Feedforward-Feedback Integration in Flight Control: Reinforcement Learning with Sliding Mode Control
作者: Imran Sayyed, Nandan Kumar Sinha
分类: eess.SY
发布日期: 2026-01-19
备注: 16 pages
💡 一句话要点
提出基于强化学习前馈与滑模控制反馈融合的飞行控制方法,提升性能并保证鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 滑模控制 飞行控制 鲁棒控制 学习增强控制
📋 核心要点
- 现有基于学习的控制器虽然能增强瞬态响应,但难以在严格输入约束下提供保证。
- 论文提出一种学习增强框架,利用深度强化学习生成前馈指令,滑模控制施加约束并保证鲁棒性。
- 实验表明,该混合控制器在六自由度飞行器模型上,提升了瞬态性能,并减少了控制振荡。
📝 摘要(中文)
本文提出了一种学习增强框架,该框架结合了深度强化学习策略生成的前馈指令和滑模控制(SMC)的反馈机制,以实现飞行控制。深度强化学习策略负责优化瞬态响应,而滑模控制负责施加执行器限制、约束学习策略的权限并保证鲁棒性。该策略被建模为匹配的有界输入,并基于李雅普诺夫条件将SMC增益与允许的前馈界限联系起来,从而保证饱和下的稳定性。该方法适用于具有硬约束的非线性欠驱动系统。以六自由度飞行器模型为例,将该方法与单独的强化学习和滑模控制进行了比较。仿真结果表明,混合控制器相比于单独的强化学习和滑模控制,改善了瞬态行为并减少了控制振荡,同时保持了建模不确定性和扰动下的鲁棒性。即使使用部分训练的策略,控制器的SMC部分也能稳定瞬态,而完全训练的策略提供更快的收敛速度、减少约束违反和增强鲁棒性。这些结果表明,学习增强控制在严格的输入约束下提供了卓越的性能和鲁棒性保证。
🔬 方法详解
问题定义:飞行控制面临的挑战是在满足严格的执行器限制下,实现快速、稳定的瞬态响应,并保证在模型不确定性和外部扰动下的鲁棒性。传统的强化学习方法虽然能够优化性能,但难以保证满足这些约束条件。单独的滑模控制虽然具有鲁棒性,但在性能上较为保守。
核心思路:论文的核心思路是将强化学习的前馈控制与滑模控制的反馈控制相结合。强化学习负责学习最优的控制策略,以实现快速的瞬态响应。滑模控制则负责施加执行器限制,约束强化学习策略的权限,并保证系统的鲁棒性。通过这种方式,可以兼顾性能和鲁棒性。
技术框架:整体框架包含两个主要模块:深度强化学习策略和滑模控制器。深度强化学习策略负责生成前馈控制指令,该指令被输入到飞行器模型中。滑模控制器则根据飞行器的状态和前馈指令,计算反馈控制信号,以保证系统的稳定性和满足约束条件。前馈和反馈控制信号最终叠加在一起,作为总的控制输入。
关键创新:该方法最重要的创新点在于将强化学习的前馈控制与滑模控制的反馈控制有机结合,并提出了基于李雅普诺夫理论的稳定性分析方法。通过该方法,可以保证在执行器饱和的情况下,系统的稳定性。此外,该方法还能够约束强化学习策略的权限,避免其产生不安全的控制指令。
关键设计:深度强化学习策略采用Actor-Critic结构,Actor网络负责生成控制指令,Critic网络负责评估控制指令的价值。滑模控制器的增益根据李雅普诺夫稳定性条件进行设计,以保证系统的稳定性。损失函数包括控制误差、控制输入和约束违反等项,用于训练深度强化学习策略。
🖼️ 关键图片
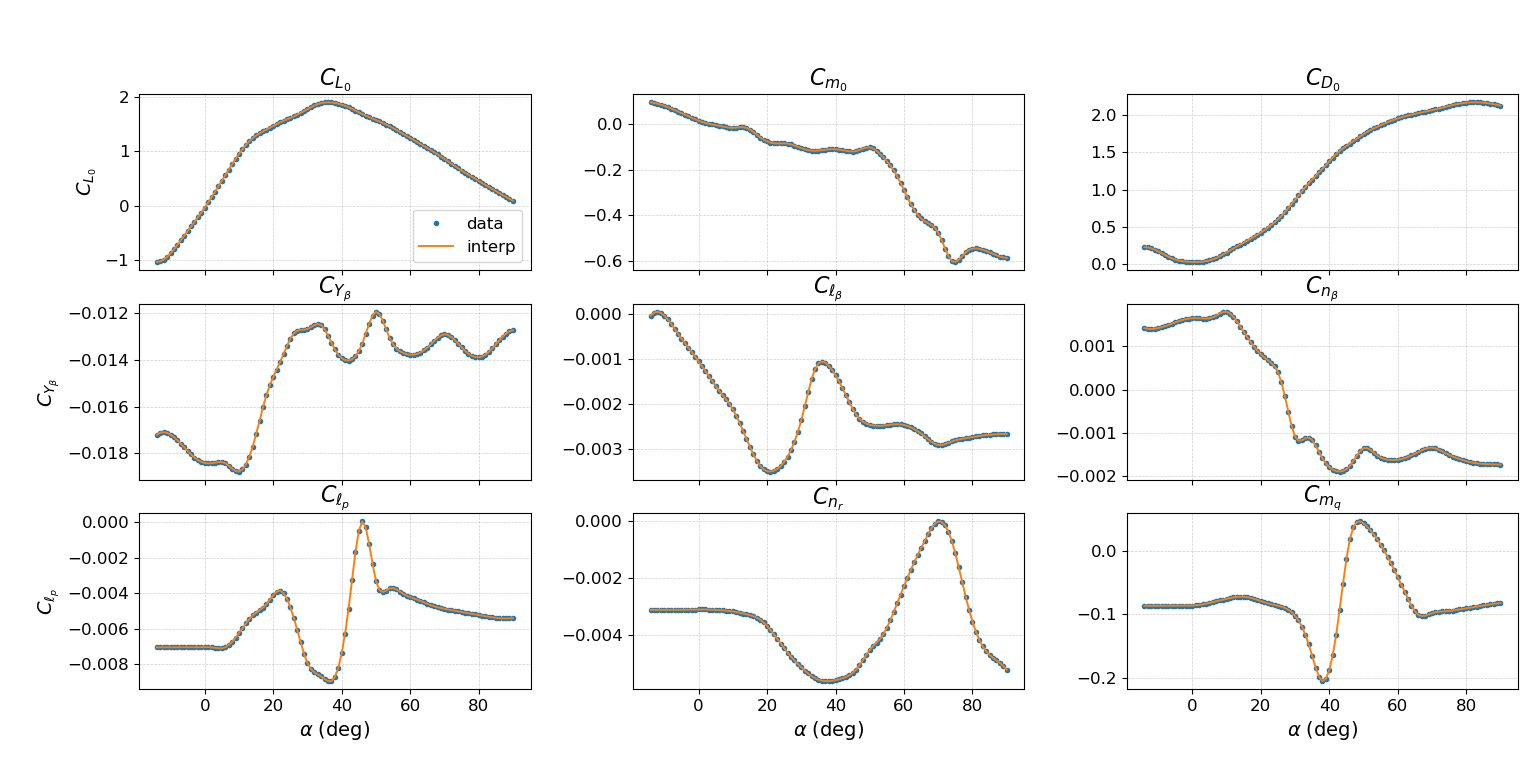
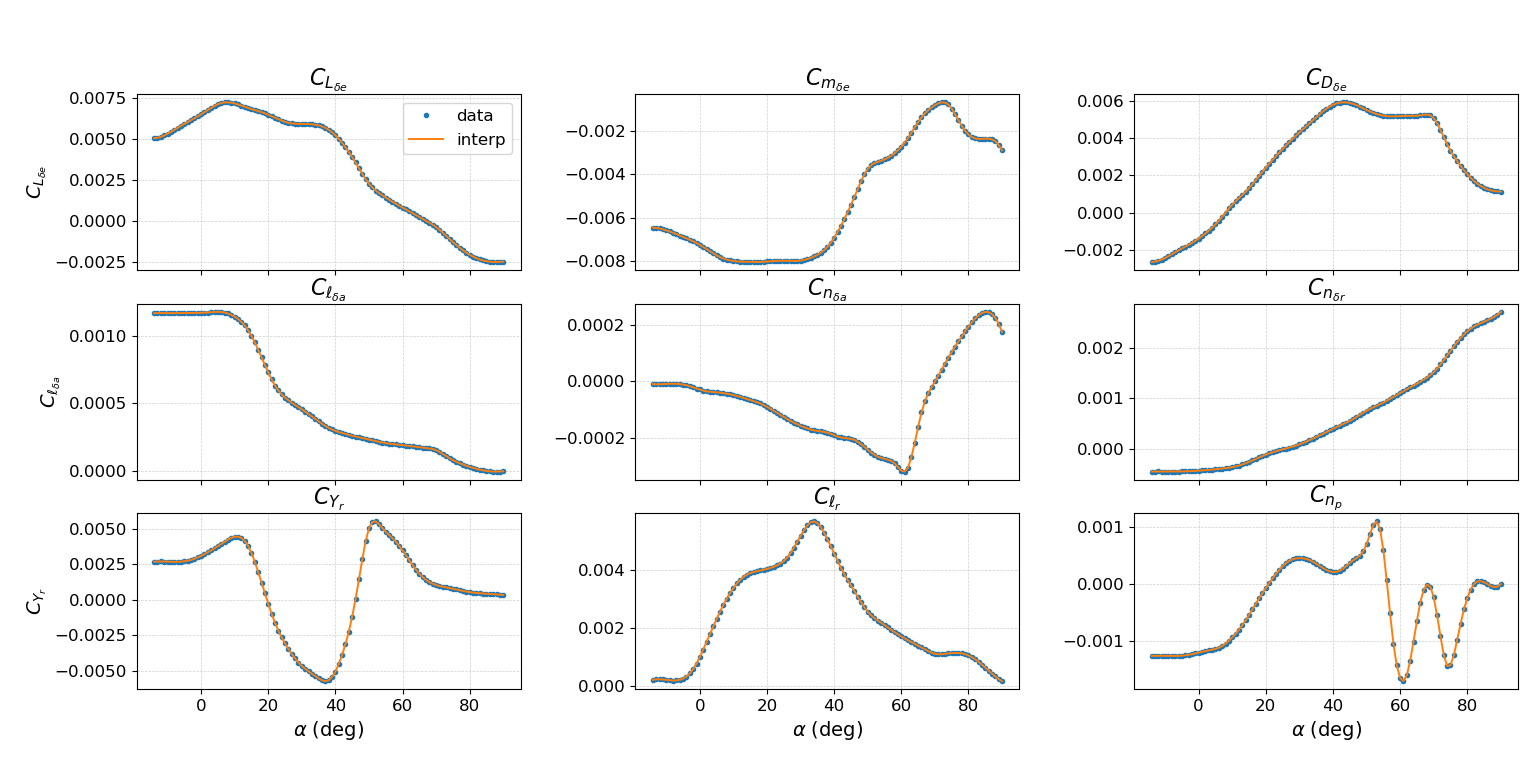

📊 实验亮点
实验结果表明,与单独的强化学习和滑模控制相比,该混合控制器在六自由度飞行器模型上,改善了瞬态行为并减少了控制振荡。具体而言,该混合控制器能够更快地收敛到目标状态,并减少控制输入的振荡幅度。此外,该混合控制器还能够保持在建模不确定性和扰动下的鲁棒性,即使使用部分训练的策略,也能保证系统的稳定性。
🎯 应用场景
该研究成果可应用于各种需要高性能和高可靠性的飞行控制系统,例如无人机、飞行机器人和航空航天飞行器。该方法能够提升飞行器的机动性和控制精度,同时保证飞行安全。此外,该方法还可以推广到其他具有约束的非线性控制系统,例如机器人控制和过程控制。
📄 摘要(原文)
Learning-based controllers leverage nonlinear couplings and enhance transients but seldom offer guarantees under tight input constraints. Robust feedback like sliding-mode control (SMC) provides these guarantees but is conservative in isolation. This paper creates a learning-augmented framework where a deep reinforcement learning policy produces feedforward commands and an SMC law imposes actuator limits, bounds learned authority, and guarantees robustness. The policy is modeled as a matched, bounded input, and Lyapunov-based conditions link SMC gains to the admissible feedforward bound, guaranteeing stability under saturation. This formulation is applicable to nonlinear, underactuated plants with hard constraints. To illustrate the methodology, the method is applied to a six-degree-of-freedom aircraft model and compared with Reinforcement Learning and isolated SMC. Simulation results show that the hybrid controller improves transient behavior and reduces control oscillations compared to standalone RL and SMC controllers, while preserving robustness under modeling uncertainties and disturbances. Even using it with partially trained policies, SMC component of the control stabilizes transients, whereas fully trained policies provide faster convergence, reduced constraint violations, and robustness. These results illustrate that learning-augmented control offers superior performance with robustness guarantees under tight input constraints.