Optimal Regulation of Nonlinear Input-Affine Systems via an Integral Reinforcement Learning-Based State-Dependent Riccati Equation Approach
作者: Arya Rashidinejad Meibodi, Mahbod Gholamali Sinaki, Khalil Alipour
分类: eess.SY
发布日期: 2025-12-27
备注: Presented at the 13th RSI International Conference on Robotics and Mechatronics (ICRoM 2025), Dec. 16-18, 2025, Tehran, Iran
💡 一句话要点
提出基于积分强化学习的状态依赖Riccati方程方法,用于非线性仿射系统的最优控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态依赖Riccati方程 积分强化学习 非线性系统控制 最优调节 代数Riccati方程
📋 核心要点
- 传统SDRE方法依赖于精确的系统模型,且求解状态依赖Riccati方程计算量大,限制了其在复杂非线性系统中的应用。
- 本文提出一种基于积分强化学习的SDRE方法,通过学习而非直接求解Riccati方程,降低了对系统模型的依赖,并简化了计算。
- 仿真结果表明,该方法在非线性系统控制中,能够达到与传统SDRE方法相近的性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种基于积分强化学习(IRL)的状态依赖Riccati方程(SDRE)方法,用于非线性仿射系统的最优调节。SDRE技术通过设计输入来优化系统状态,使其趋向于原点,同时优化二次性能指标,从而将经典的代数Riccati公式推广到非线性系统。由于SDRE的解析解通常难以获得,一种方法是在每个状态对系统进行线性化,求解相应的代数Riccati方程(ARE),并应用最优控制直到下一个状态。为了避免对完整模型的依赖,本文提出了一种部分无模型的方法,该方法基于IRL在系统的每个状态学习最优控制,无需显式了解漂移动力学。仿真结果表明,经过足够的迭代,基于IRL的方法可以达到与传统SDRE方法近似的性能,证明了其作为非线性系统控制的可靠替代方案的能力,且无需显式的环境模型。
🔬 方法详解
问题定义:针对非线性输入仿射系统的最优调节问题,传统的状态依赖Riccati方程(SDRE)方法需要精确的系统模型,并且求解状态依赖的Riccati方程计算量大。当系统模型未知或者难以精确建模时,传统SDRE方法难以应用。因此,需要一种能够在模型不确定情况下实现最优控制的方法。
核心思路:本文的核心思路是利用积分强化学习(IRL)来学习每个状态下的最优控制策略,从而避免直接求解状态依赖的Riccati方程。通过IRL,系统可以在与环境的交互中学习到最优控制策略,而无需显式地知道系统的漂移动力学模型。
技术框架:该方法主要包含以下几个阶段:1) 在每个状态下,利用IRL算法学习最优控制策略。IRL算法通过与环境的交互,不断更新控制策略,使其能够最小化性能指标。2) 将学习到的控制策略应用于非线性系统中,调节系统状态使其趋向于原点。3) 评估控制性能,并根据性能反馈调整IRL算法的参数,以进一步提高控制性能。
关键创新:该方法最重要的技术创新点在于将积分强化学习与状态依赖Riccati方程方法相结合,从而实现了在模型不确定情况下对非线性系统的最优控制。与传统的SDRE方法相比,该方法不需要精确的系统模型,并且避免了求解状态依赖的Riccati方程,降低了计算复杂度。
关键设计:IRL算法采用基于策略迭代的方法,通过不断评估和改进控制策略来学习最优控制。性能指标采用二次型形式,用于衡量系统状态与原点的偏差以及控制输入的能量消耗。学习率和折扣因子等参数需要根据具体问题进行调整,以保证算法的收敛性和控制性能。
🖼️ 关键图片
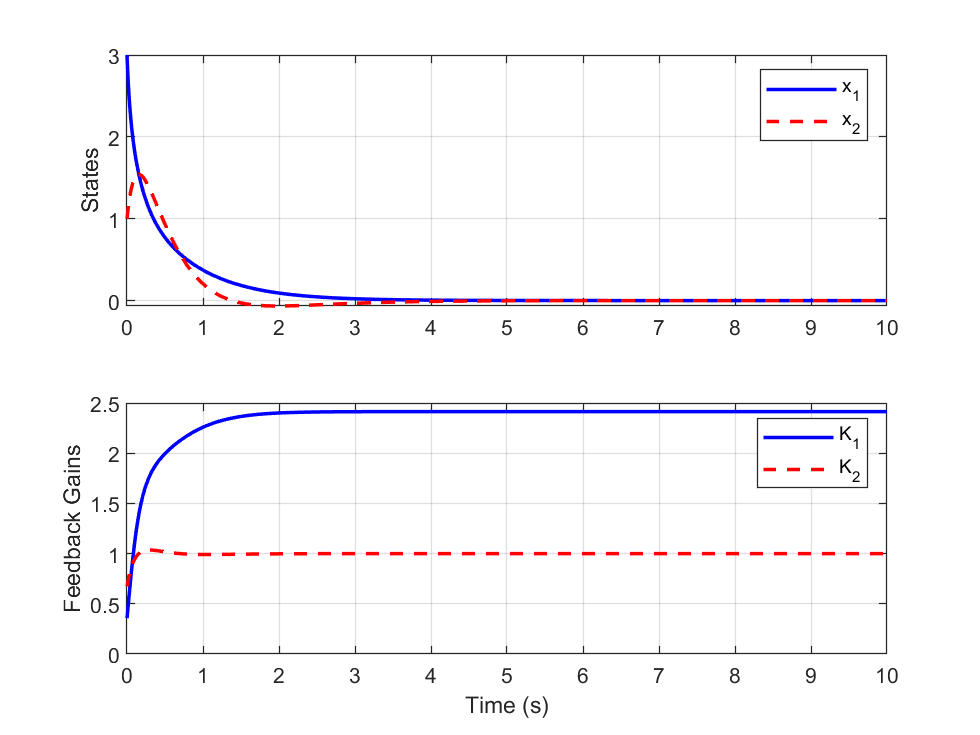
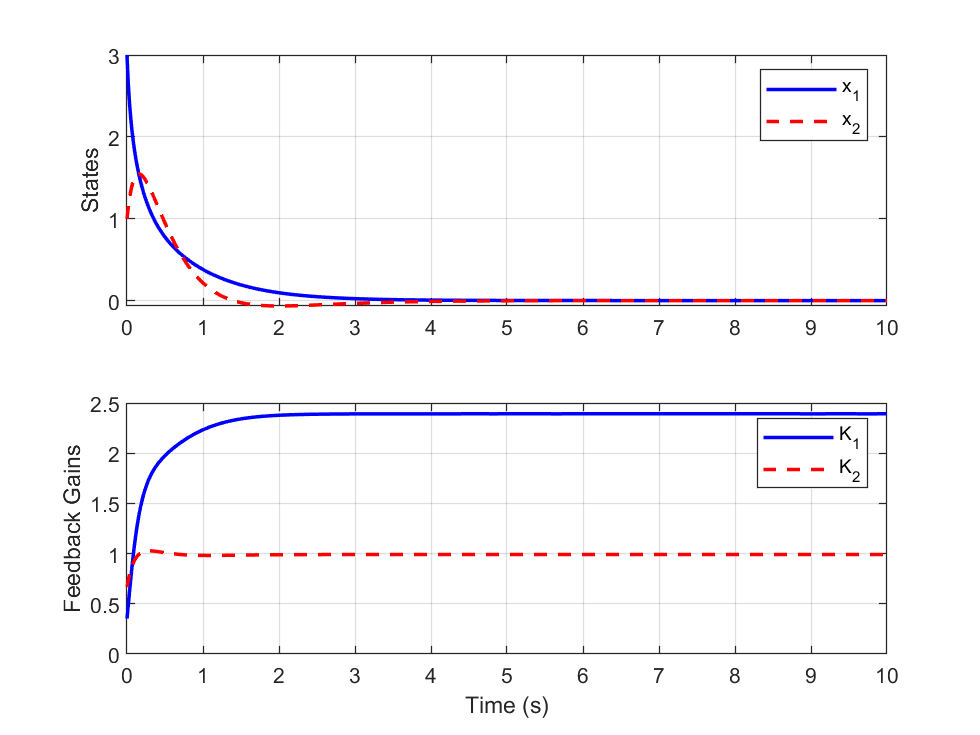
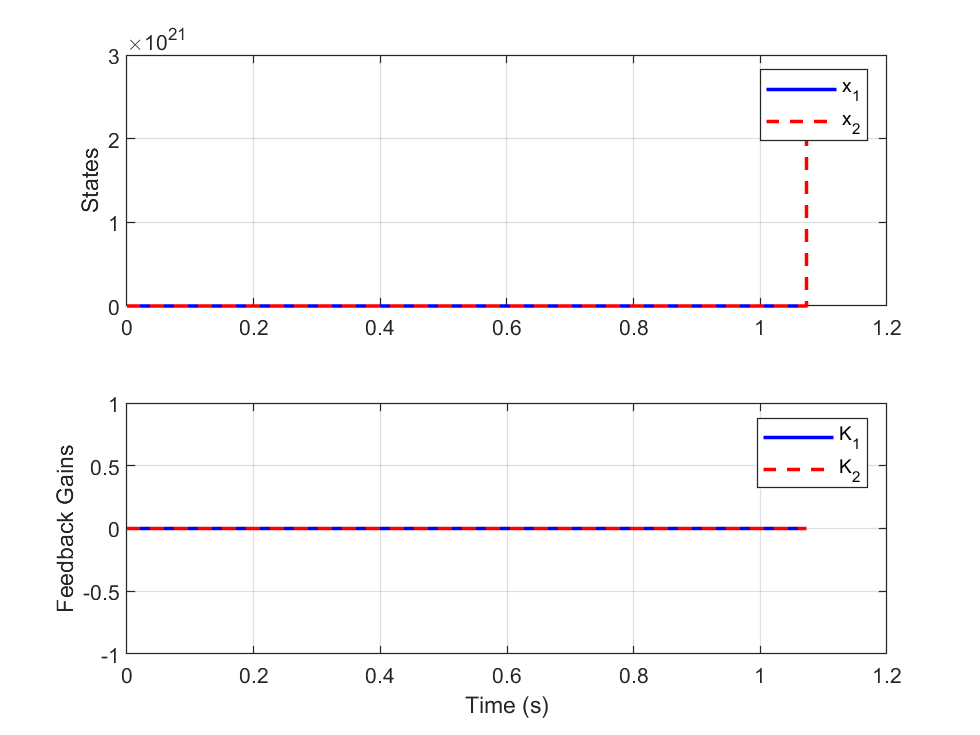
📊 实验亮点
仿真结果表明,基于积分强化学习的SDRE方法在第二阶非线性系统中,经过足够的迭代后,能够达到与传统的SDRE方法近似的性能。这表明该方法在不需要精确系统模型的情况下,也能够实现有效的非线性系统控制,为模型不确定系统的控制提供了一种新的选择。
🎯 应用场景
该研究成果可应用于各种非线性系统的最优控制,例如机器人控制、航空航天控制、电力系统控制等。特别是在系统模型难以精确获取或者存在不确定性的情况下,该方法具有重要的应用价值。未来,该方法可以进一步扩展到更复杂的非线性系统,并与其他控制方法相结合,以实现更高效、更鲁棒的控制性能。
📄 摘要(原文)
The State-Dependent Riccati Equation (SDRE) technique generalizes the classical algebraic Riccati formulation to nonlinear systems by designing an input to the system that optimally(suboptimally) regulates system states toward the origin while simultaneously optimizing a quadratic performance index. In the SDRE technique, we solve the State-Dependent Riccati Equation to determine the control for regulating a nonlinear input-affine system. Since an analytic solution to SDRE is not straightforward, one method is to linearize the system at every state, solve the corresponding Algebraic Riccati Equation (ARE), and apply optimal control until the next state of the system. Completing this task with high frequency gives a result like the original SDRE technique. Both approaches require a complete model; therefore, here we propose a method that solves ARE in every state of the system using a partially model-free approach that learns optimal control in every state of the system, without explicit knowledge of the drift dynamics, based on Integral Reinforcement Learning (IRL). To show the effectiveness of our proposed approach, we apply it to the second-order nonlinear system in simulation and compare its performance with the classical SDRE method, which relies on the system's model and solves the ARE at each state. Our simulation results demonstrate that, with sufficient iterations, the IRL-based approach achieves approximately the same performance as the conventional SDRE method, demonstrating its capability as a reliable alternative for nonlinear system control that does not require an explicit environmental model. Index Terms-Algebraic Riccati Equation (ARE), Integral Reinforcement Learning (IRL), Nonlinear Input-Affine Systems, Optimal Regulation, State-Dependent Riccati Equation (SDRE)