Lyapunov Constrained Soft Actor-Critic (LC-SAC) using Koopman Operator Theory for Quadrotor Trajectory Tracking
作者: Dhruv S. Kushwaha, Zoleikha A. Biron
分类: eess.SY, cs.LG, cs.RO
发布日期: 2026-02-04
备注: 12 pages, 7 Figures, submitted to IEEE RA-L
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于Koopman算子理论的Lyapunov约束软演员-评论家算法(LC-SAC),用于四旋翼飞行器轨迹跟踪。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Lyapunov稳定性 Koopman算子 软演员-评论家算法 四旋翼飞行器 轨迹跟踪 安全控制 扩展动态模式分解
📋 核心要点
- 传统强化学习在安全关键系统中应用受限,缺乏稳定性保证,易导致系统状态发散。
- 利用Koopman算子理论,通过EDMD方法线性近似系统,推导闭式解的Lyapunov函数,并将其融入SAC算法。
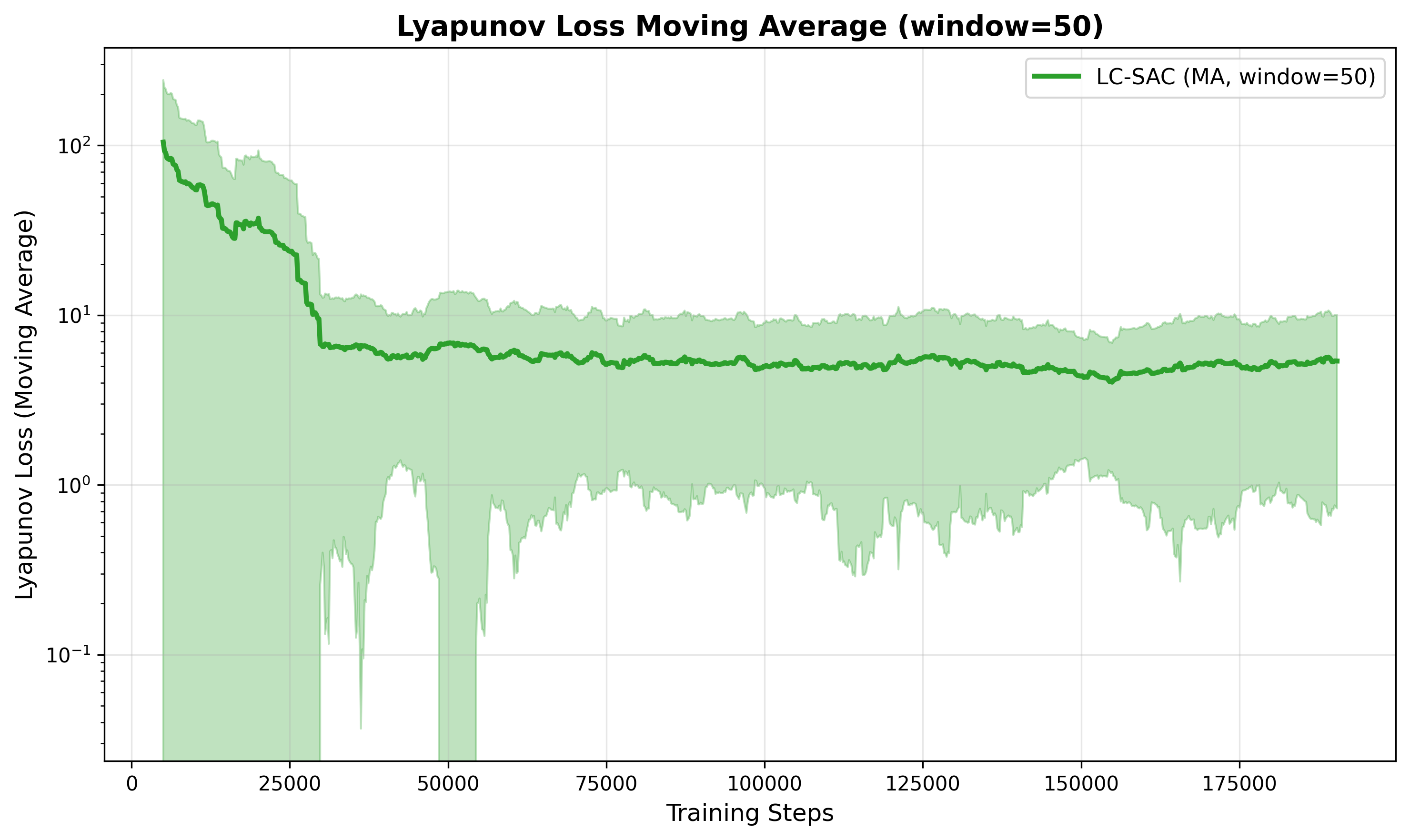
- 实验表明,提出的LC-SAC算法在四旋翼轨迹跟踪任务中,相较于SAC算法,能保证训练收敛和Lyapunov稳定性。
📝 摘要(中文)
强化学习(RL)在解决复杂的序列决策问题上取得了显著成功。然而,由于缺乏稳定性保证,其在安全攸关的物理系统中的应用仍然受到限制。标准的RL算法优先考虑奖励最大化,通常会产生可能导致振荡或无界状态发散的策略。目前已经有大量工作将基于Lyapunov的稳定性保证纳入RL算法中,但主要挑战在于选择候选Lyapunov函数,使用过多的函数逼近器导致计算复杂性,以及通过在学习过程中加入稳定性准则而产生保守策略。本文提出了一种新的基于Koopman算子理论的Lyapunov约束软演员-评论家(LC-SAC)算法。我们建议使用扩展动态模式分解(EDMD)来产生系统的线性近似,并使用该近似来推导候选Lyapunov函数的闭式解。该Lyapunov函数被纳入SAC算法中,以进一步保证策略能够稳定非线性系统。结果基于safe-control-gym中的2D四旋翼环境的轨迹跟踪进行评估。与基线vanilla SAC算法相比,所提出的算法显示出训练收敛和Lyapunov稳定性准则的违规衰减。
🔬 方法详解
问题定义:论文旨在解决强化学习在安全关键系统中应用时,缺乏稳定性保证的问题。现有方法通常依赖于奖励最大化,可能导致系统状态不稳定。将Lyapunov稳定性理论融入强化学习算法面临着选择合适的Lyapunov函数、计算复杂度高以及策略保守等挑战。
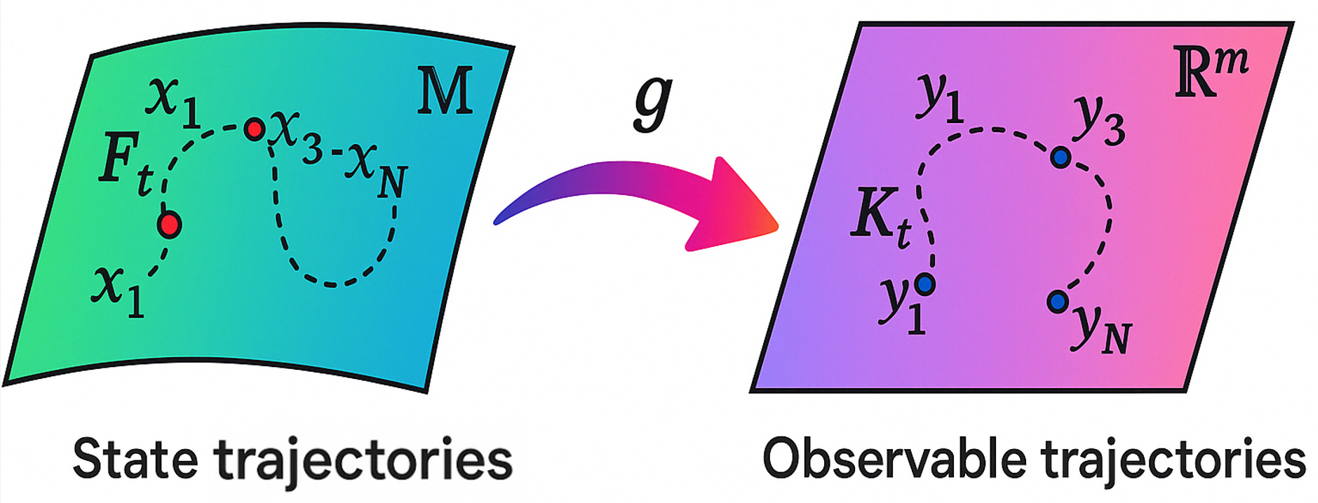
核心思路:论文的核心思路是利用Koopman算子理论,通过扩展动态模式分解(EDMD)方法对非线性系统进行线性近似,从而推导出候选Lyapunov函数的闭式解。该Lyapunov函数随后被整合到软演员-评论家(SAC)算法中,以约束策略的学习过程,确保策略的稳定性。
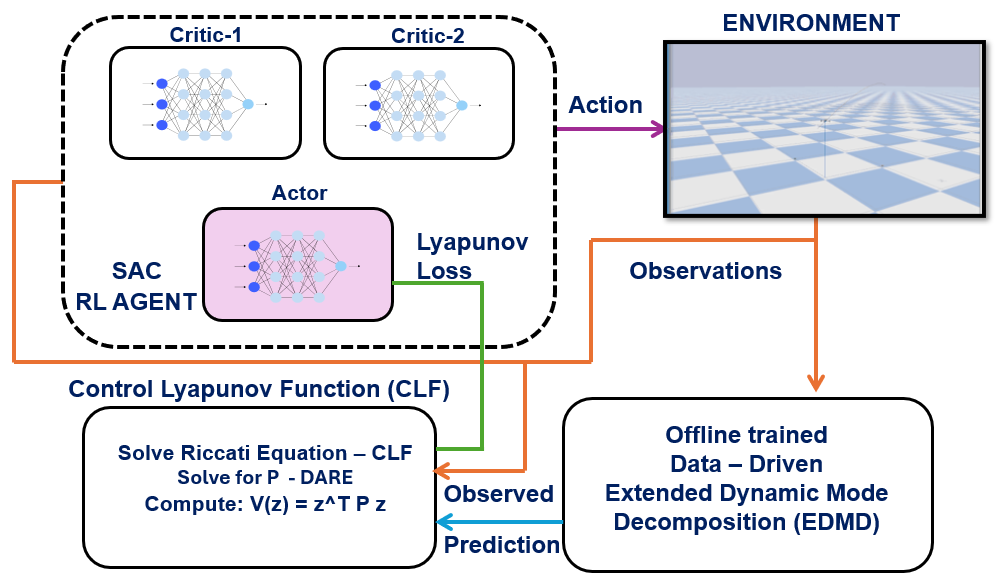
技术框架:整体框架包括以下几个主要模块:1) 使用EDMD方法对非线性系统进行线性近似;2) 基于线性近似结果,推导候选Lyapunov函数的闭式解;3) 将Lyapunov函数作为约束条件,整合到SAC算法的损失函数中;4) 使用SAC算法训练策略,同时满足奖励最大化和Lyapunov稳定性约束。
关键创新:最重要的技术创新点在于利用Koopman算子理论和EDMD方法,为非线性系统提供了一种有效的Lyapunov函数构造方法。与传统方法相比,该方法避免了手动选择Lyapunov函数的困难,并降低了计算复杂度。此外,将Lyapunov函数作为约束条件融入SAC算法,能够在保证策略性能的同时,确保系统的稳定性。
关键设计:论文的关键设计包括:1) 使用EDMD方法进行系统线性近似的具体实现细节,包括选择合适的观测函数;2) Lyapunov函数的具体形式及其在SAC算法损失函数中的权重;3) SAC算法中演员和评论家网络的结构和参数设置;4) 训练过程中的超参数设置,如学习率、折扣因子等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的LC-SAC算法在2D四旋翼轨迹跟踪任务中表现出色。与基线SAC算法相比,LC-SAC算法能够保证训练过程的收敛性,并显著降低Lyapunov稳定性准则的违规次数。这表明LC-SAC算法能够在保证策略性能的同时,有效地提高系统的稳定性。
🎯 应用场景
该研究成果可应用于各种安全关键的控制系统,例如无人机、机器人、自动驾驶汽车等。通过保证系统的稳定性,可以提高这些系统在复杂环境中的安全性和可靠性。此外,该方法还可以推广到其他强化学习算法中,为解决安全约束下的强化学习问题提供新的思路。
📄 摘要(原文)
Reinforcement Learning (RL) has achieved remarkable success in solving complex sequential decision-making problems. However, its application to safety-critical physical systems remains constrained by the lack of stability guarantees. Standard RL algorithms prioritize reward maximization, often yielding policies that may induce oscillations or unbounded state divergence. There has significant work in incorporating Lyapunov-based stability guarantees in RL algorithms with key challenges being selecting a candidate Lyapunov function, computational complexity by using excessive function approximators and conservative policies by incorporating stability criterion in the learning process. In this work we propose a novel Lyapunov-constrained Soft Actor-Critic (LC-SAC) algorithm using Koopman operator theory. We propose use of extended dynamic mode decomposition (EDMD) to produce a linear approximation of the system and use this approximation to derive a closed form solution for candidate Lyapunov function. This derived Lyapunov function is incorporated in the SAC algorithm to further provide guarantees for a policy that stabilizes the nonlinear system. The results are evaluated trajectory tracking of a 2D Quadrotor environment based on safe-control-gym. The proposed algorithm shows training convergence and decaying violations for Lyapunov stability criterion compared to baseline vanilla SAC algorithm. GitHub Repository: https://github.com/DhruvKushwaha/LC-SAC-Quadrotor-Trajectory-Tracking