋 核心要点
- 现有LLM在资源受限设备上部署困难,边缘计算卸载引入了通信和排队延迟。
- 提出基于token级别不确定性的动态卸载策略,平衡本地计算和边缘卸载。
- 实验表明,该方法在不同用户密度下,显著提升了精度和延迟的权衡。
📝 摘要(中文)
大型语言模型(LLM)为智能移动服务提供了巨大的潜力,但其计算密集性对资源受限的设备提出了挑战。移动边缘计算(MEC)允许这些设备将推理任务卸载到边缘服务器(ES),但由于通信和服务器端排队,尤其是在多用户环境中,会引入延迟。本文提出了一种不确定性感知的卸载框架,该框架基于token级别的不确定性和资源约束,动态决定是在本地执行推理还是将其卸载到ES。我们定义了一个基于margin的token级别不确定性度量,并证明了其与模型准确性之间的相关性。利用该度量,我们设计了一种贪婪卸载算法(GOA),通过优先卸载高不确定性查询,在保持准确性的同时最小化延迟。实验表明,GOA始终如一地实现了良好的权衡,在不同用户密度下,在准确性和延迟方面均优于基线策略,并且以实际的计算时间运行。这些结果确立了GOA作为MEC环境中LLM推理的可扩展且有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决在移动边缘计算环境中,如何有效地将大型语言模型(LLM)的推理任务卸载到边缘服务器,从而在精度和延迟之间取得最佳平衡的问题。现有方法要么完全在本地执行推理,导致资源受限设备不堪重负;要么全部卸载到边缘服务器,引入了不可避免的通信和排队延迟,尤其是在多用户高并发场景下,延迟问题更加突出。
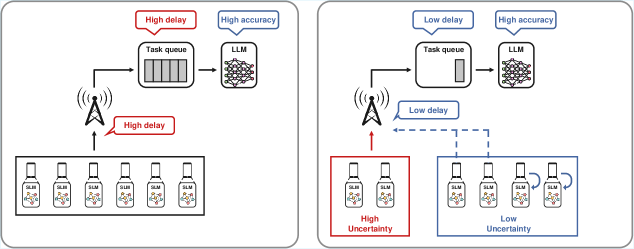
核心思路:论文的核心思路是利用LLM在生成每个token时的不确定性,动态地决定是否将该token的推理卸载到边缘服务器。对于不确定性高的token,更倾向于卸载,以获得更高的精度;对于不确定性低的token,则在本地执行推理,以减少延迟。这种token级别的细粒度控制,能够更好地适应不同的资源约束和用户需求。
技术框架:整体框架包含三个主要模块:1) 不确定性估计模块:计算每个token生成时的不确定性,使用基于margin的度量,即预测概率最高的token与第二高token之间的差值。2) 卸载决策模块:基于token的不确定性、设备资源状况和网络状况,使用贪婪卸载算法(GOA)决定是否卸载当前token的推理任务。3) 推理执行模块:根据卸载决策,在本地或边缘服务器上执行推理,并将结果返回给用户。
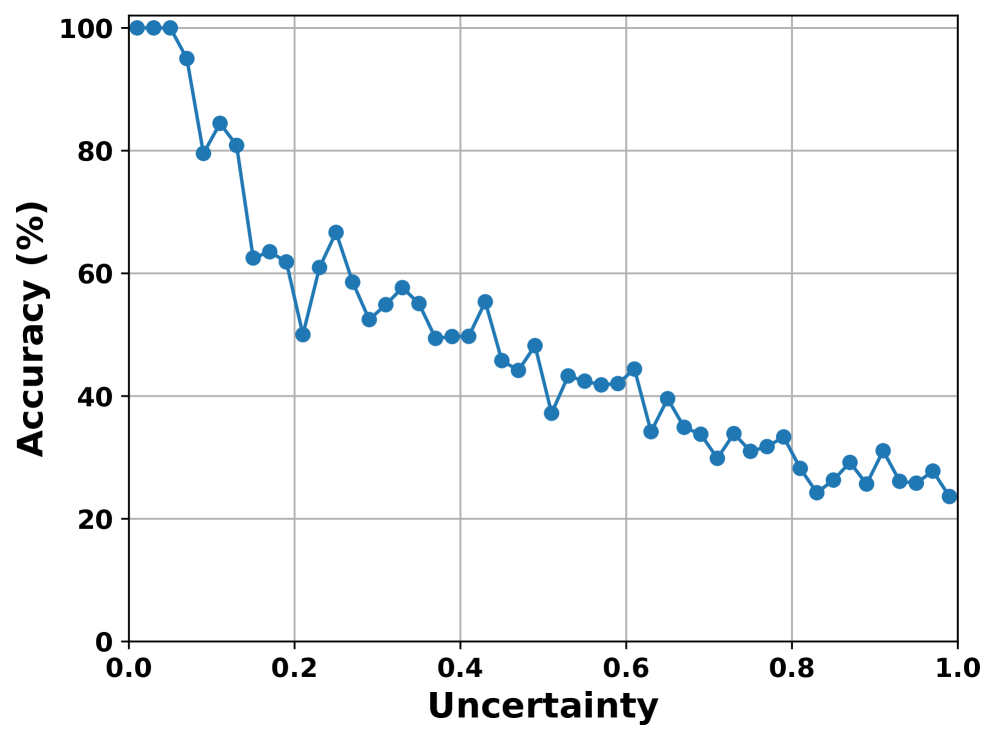
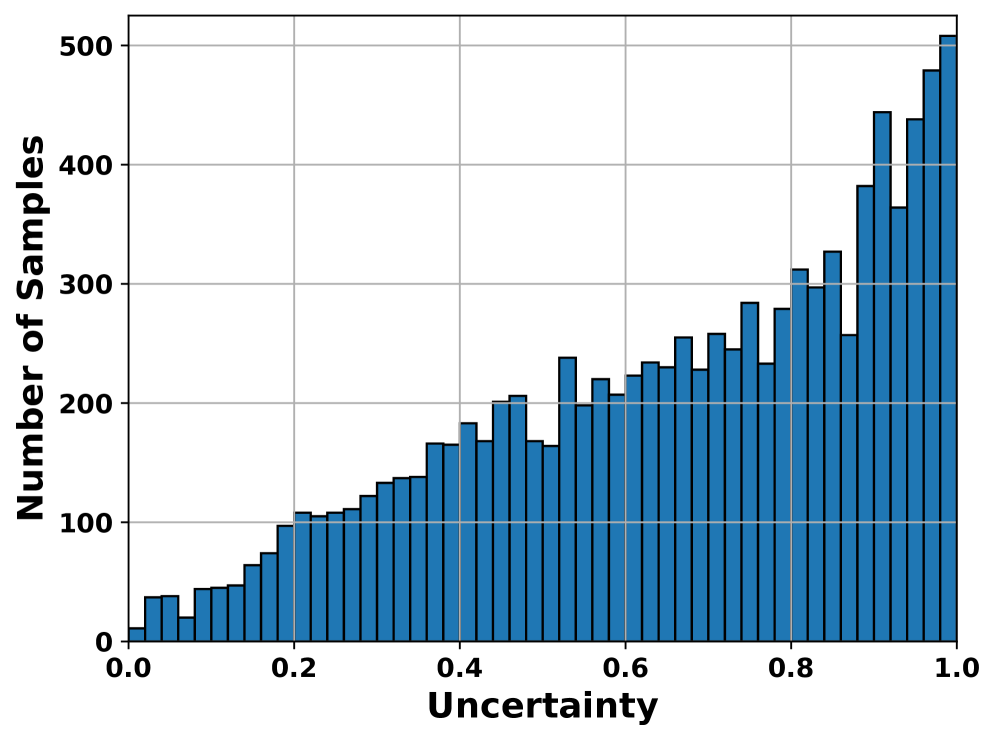
关键创新:论文最重要的技术创新点在于提出了基于token级别不确定性的动态卸载策略。与传统的静态卸载策略相比,该策略能够更精细地控制精度和延迟之间的权衡。此外,基于margin的不确定性度量简单有效,易于实现和部署。
关键设计:关键设计包括:1) 基于Margin的不确定性度量:使用预测概率最高的token与第二高token之间的差值作为不确定性度量,简单高效。2) 贪婪卸载算法(GOA):优先卸载不确定性高的token,以最大程度地提高精度,同时考虑延迟约束。GOA的具体实现细节(如阈值设置)未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的贪婪卸载算法(GOA)在不同用户密度下,均优于基线策略。具体而言,GOA在保证一定精度水平的前提下,显著降低了推理延迟。虽然摘要中没有给出具体的性能数据和提升幅度,但强调了GOA在精度和延迟之间实现了良好的权衡。
🎯 应用场景
该研究成果可应用于各种需要LLM推理的移动边缘计算场景,例如智能助手、实时翻译、智能客服等。通过动态卸载策略,可以在保证服务质量的同时,降低设备功耗和网络负载,提升用户体验。未来,该方法可以进一步扩展到其他类型的AI模型和边缘计算平台。
📄 摘要(原文)
Large language models (LLMs) offer significant potential for intelligent mobile services but are computationally intensive for resource-constrained devices. Mobile edge computing (MEC) allows such devices to offload inference tasks to edge servers (ESs), yet introduces latency due to communication and serverside queuing, especially in multi-user environments. In this work, we propose an uncertainty-aware offloading framework that dynamically decides whether to perform inference locally or offload it to the ES, based on token-level uncertainty and resource constraints. We define a margin-based token-level uncertainty metric and demonstrate its correlation with model accuracy. Leveraging this metric, we design a greedy offloading algorithm (GOA) that minimizes delay while maintaining accuracy by prioritizing offloading for highuncertainty queries. Our experiments show that GOA consistently achieves a favorable trade-off, outperforming baseline strategies in both accuracy and latency across varying user densities, and operates with practical computation time. These results establish GOA as a scalable and effective solution for LLM inference in MEC environments.