BAP-SRL: Bayesian Adaptive Priority Safe Reinforcement Learning for Vehicle Motion Planning at Mixed Traffic Intersections
作者: Yuansheng Lian, Ke Zhang, Yaming Guo, Shen Li, Meng Li
分类: eess.SY
发布日期: 2026-01-29
💡 一句话要点
提出BAP-SRL,解决混合交通路口自动驾驶车辆运动规划中多源风险的动态优先级问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 贝叶斯推理 自动驾驶 运动规划 混合交通 约束优化 优先级排序
📋 核心要点
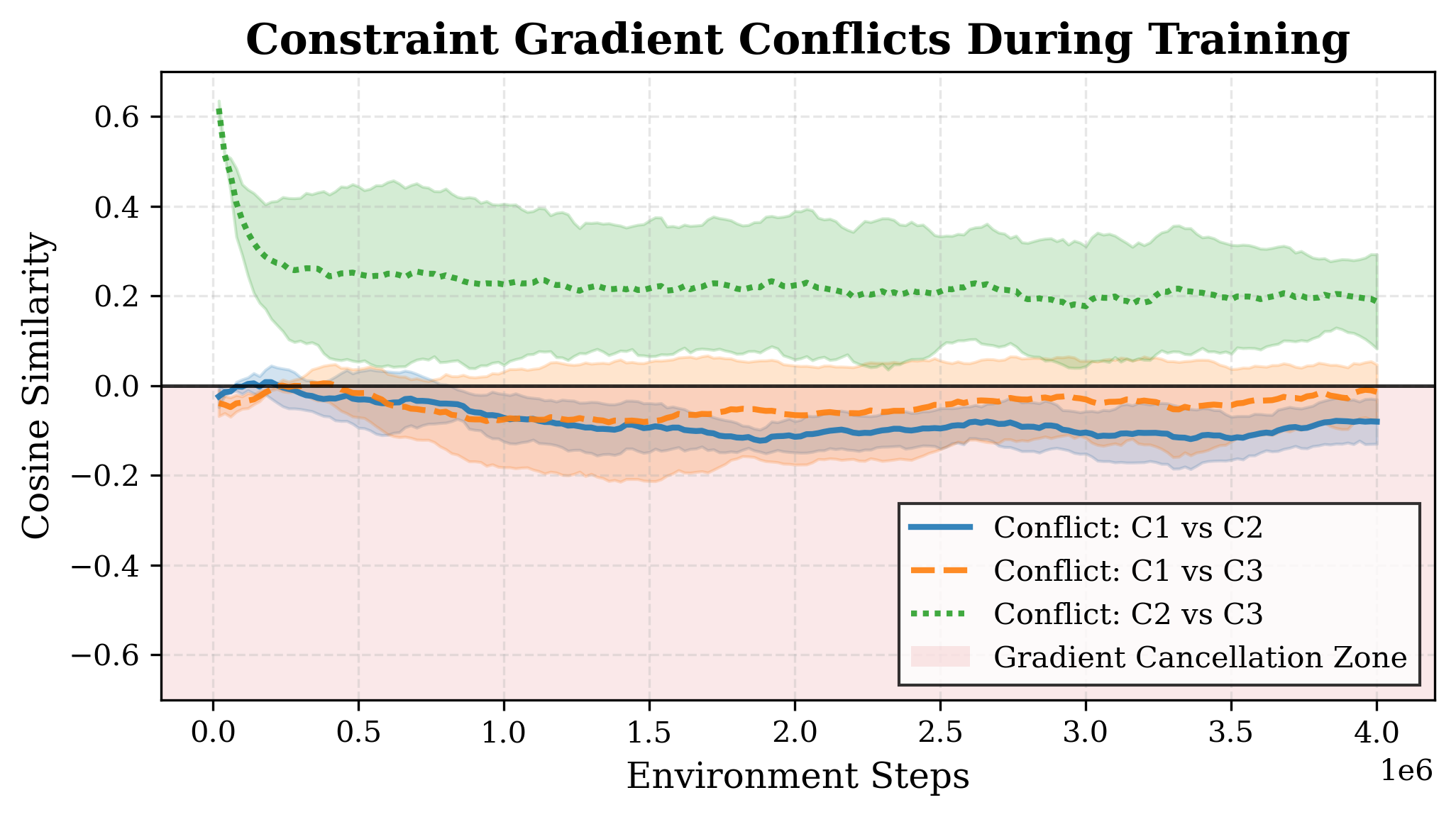
- 现有安全强化学习方法在处理混合交通路口的多源风险时,无法动态调整约束优先级,导致梯度抵消和次优决策。
- BAP-SRL将约束优先级建模为贝叶斯推理问题,利用历史优化难度和瞬时风险证据动态调整梯度更新,实现自适应的风险管理。
- 实验表明,BAP-SRL在混合交通环境中能够有效降低碰撞率,并实现更平滑的冲突解决,优于现有方法。
📝 摘要(中文)
本文提出了一种基于贝叶斯自适应优先级安全强化学习(BAP-SRL)的运动规划框架,旨在解决自动驾驶车辆在混合交通路口导航的难题。在这样的环境中,安全风险来自多个来源,每个来源具有不同的优先级和敏感性,需要差异化的保护偏好。现有安全强化学习方法通常将安全建模为单一约束或采用静态的启发式加权方案,无法解决多源风险的动态性,导致梯度抵消并阻碍学习,在关键的困境区域产生次优的权衡。BAP-SRL将约束优先级排序建模为一个概率推理任务,通过将历史优化难度建模为贝叶斯先验,将瞬时风险证据建模为似然,利用贝叶斯推理机制动态地门控梯度更新。实验结果表明,该方法在处理随机异构智能体的交互时,优于现有方法,实现了更低的碰撞率和更平滑的冲突解决。
🔬 方法详解
问题定义:论文旨在解决混合交通路口中自动驾驶车辆运动规划问题,尤其关注多源安全风险的动态优先级处理。现有方法,如单一约束或静态加权的安全强化学习,无法有效应对不同风险源的动态变化和重要性差异,导致梯度消失、学习效率低下以及在复杂场景下的次优决策。
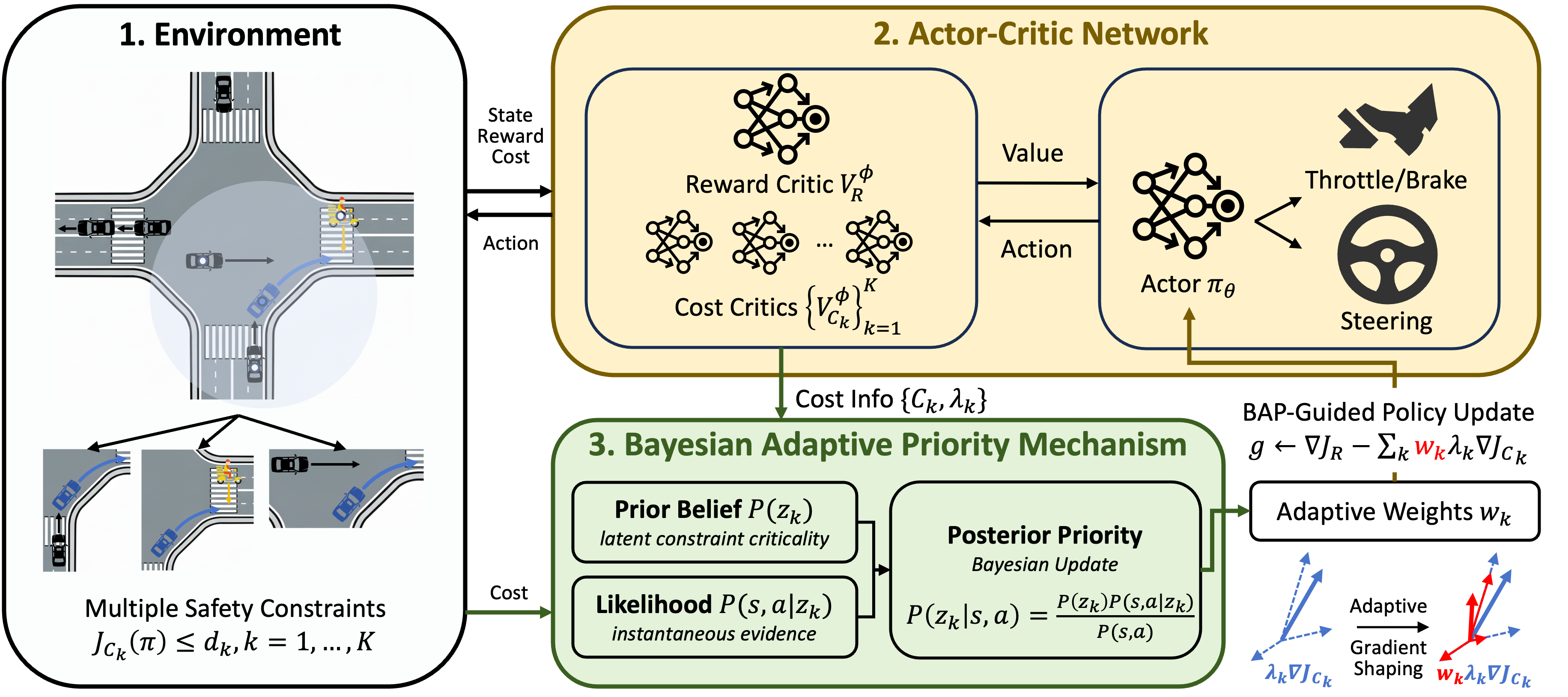
核心思路:论文的核心思路是将约束优先级建模为一个概率推理问题,利用贝叶斯方法动态地调整不同安全约束的权重。通过将历史优化难度作为先验知识,将当前时刻的风险证据作为似然函数,利用贝叶斯公式推断出每个约束的“关键性”,并以此指导梯度更新,从而实现对不同风险源的自适应管理。
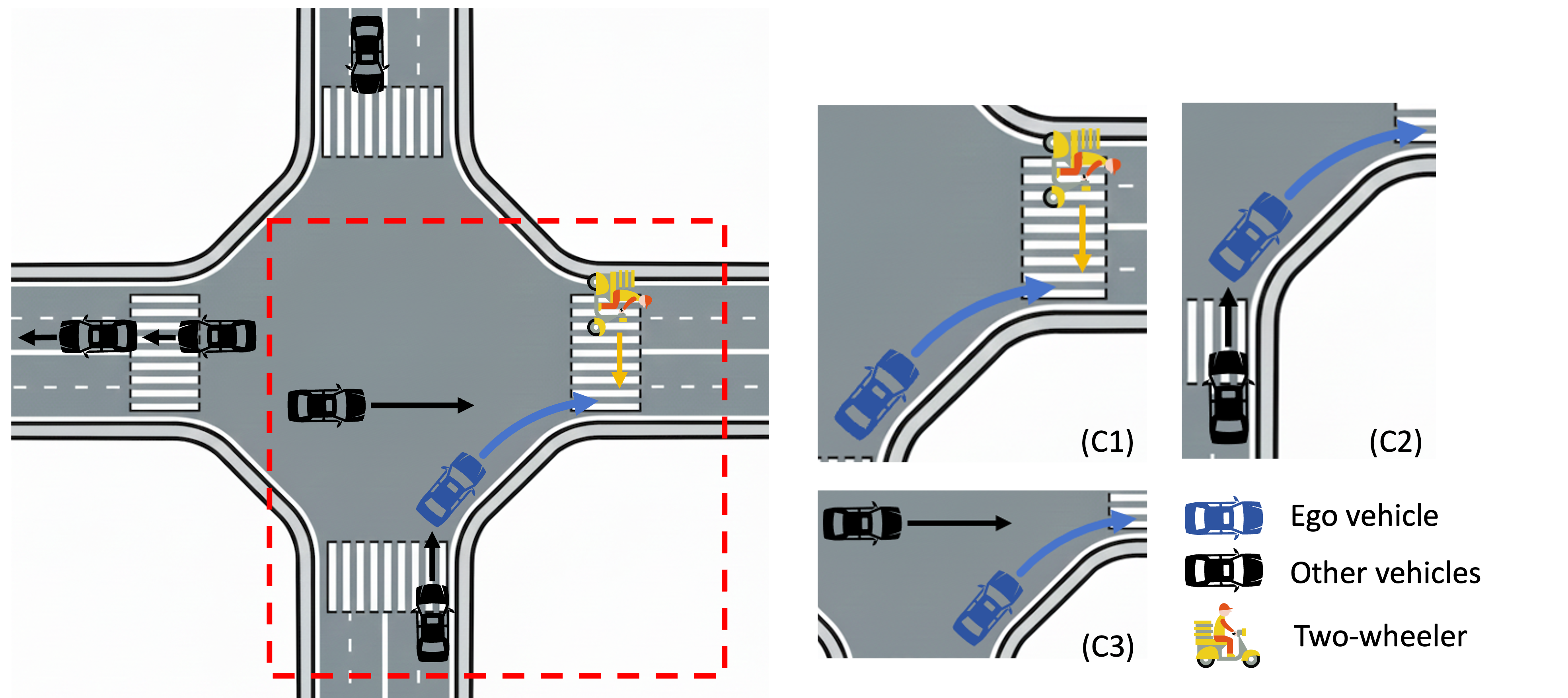
技术框架:BAP-SRL框架主要包含以下几个模块:1) 环境交互模块,负责与混合交通环境进行交互,获取状态信息和执行动作;2) 风险评估模块,评估来自不同来源的安全风险,例如与行人、车辆的碰撞风险;3) 贝叶斯优先级推理模块,基于历史优化难度和当前风险证据,利用贝叶斯公式计算每个约束的优先级;4) 安全强化学习模块,利用优先级信息调整梯度更新,学习安全且高效的运动策略。
关键创新:论文的关键创新在于将贝叶斯推理引入到安全强化学习的约束优先级管理中。与传统的启发式加权方法相比,BAP-SRL能够根据环境的动态变化和历史学习经验,自适应地调整约束的权重,从而更有效地平衡安全性和性能。这种方法能够更好地应对多源风险的复杂场景,避免梯度抵消,提高学习效率。
关键设计:BAP-SRL的关键设计包括:1) 使用贝叶斯模型对约束优先级进行建模,其中先验分布可以是均匀分布或基于历史数据的经验分布;2) 定义合适的似然函数,用于衡量当前时刻的风险证据,例如可以使用风险值或违反约束的程度;3) 设计合适的奖励函数,鼓励车辆安全、高效地通过路口;4) 选择合适的强化学习算法,例如Trust Region Policy Optimization (TRPO) 或 Proximal Policy Optimization (PPO),并结合优先级信息进行梯度更新。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BAP-SRL在混合交通环境中显著降低了碰撞率,并实现了更平滑的冲突解决。与state-of-the-art的基线方法相比,BAP-SRL在保证安全性的前提下,提高了车辆的通行效率和舒适性。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动驾驶车辆在复杂城市交通环境中的运动规划,尤其是在混合交通路口等高风险场景。通过动态调整安全约束的优先级,可以提高自动驾驶车辆的安全性和通行效率,减少交通事故的发生,并为未来智能交通系统的发展提供技术支持。
📄 摘要(原文)
Navigating urban intersections, especially when interacting with heterogeneous traffic participants, presents a formidable challenge for autonomous vehicles (AVs). In such environments, safety risks arise simultaneously from multiple sources, each carrying distinct priority levels and sensitivities that necessitate differential protection preferences. While safe reinforcement learning (RL) offers a robust paradigm for constrained decision-making, existing methods typically model safety as a single constraint or employ static, heuristic weighting schemes for multiple constraints. These approaches often fail to address the dynamic nature of multi-source risks, leading to gradient cancellation that hampers learning, and suboptimal trade-offs in critical dilemma zones. To address this, we propose a Bayesian adaptive priority safe reinforcement learning (BAP-SRL) based motion planning framework. Unlike heuristic weighting schemes, BAP formulates constraint prioritization as a probabilistic inference task. By modeling historical optimization difficulty as a Bayesian prior and instantaneous risk evidence as a likelihood, BAP dynamically gates gradient updates using a Bayesian inference mechanism on latent constraint criticality. Extensive experiments demonstrate that our approach outperforms state-of-the-art baselines in handling interactions with stochastic, heterogeneous agents, achieving lower collision rates and smoother conflict resolution.