UAV Trajectory Optimization via Improved Noisy Deep Q-Network
作者: Zhang Hengyu, Maryam Cheraghy, Liu Wei, Armin Farhadi, Meysam Soltanpour, Zhong Zhuoqing
分类: eess.SY, cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出改进型Noisy DQN,提升无人机在仿真环境中的探索能力与训练稳定性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无人机轨迹优化 深度强化学习 Noisy DQN 探索策略 自适应噪声 残差网络 仿真环境
📋 核心要点
- 现有深度强化学习方法在无人机轨迹优化中存在探索不足和训练不稳定的问题,限制了其应用效果。
- 本文提出改进的Noisy DQN,通过引入残差NoisyLinear层和自适应噪声调度机制,增强探索能力。
- 实验表明,改进模型收敛速度更快,奖励更高,且能更快达到任务所需的最少步数,验证了其有效性。
📝 摘要(中文)
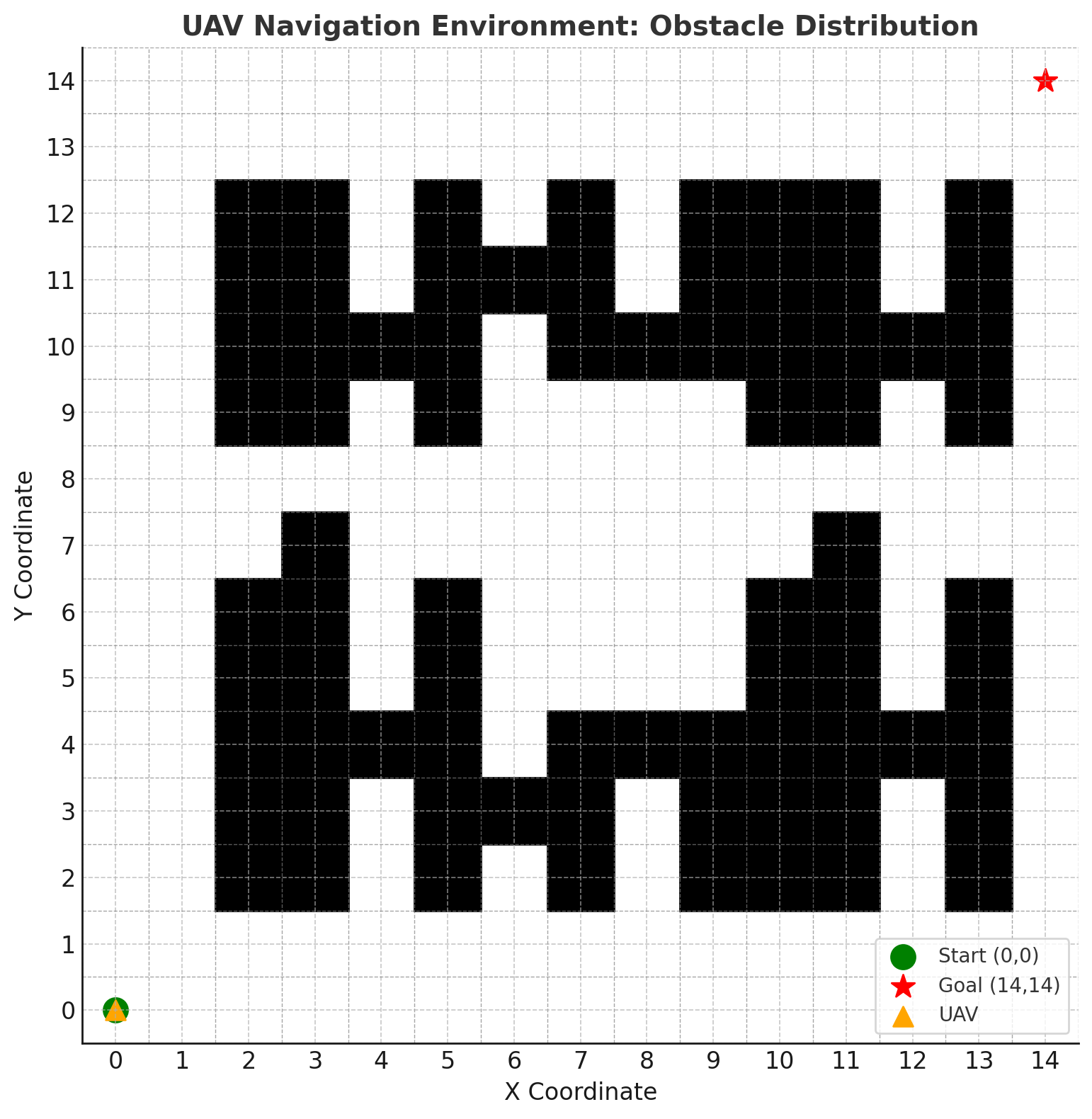
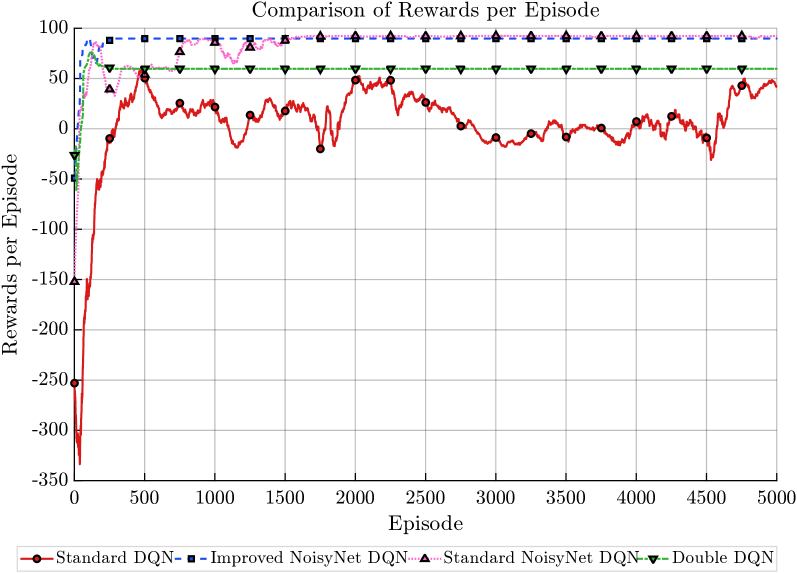
本文提出了一种改进的Noisy Deep Q-Network (Noisy DQN),旨在增强无人机在仿真环境中应用深度强化学习时的探索能力和稳定性。该方法通过结合残差NoisyLinear层与自适应噪声调度机制来增强探索能力,同时通过平滑损失和软目标网络更新来提高训练稳定性。实验结果表明,与标准DQN相比,所提出的模型收敛速度更快,奖励提高了高达+40,并且在设定的15*15网格导航环境中,能够快速达到任务所需的最小步数28。结果表明,我们对NoisyNet网络结构、探索控制和训练稳定性的全面改进有助于提高深度Q学习的效率和可靠性。
🔬 方法详解
问题定义:无人机轨迹优化问题旨在寻找一条最优路径,使无人机在满足特定约束条件下,高效、安全地到达目标位置。现有基于深度强化学习的方法,如标准DQN,在复杂环境中容易陷入局部最优,探索效率低,且训练过程不稳定,难以收敛到理想策略。
核心思路:本文的核心思路是通过改进Noisy DQN,增强其探索能力和训练稳定性。Noisy DQN通过在网络中引入噪声层来鼓励探索,但原始的噪声添加方式可能不够有效。本文进一步改进,使其能够更好地适应环境变化,同时采用平滑损失和软目标网络更新来稳定训练过程。
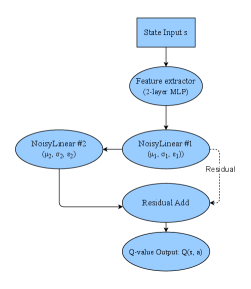
技术框架:整体框架基于深度强化学习,使用改进的Noisy DQN作为智能体。主要流程包括:1) 环境状态输入;2) Noisy DQN输出动作价值估计;3) 根据价值估计选择动作;4) 环境反馈奖励和下一个状态;5) 使用经验回放和目标网络更新Q网络参数。关键在于Noisy DQN的结构改进和训练策略的优化。
关键创新:最重要的技术创新点在于对NoisyNet的改进,具体体现在两个方面:一是引入残差NoisyLinear层,增强网络的表达能力;二是采用自适应噪声调度机制,根据训练进度动态调整噪声水平,平衡探索与利用。与原始NoisyNet相比,改进后的网络能够更有效地进行探索,并更快地学习到最优策略。
关键设计:关键设计包括:1) 残差NoisyLinear层:在NoisyLinear层的基础上添加残差连接,允许网络学习更复杂的函数关系;2) 自适应噪声调度:根据训练的episode数或reward变化动态调整噪声的方差,例如,在训练初期使用较大的噪声方差以鼓励探索,在训练后期逐渐减小噪声方差以提高策略的精度;3) 平滑损失函数:使用Huber loss等平滑损失函数代替均方误差损失,减少异常值对训练的影响;4) 软目标网络更新:采用 Polyak averaging 的方式更新目标网络参数,提高训练稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,改进的Noisy DQN在15*15网格导航环境中,与标准DQN相比,收敛速度更快,奖励提高了高达+40。此外,改进模型能够快速达到任务所需的最小步数28,表明其具有更强的探索能力和更高的学习效率。这些结果验证了本文提出的改进策略的有效性。
🎯 应用场景
该研究成果可应用于多种无人机任务,如自主导航、目标搜索、环境监测和物流配送等。通过提高无人机的自主性和适应性,可以降低人工干预的需求,提高任务效率和安全性。未来,该方法有望扩展到更复杂的无人机应用场景,例如协同飞行和集群控制。
📄 摘要(原文)
This paper proposes an Improved Noisy Deep Q-Network (Noisy DQN) to enhance the exploration and stability of Unmanned Aerial Vehicle (UAV) when applying deep reinforcement learning in simulated environments. This method enhances the exploration ability by combining the residual NoisyLinear layer with an adaptive noise scheduling mechanism, while improving training stability through smooth loss and soft target network updates. Experiments show that the proposed model achieves faster convergence and up to $+40$ higher rewards compared to standard DQN and quickly reach to the minimum number of steps required for the task 28 in the 15 * 15 grid navigation environment set up. The results show that our comprehensive improvements to the network structure of NoisyNet, exploration control, and training stability contribute to enhancing the efficiency and reliability of deep Q-learning.