Event-Driven Deep RL Dispatcher for Post-Storm Distribution System Restoration
作者: Farshad Amani, Faezeh Ardali, Amin Kargarian
分类: eess.SY
发布日期: 2026-01-15
💡 一句话要点
提出一种事件驱动的深度强化学习调度器,用于风暴后配电系统恢复。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 配电系统恢复 深度强化学习 事件驱动 实时调度 Actor-Critic 自然灾害 智能电网
📋 核心要点
- 现有配电系统恢复方法难以在自然灾害后快速响应不断变化的信息,需要重复进行恢复计划。
- 本文提出一种基于深度强化学习的调度器,利用Actor-Critic策略实时分配维修人员,优化恢复过程。
- 实验表明,该方法在模拟飓风和洪水场景中,能够有效减少未供电能量和关键负荷恢复时间。
📝 摘要(中文)
本文提出了一种深度强化学习(DRL)调度器,作为电力系统风暴后恢复的实时决策引擎,用于维修人员的任务分配。该方法将恢复过程建模为序贯的、信息逐步揭示的过程,并学习一个基于Actor-Critic的策略,该策略利用组件状态、旅行/维修时间、人员可用性和边际恢复价值等紧凑特征。可行性掩码用于阻止不安全或不可操作的动作,如潮流限制、开关规则和人员时间约束。为了提供逼真的运行时输入,使用轻量级代理模型模拟风和洪水强度、基于脆弱性的故障、空间损伤聚类、访问障碍和渐进式报修单到达。在模拟的飓风和洪水事件中,学习到的策略可以根据新的现场报告实时更新人员决策。由于运行时逻辑轻量化,与混合整数规划和标准启发式方法相比,该方法提高了在线性能(未供电能量、关键负荷恢复时间和行驶距离)。该方法在IEEE 13和123节点配电馈线上进行了混合飓风/洪水场景测试。
🔬 方法详解
问题定义:配电系统在遭受飓风、洪水等自然灾害后,设备受损,需要快速、有效地进行恢复。传统方法,如混合整数规划,计算复杂度高,难以满足实时性要求;启发式方法则可能陷入局部最优。因此,如何在信息不断更新的情况下,实时优化维修人员的调度,最小化损失,是一个关键问题。
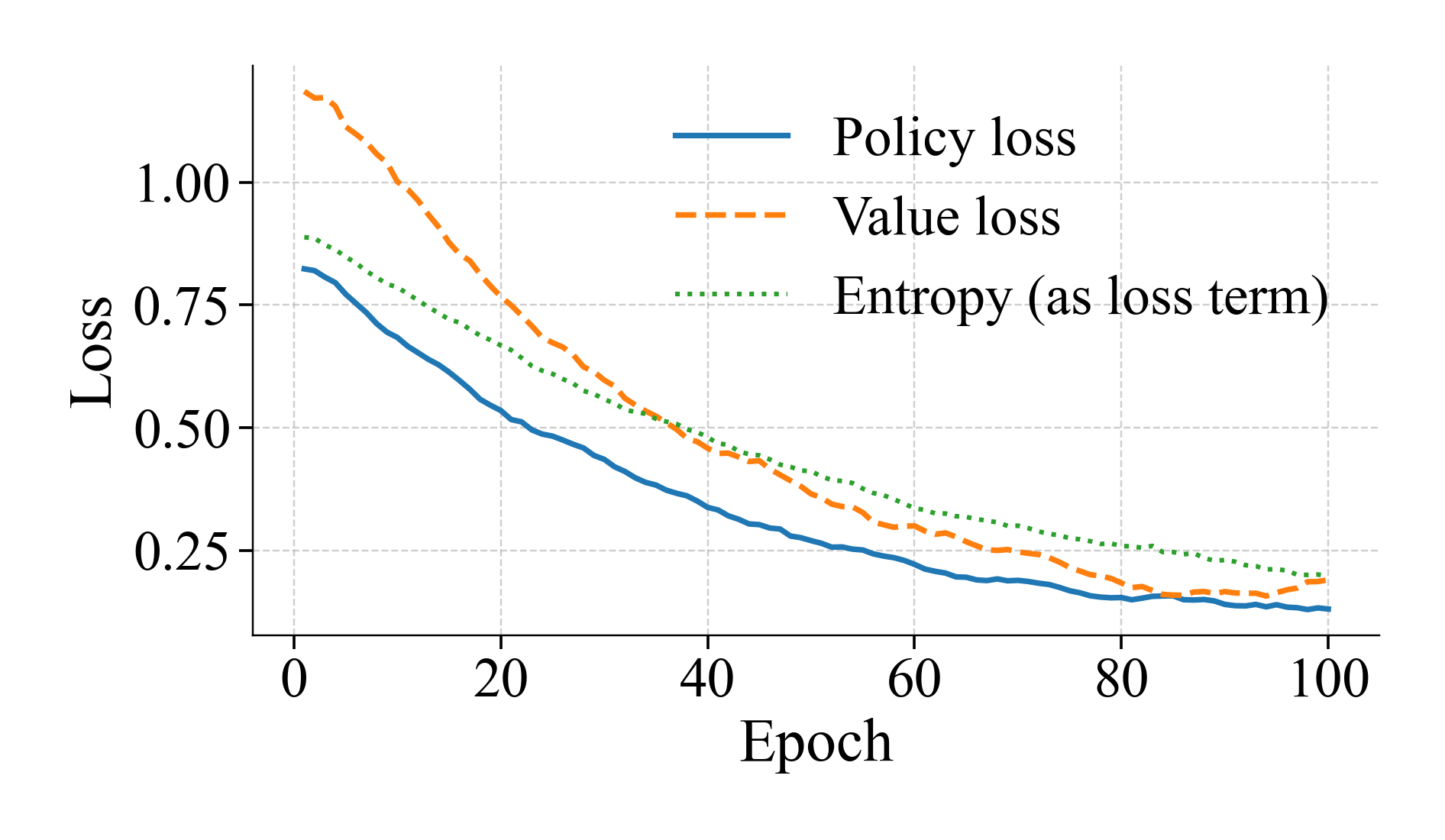
核心思路:本文的核心思路是将配电系统恢复问题建模为一个序贯决策过程,利用深度强化学习(DRL)学习一个最优的调度策略。通过Actor-Critic框架,Actor负责生成调度动作,Critic负责评估动作的价值,从而不断优化调度策略。这种方法能够适应动态变化的环境,并做出实时的决策。
技术框架:整体框架包含以下几个主要模块:1) 环境建模:模拟配电系统的状态,包括组件状态、维修时间、人员位置等;2) 状态表示:将环境状态转化为紧凑的特征向量,输入到DRL模型中;3) Actor-Critic网络:Actor网络负责生成调度动作,Critic网络负责评估动作的价值;4) 可行性掩码:用于过滤掉不安全或不可行的动作,保证调度的安全性;5) 奖励函数:用于指导DRL模型的学习,目标是最小化未供电能量和关键负荷恢复时间。
关键创新:该方法最重要的创新在于将深度强化学习应用于配电系统恢复的实时调度问题,并设计了轻量级的运行时逻辑,使其能够适应动态变化的环境。与传统的优化方法相比,该方法能够更快地做出决策,并取得更好的性能。此外,使用轻量级代理模型模拟灾害影响,避免了对重型求解器的依赖,提高了运行效率。
关键设计:在DRL模型中,使用了Actor-Critic框架,Actor网络和Critic网络都采用深度神经网络。状态表示包括组件状态、旅行/维修时间、人员可用性和边际恢复价值等特征。奖励函数的设计目标是最小化未供电能量和关键负荷恢复时间。可行性掩码用于保证调度的安全性,例如,避免潮流越限、违反开关规则等。
🖼️ 关键图片
📊 实验亮点
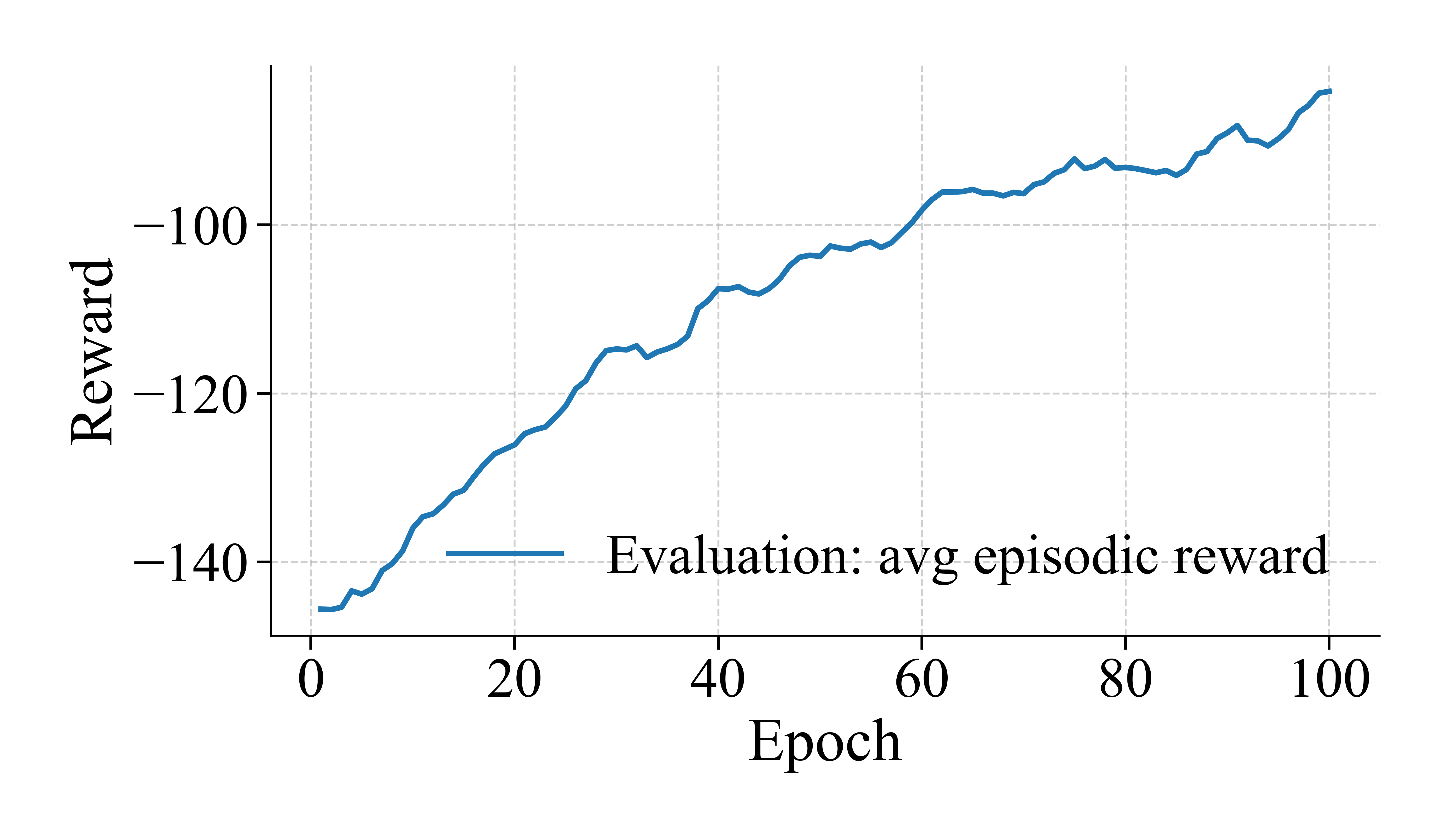
在IEEE 13和123节点配电馈线上进行的模拟实验表明,该方法在飓风和洪水场景下,能够实时更新人员决策,显著提高了在线性能。与混合整数规划和标准启发式方法相比,该方法能够有效减少未供电能量、关键负荷恢复时间和行驶距离,验证了其优越性。
🎯 应用场景
该研究成果可应用于电力公司配电系统的灾后恢复,为调度人员提供实时的决策支持,提高恢复效率,减少经济损失。此外,该方法还可以推广到其他类似的资源调度问题,例如交通拥堵管理、应急救援等领域,具有广泛的应用前景。
📄 摘要(原文)
Natural hazards such as hurricanes and floods damage power grid equipment, forcing operators to replan restoration repeatedly as new information becomes available. This paper develops a deep reinforcement learning (DRL) dispatcher that serves as a real-time decision engine for crew-to-repair assignments. We model restoration as a sequential, information-revealing process and learn an actor-critic policy over compact features such as component status, travel/repair times, crew availability, and marginal restoration value. A feasibility mask blocks unsafe or inoperable actions, such as power flow limits, switching rules, and crew-time constraints, before they are applied. To provide realistic runtime inputs without relying on heavy solvers, we use lightweight surrogates for wind and flood intensities, fragility-based failure, spatial clustering of damage, access impairments, and progressive ticket arrivals. In simulated hurricane and flood events, the learned policy updates crew decisions in real time as new field reports arrive. Because the runtime logic is lightweight, it improves online performance (energy-not-supplied, critical-load restoration time, and travel distance) compared with mixed-integer programs and standard heuristics. The proposed approach is tested on the IEEE 13- and 123-bus feeders with mixed hurricane/flood scenarios.