Reinforcement Learning with Distributed MPC for Fuel-Efficient Platoon Control with Discrete Gear Transitions
作者: Samuel Mallick, Gianpietro Battocletti, Dimitris Boskos, Azita Dabiri, Bart De Schutter
分类: eess.SY
发布日期: 2026-01-26
备注: 16 pages, 8 figures, submitted to Transaction on IEEE Transactions on Intelligent Transportation Systems
💡 一句话要点
提出基于强化学习的分布式MPC方法,用于燃料效率优化的离散档位切换车队控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型预测控制 分布式控制 车队控制 燃油效率 自动驾驶 循环神经网络
📋 核心要点
- 传统MPC在车队控制中优化速度和档位,但同时优化连续动力学和离散档位计算成本高昂,难以实时实现。
- 提出基于强化学习的分布式MPC方法,学习档位选择策略,简化MPC的优化问题,降低计算复杂度。
- 通过参数化策略和RNN架构,降低训练成本,提高算法对大型车队和长预测范围的可扩展性,仿真结果表明计算负担显著降低。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的分布式模型预测控制(MPC)方法,旨在提高自动驾驶车队的燃油效率。该方法针对车队中每辆车训练一个策略,用于选择和固定局部MPC控制器预测窗口内的档位,从而将复杂的连续和离散混合优化问题简化为计算量更小的连续优化问题,并将其作为分布式MPC方案的一部分求解。为了降低训练的计算成本并促进所提出方法向大型车队的可扩展性,策略被参数化,使得涌现的多智能体RL问题可以解耦为单智能体学习任务。此外,针对档位选择策略提出了一种循环神经网络(RNN)架构,使得学习具有可扩展性,即使可能的换挡方案的数量随着MPC预测范围的增长呈指数增长。在高速公路驾驶模拟中,结果表明,与纯粹基于MPC的协同优化相比,所提出的方法具有显著更低的计算负担,并在燃油效率车队控制方面具有可比的性能。
🔬 方法详解
问题定义:现有基于MPC的车队控制方法在优化车辆速度的同时,还需要优化离散的档位切换,这导致计算复杂度非常高,难以满足实时性要求,尤其是在大型车队和较长的预测时域下。因此,需要一种计算效率更高的方法来实现燃油效率优化的车队控制。
核心思路:论文的核心思路是将档位选择问题交给强化学习来解决。通过训练一个策略网络,让每个车辆学习在MPC的预测时域内选择合适的档位序列。这样,MPC只需要优化连续的速度控制,而无需考虑离散的档位切换,从而大大降低了计算复杂度。
技术框架:该方法采用分布式MPC框架,车队中的每辆车都有一个局部的MPC控制器和一个强化学习策略网络。整体流程如下:1) 每辆车使用强化学习策略网络选择一个档位序列;2) 将该档位序列作为约束条件输入到局部的MPC控制器中;3) MPC控制器优化车辆的速度,并计算控制量;4) 将控制量作用于车辆,并更新车辆的状态;5) 根据车辆的状态和燃油消耗等信息,计算强化学习的奖励,并更新策略网络。
关键创新:该方法最重要的创新点在于将强化学习和分布式MPC相结合,利用强化学习来解决离散的档位选择问题,从而降低了MPC的计算复杂度。此外,为了提高算法的可扩展性,论文还提出了参数化的策略网络和RNN架构,使得算法可以应用于大型车队和较长的预测时域。
关键设计:论文使用RNN作为档位选择策略网络的结构,以处理时序信息。策略网络以车辆的状态(如速度、位置、加速度等)作为输入,输出预测时域内每个时刻的档位选择概率。损失函数的设计目标是最小化燃油消耗,同时考虑车辆的安全性和舒适性。为了降低训练成本,论文将多智能体强化学习问题解耦为单智能体学习任务,并使用经验回放等技术来提高训练效率。
🖼️ 关键图片
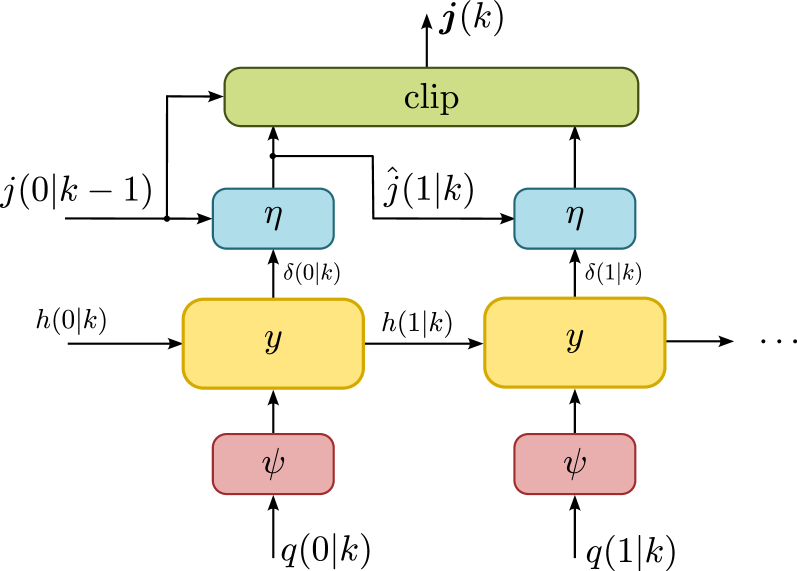
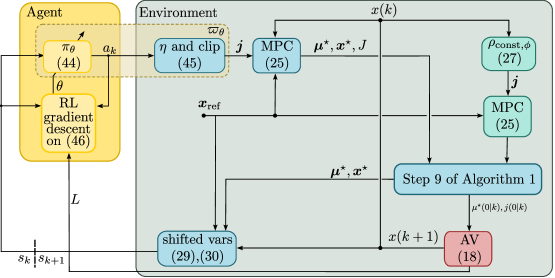
📊 实验亮点
在高速公路驾驶仿真中,该方法与纯MPC相比,显著降低了计算负担,同时保持了相当的燃油效率。具体来说,该方法在保证车队安全和行驶平稳性的前提下,能够实现与纯MPC相近的燃油经济性,但计算时间大幅缩短,更易于实时部署。这表明该方法在实际应用中具有很强的潜力。
🎯 应用场景
该研究成果可应用于自动驾驶车队管理、智能交通系统等领域,通过优化车辆的行驶策略,降低燃油消耗,减少排放,提高交通效率。尤其在物流运输、长途货运等场景下,具有显著的经济效益和环境效益。未来,该方法有望推广到更复杂的交通环境和更多类型的车辆。
📄 摘要(原文)
Cooperative control of groups of autonomous vehicles (AVs), i.e., platoons, is a promising direction to improving the efficiency of autonomous transportation systems. In this context, distributed co-optimization of both vehicle speed and gear position can offer benefits for fuel-efficient driving. To this end, model predictive control (MPC) is a popular approach, optimizing the speed and gear-shift schedule while explicitly considering the vehicles' dynamics over a prediction window. However, optimization over both the vehicles' continuous dynamics and discrete gear positions is computationally intensive, and may require overly long sample times or high-end hardware for real-time implementation. This work proposes a reinforcement learning (RL)-based distributed MPC approach to address this issue. For each vehicle in the platoon, a policy is trained to select and fix the gear positions across the prediction window of a local MPC controller, leaving a significantly simpler continuous optimization problem to be solved as part of a distributed MPC scheme. In order to reduce the computational cost of training and facilitate the scalability of the proposed approach to large platoons, the policies are parameterized such that the emergent multi-agent RL problem can be decoupled into single-agent learning tasks. In addition, a recurrent neural-network (RNN) architecture is proposed for the gear selection policy, such that the learning is scalable even as the number of possible gear-shift schedules grows exponentially with the MPC prediction horizon. In highway-driving simulations, the proposed approach is shown to have a significantly lower computation burden and a comparable performance in terms of fuel-efficient platoon control, with respect to pure MPC-based co-optimization.