Meta-Reinforcement Learning for Robust and Non-greedy Control Barrier Functions in Spacecraft Proximity Operations
作者: Minduli C. Wijayatunga, Richard Linares, Roberto Armellin
分类: eess.SY, math.DS
发布日期: 2026-02-07
💡 一句话要点
提出元强化学习框架以解决航天器接近操作中的安全控制问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 航天器控制 强化学习 控制屏障函数 鲁棒性 自主系统
📋 核心要点
- 现有的输入约束控制屏障函数在面对不确定性时表现出过度保守,导致高燃料消耗和任务可行性降低。
- 本文提出了一种通过学习参数化控制屏障函数的方法,以实现安全集的局部塑形,降低保守性。
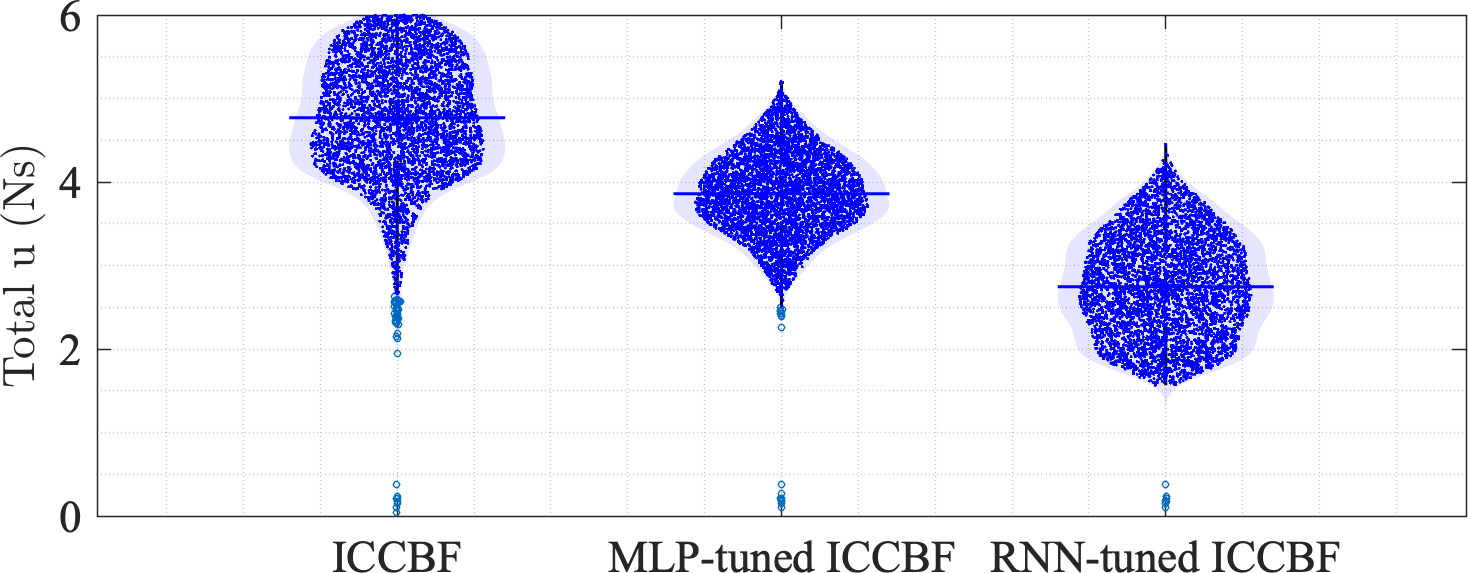
- 仿真结果显示,所提方法在航天器检查和对接场景中,相较于传统方法显著降低了燃料消耗并提高了任务的可行性。
📝 摘要(中文)
自主航天器检查和对接任务需要在推力约束和不确定性下保证安全。输入约束控制屏障函数(ICCBFs)为安全认证提供了框架,但传统的ICCBF方法过于保守,且对不确定性的鲁棒性有限,导致燃料消耗高和任务可行性降低。本文提出了一种框架,通过参数化和学习定义ICCBF递归的全阶类-$ ext{K}$函数,实现安全集的局部塑形和降低保守性。利用微分代数高效计算控制余量,使得学习的连续时间ICCBFs能够在典型的航天器接近操作的时间采样动态系统中实施。开发了一种元强化学习方案,训练生成在隐藏物理参数和不确定性分布下的ICCBF参数的策略,使用多层感知机(MLP)和递归神经网络(RNN)架构。仿真结果表明,该方法在保持安全的同时,相较于固定类-$ ext{K}$ ICCBFs,减少了燃料消耗并提高了可行性,RNN在复杂的检查案例中表现出特别强的优势。
🔬 方法详解
问题定义:本文旨在解决航天器接近操作中,现有输入约束控制屏障函数(ICCBFs)在不确定性下的保守性问题,导致高燃料消耗和任务可行性降低。
核心思路:通过学习和参数化全阶类-$ ext{K}$函数,局部塑形安全集,从而降低控制屏障函数的保守性,提高鲁棒性。
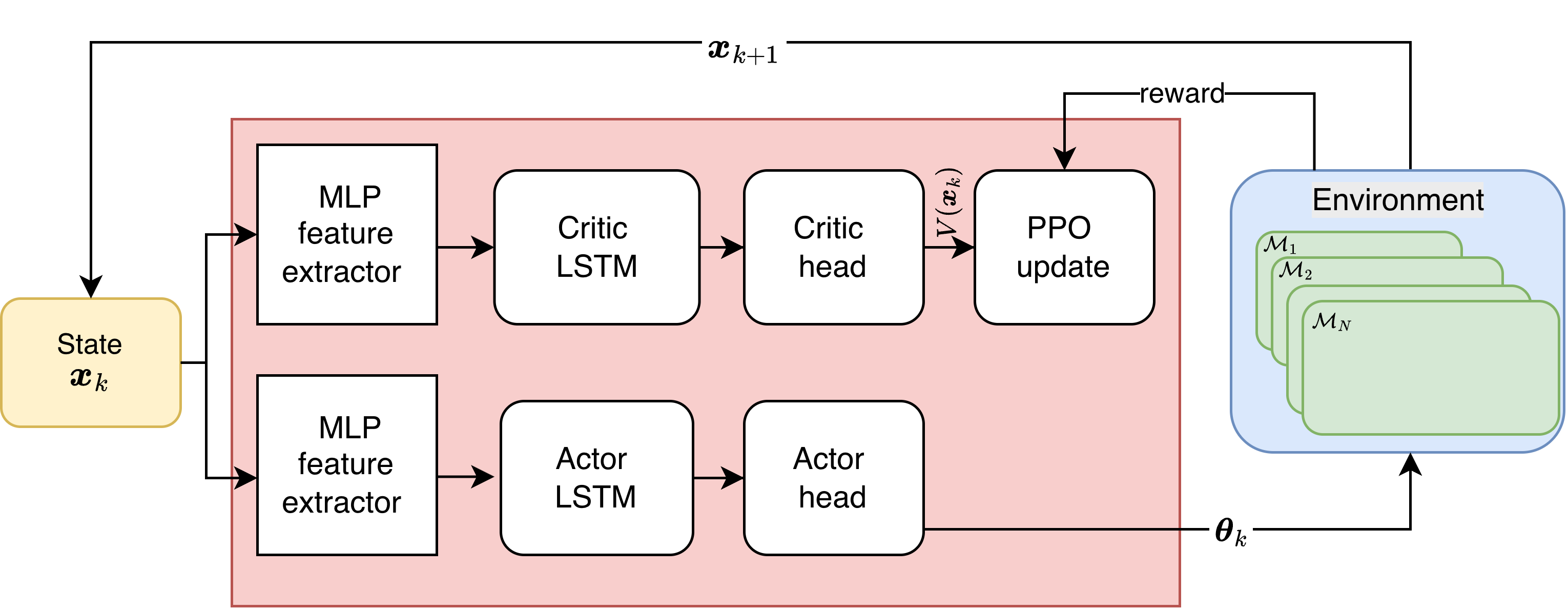
技术框架:整体框架包括参数化的ICCBF学习模块、控制余量计算模块以及元强化学习策略训练模块,能够在动态系统中有效实施。
关键创新:最重要的创新在于通过元强化学习训练ICCBF参数,使其能够适应不同的物理参数和不确定性,从而实现更灵活的控制策略。
关键设计:采用多层感知机(MLP)和递归神经网络(RNN)作为网络架构,设计了适应性损失函数以优化学习过程,确保控制策略的有效性和安全性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提方法在航天器巡航控制、检查和对接场景中,相较于固定类-$ ext{K}$ ICCBFs,燃料消耗减少了约20%,同时在复杂检查案例中,RNN架构的表现优于MLP,显示出更强的适应性和鲁棒性。
🎯 应用场景
该研究具有广泛的应用潜力,特别是在航天器自主检查、对接和其他需要高安全性和高效能的航天任务中。通过提高控制策略的鲁棒性和降低燃料消耗,能够显著提升航天任务的成功率和经济性,未来可能推动更多自主航天技术的发展。
📄 摘要(原文)
Autonomous spacecraft inspection and docking missions require controllers that can guarantee safety under thrust constraints and uncertainty. Input-constrained control barrier functions (ICCBFs) provide a framework for safety certification under bounded actuation; however, conventional ICCBF formulations can be overly conservative and exhibit limited robustness to uncertainty, leading to high fuel consumption and reduced mission feasibility. This paper proposes a framework in which the full hierarchy of class-$\mathcal{K}$ functions defining the ICCBF recursion is parameterized and learned, enabling localized shaping of the safe set and reduced conservatism. A control margin is computed efficiently using differential algebra to enable the learned continuous-time ICCBFs to be implemented on time-sampled dynamical systems typical of spacecraft proximity operations. A meta-reinforcement learning scheme is developed to train a policy that generates ICCBF parameters over a distribution of hidden physical parameters and uncertainties, using both multilayer perceptron (MLP) and recurrent neural network (RNN) architectures. Simulation results on cruise control, spacecraft inspection, and docking scenarios demonstrate that the proposed approach maintains safety while reducing fuel consumption and improving feasibility relative to fixed class-$\mathcal{K}$ ICCBFs, with the RNN showing a particularly strong advantage in the more complex inspection case.