Electric Arc Furnaces Scheduling under Electricity Price Volatility with Reinforcement Learning
作者: Ruonan Pi, Zhiyuan Fan, Bolun Xu
分类: eess.SY
发布日期: 2025-12-10
备注: 10 pages, 5 figures,7 tables
💡 一句话要点
提出基于强化学习的电弧炉调度框架,应对电力价格波动
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 电弧炉调度 强化学习 Q-learning 电力价格波动 混合整数线性规划
📋 核心要点
- 现有电弧炉调度方法难以应对电力价格的实时波动,导致运行成本增加。
- 论文提出基于Q-learning的电弧炉调度方法,通过学习优化策略来降低成本。
- 实验表明,该方法在实际数据上能达到完美预测MILP基准90%的利润水平。
📝 摘要(中文)
本文提出了一种基于强化学习的框架,用于优化电力价格波动下的电弧炉(EAF)运行。我们将EAF调度问题的确定性版本建模为混合整数线性规划(MILP)问题,然后开发了一种Q-learning算法,以在实时价格波动和共享进料能力约束下对多个EAF单元进行实时控制。我们为Q-learning算法设计了一个自定义奖励函数,以平滑EAF的启动惩罚。使用来自EAF设计和纽约州电价的真实数据,我们将我们的算法与基线规则控制器和MILP基准(假设完美的價格预测)进行比较。结果表明,在非预见性控制设置下,我们的强化学习算法在各种单单元和多单元案例中实现了与完美MILP基准相比约90%的利润。
🔬 方法详解
问题定义:论文旨在解决电力价格波动环境下,电弧炉(EAF)的优化调度问题。传统方法,如基于规则的控制器或依赖完美预测的MILP,难以适应实时价格变化,导致次优的运行策略和更高的成本。现有方法的痛点在于无法有效处理不确定性和动态变化的环境。
核心思路:论文的核心思路是利用强化学习(Q-learning)算法,使EAF调度策略能够自适应地学习和优化,从而在电力价格波动的情况下做出更明智的决策。通过与环境的交互,Q-learning算法能够学习到在不同价格水平和约束条件下,如何启动、停止或调整EAF的运行,以最大化利润。
技术框架:整体框架包括以下几个主要部分:1) 将EAF调度问题建模为混合整数线性规划(MILP)问题,作为确定性问题的基准;2) 构建Q-learning算法,包括状态空间、动作空间和奖励函数的设计;3) 使用真实世界的EAF数据和电力价格数据训练Q-learning模型;4) 将训练好的Q-learning模型部署到实时控制系统中,根据当前的价格和约束条件做出调度决策。
关键创新:最重要的技术创新点在于将强化学习应用于电弧炉调度问题,从而能够在不依赖完美价格预测的情况下,实现接近最优的调度策略。与传统的基于规则或优化的方法相比,强化学习方法能够更好地适应环境的变化,并学习到更复杂的调度策略。此外,自定义的奖励函数能够有效地平滑EAF的启动惩罚,鼓励算法探索更优的启动时机。
关键设计:关键设计包括:1) 状态空间的设计,需要包含足够的信息来描述当前的环境状态,例如当前时间和电力价格;2) 动作空间的设计,需要定义EAF可以执行的动作,例如启动、停止或调整功率;3) 奖励函数的设计,需要反映调度策略的优劣,例如利润、成本和启动惩罚。论文特别设计了奖励函数来平滑启动惩罚,避免算法过于保守。
🖼️ 关键图片
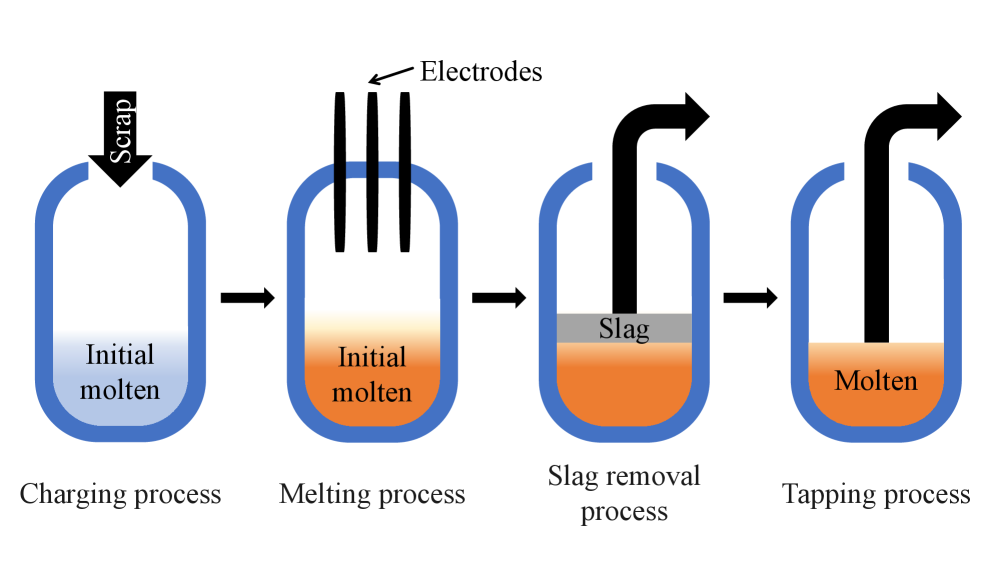
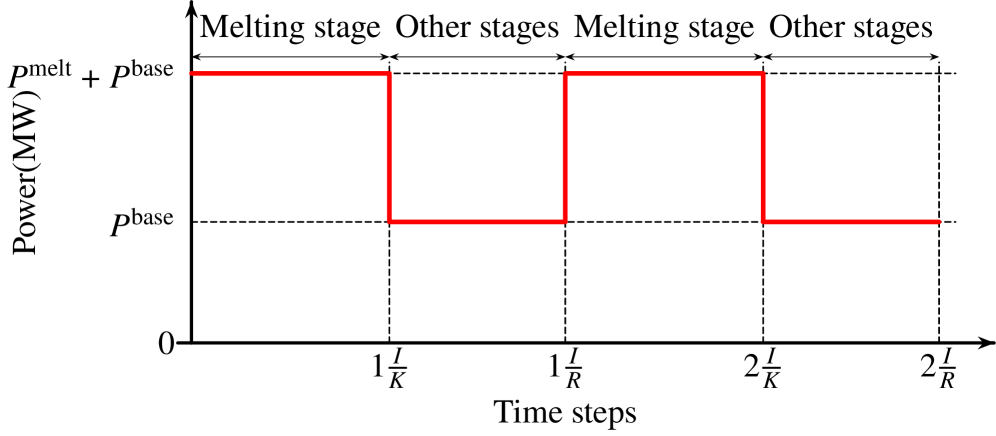
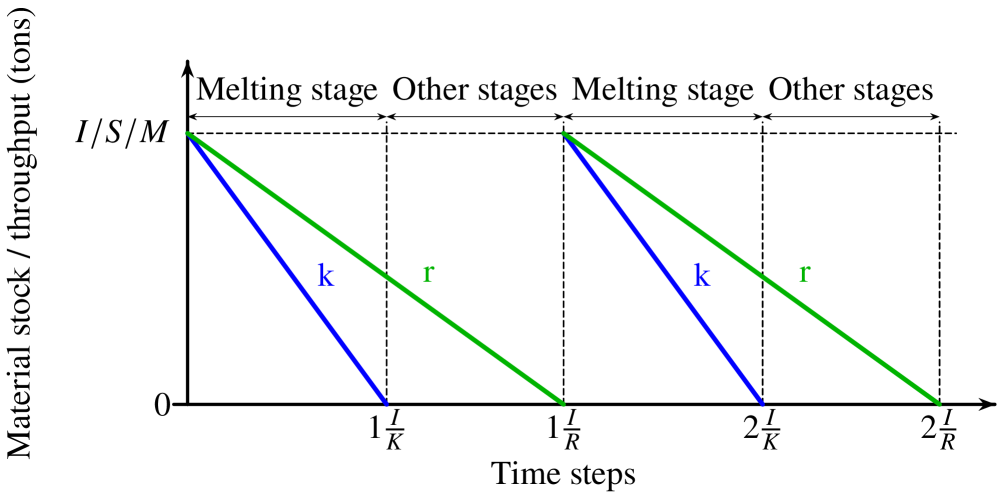
📊 实验亮点
实验结果表明,在各种单单元和多单元案例中,基于Q-learning的调度算法在非预见性控制设置下,实现了与完美价格预测的MILP基准相比约90%的利润。这表明该算法能够在不依赖完美预测的情况下,有效地优化电弧炉的运行,并显著降低成本。
🎯 应用场景
该研究成果可应用于钢铁行业的电弧炉生产调度优化,降低能源成本,提高生产效率。通过实时调整电弧炉的运行策略,企业可以更好地应对电力市场的波动,实现更经济、更可持续的生产。该方法也可推广到其他高耗能行业的生产调度优化中,具有广泛的应用前景。
📄 摘要(原文)
This paper proposes a reinforcement learning-based framework for optimizing the operation of electric arc furnaces (EAFs) under volatile electricity prices. We formulate the deterministic version of the EAF scheduling problem into a mixed-integer linear programming (MILP) formulation, and then develop a Q-learning algorithm to perform real-time control of multiple EAF units under real-time price volatility and shared feeding capacity constraints. We design a custom reward function for the Q-learning algorithm to smooth the start-up penalties of the EAFs. Using real data from EAF designs and electricity prices in New York State, we benchmark our algorithm against a baseline rule-based controller and a MILP benchmark, assuming perfect price forecasts. The results show that our reinforcement learning algorithm achieves around 90% of the profit compared to the perfect MILP benchmark in various single-unit and multi-unit cases under a non-anticipatory control setting.