Data Generation for Stability Studies of Power Systems with High Penetration of Inverter-Based Resources
作者: Francesca Rossi, Mauro Garcia Lorenzo, Eduardo Iraola de Acevedo, Elia Mateu Barriendos, Vinicius Albernaz Lacerda, Francesc Lordan-Gomis, Rosa Badia, Eduardo Prieto-Araujo
分类: eess.SY
发布日期: 2025-12-06 (更新: 2026-01-23)
💡 一句话要点
提出一种基于高性能计算的电力系统稳定性数据生成框架,用于解决高比例新能源接入下的稳定性评估问题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 电力系统稳定性 逆变器型资源 数据驱动 灵敏度分析 自适应采样 高性能计算 小信号分析
📋 核心要点
- 高比例新能源接入改变了电力系统动态特性,传统稳定性评估方法面临挑战,缺乏足够的数据支撑。
- 提出一种基于灵敏度分析的自适应采样策略,高效探索电力系统运行空间,生成高质量的稳定性数据集。
- 该框架采用Python实现,支持并行计算,能够有效处理大规模电力系统,为数据驱动的稳定性研究提供支持。
📝 摘要(中文)
随着逆变器型资源(IBRs)渗透率的不断提高,电力系统动态特性正在发生根本性改变,给稳定性评估带来了新的挑战。数据驱动方法,特别是机器学习模型,需要大型且具有代表性的数据集,以捕捉系统稳定性在各种运行条件和控制设置下的变化。本文提出了一个开源、高性能计算框架,用于系统地生成此类数据集。该工具定义了大规模电力系统的可扩展运行空间,通过灵敏度分析指导的自适应采样策略对其进行探索,并执行小信号稳定性评估,以填充高信息量的数据集。该框架有效地瞄准了接近稳定裕度的区域,同时保持了对可行运行条件的广泛覆盖。该工作流程完全用Python实现,并设计用于并行执行。由此产生的工具能够创建高质量的数据集,从而支持现代高 IBR 渗透率电力系统中的数据驱动稳定性研究。
🔬 方法详解
问题定义:论文旨在解决高比例逆变器型资源(IBRs)接入电力系统后,传统稳定性评估方法面临的数据不足问题。现有方法难以覆盖各种运行条件和控制设置,导致数据驱动的稳定性评估模型缺乏足够的训练数据,泛化能力受限。
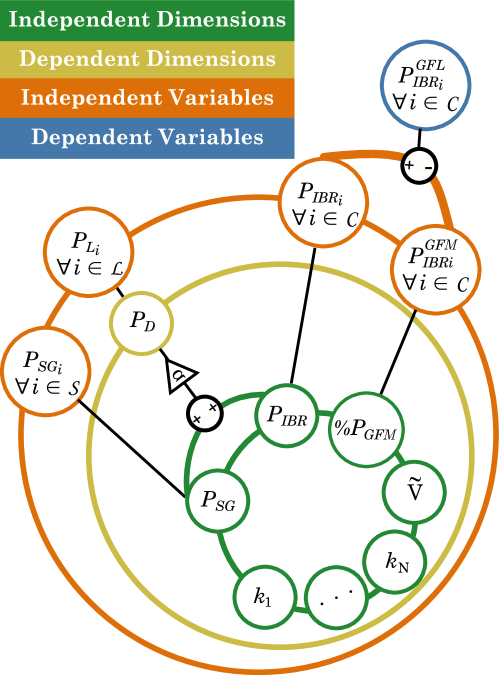
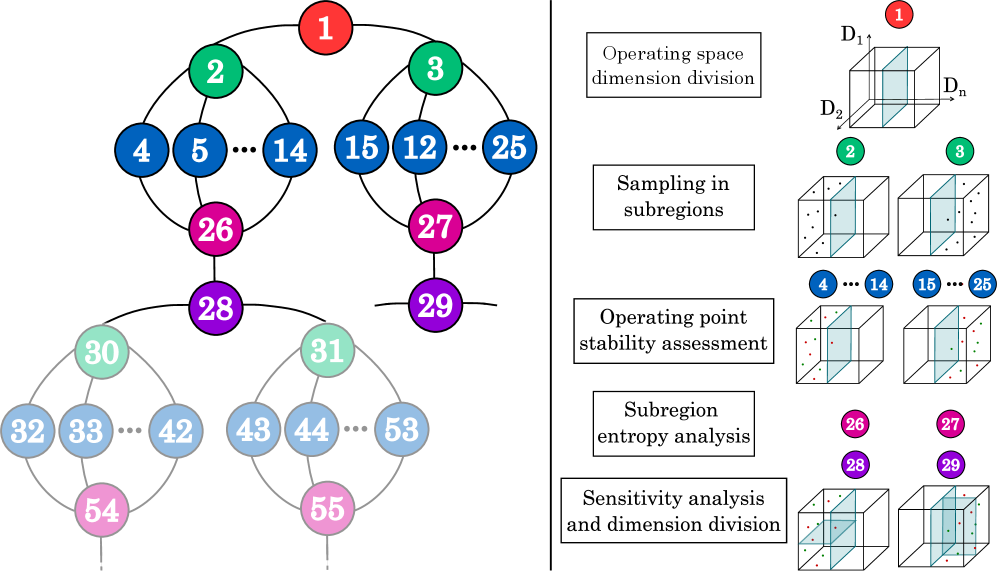
核心思路:论文的核心思路是构建一个能够系统性生成高质量电力系统稳定性数据集的框架。该框架通过定义可扩展的运行空间,并采用自适应采样策略,高效地探索系统运行状态,从而生成包含丰富信息的训练数据。灵敏度分析被用于指导采样过程,使得框架能够重点关注接近稳定裕度的区域,提高数据集中不稳定样本的比例。
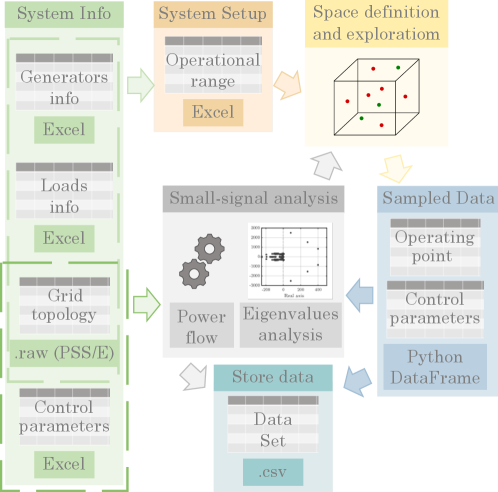
技术框架:该框架主要包含以下几个模块:1) 定义电力系统的可扩展运行空间,包括各种运行参数和控制设置的范围;2) 使用灵敏度分析确定对系统稳定性影响较大的参数;3) 基于灵敏度分析结果,采用自适应采样策略,在运行空间中选择采样点;4) 对每个采样点进行小信号稳定性评估,判断系统是否稳定;5) 将采样点和稳定性评估结果存储为数据集。整个流程使用Python实现,并设计为可并行执行,以提高数据生成效率。
关键创新:该论文的关键创新在于提出了基于灵敏度分析的自适应采样策略。与传统的随机采样或网格采样方法相比,该策略能够更有效地探索运行空间,并重点关注接近稳定裕度的区域,从而生成包含更多不稳定样本的高质量数据集。此外,该框架的开源和高性能计算设计也使其易于使用和扩展。
关键设计:框架的关键设计包括:1) 运行空间的定义,需要根据具体的电力系统进行调整,包括发电机出力、负荷水平、控制参数等;2) 灵敏度分析方法的选择,可以使用特征值分析或其他灵敏度指标;3) 自适应采样策略的具体实现,例如可以使用基于梯度的优化算法或强化学习方法;4) 小信号稳定性评估的算法选择,例如可以使用特征值分析或时域仿真。
🖼️ 关键图片
📊 实验亮点
该框架通过灵敏度分析指导的自适应采样策略,能够高效地生成包含丰富信息的稳定性数据集。与随机采样相比,该策略能够显著提高数据集中不稳定样本的比例,从而提高数据驱动的稳定性评估模型的性能。此外,该框架的并行计算设计使其能够处理大规模电力系统,为实际应用提供了可能。
🎯 应用场景
该研究成果可应用于电力系统规划、运行和控制等领域。通过生成高质量的稳定性数据集,可以训练数据驱动的稳定性评估模型,用于在线监测系统稳定性、预测潜在的失稳风险,并为控制策略的制定提供依据。此外,该框架还可以用于研究不同控制策略对系统稳定性的影响,为新能源接入比例的提高提供技术支持。
📄 摘要(原文)
The increasing penetration of inverter-based resources (IBRs) is fundamentally reshaping power system dynamics and creating new challenges for stability assessment. Data-driven approaches, and in particular machine learning models, require large and representative datasets that capture how system stability varies across a wide range of operating conditions and control settings. This paper presents an open-source, high-performance computing framework for the systematic generation of such datasets. The proposed tool defines a scalable operating space for large-scale power systems, explores it through an adaptive sampling strategy guided by sensitivity analysis, and performs small-signal stability assessments to populate a high-information-content dataset. The framework efficiently targets regions near the stability margin while maintaining broad coverage of feasible operating conditions. The workflow is fully implemented in Python and designed for parallel execution. The resulting tool enables the creation of high-quality datasets that support data-driven stability studies in modern power systems with high IBR penetration.