LA-RL: Language Action-guided Reinforcement Learning with Safety Guarantees for Autonomous Highway Driving
作者: Yiming Shu, Jiahui Xu, Jiwei Tang, Ruiyang Gao, Chen Sun
分类: eess.SY
发布日期: 2025-12-05
💡 一句话要点
提出基于语言动作引导强化学习的LA-RL框架,保障自动驾驶安全并提升效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 大型语言模型 安全保障 模型预测控制
📋 核心要点
- 现有自动驾驶方法难以兼顾驾驶效率和安全性,尤其是在复杂交通环境中。
- LA-RL框架利用LLM进行语义推理,结合改进的安全层,实现安全保障下的高效驾驶。
- 实验表明,LA-RL显著优于现有方法,成功率提升20%-30%,在低密度环境达到100%。
📝 摘要(中文)
本文提出了一种具有安全保障的语言动作引导强化学习(LA-RL)框架,用于自动高速公路驾驶。该框架将大型语言模型(LLM)的语义推理集成到actor-critic架构中,并结合改进的安全层。通过任务特定的奖励塑造,LA-RL协调了最大化驾驶效率和确保安全的双重目标,基于环境洞察和明确定义的目标来指导决策。为了增强安全性,LA-RL结合了模型预测控制(MPC)和离散控制障碍函数(DCBFs)的安全关键规划器,将LLM指导的策略正式约束到安全动作集,并采用松弛机制来提高解的可行性,防止过度保守的行为,并在不损害安全性的前提下允许更大的策略探索。大量实验表明,该方法显著优于几种当前最先进的方法,为自动高速公路驾驶提供了一种更具适应性、可靠性和鲁棒性的解决方案。与现有的SOTA方法相比,其成功率比基于知识图(KG)的基线高约20%,比基于检索增强生成(RAG)的基线高约30%。在低密度环境中,LA-RL的成功率达到100%。这些结果证实了其增强的state-action空间探索能力,以及在复杂的混合交通高速公路环境中自主采用更高效、更主动策略的能力。
🔬 方法详解
问题定义:自动驾驶需要在追求效率的同时保证安全性,尤其是在高速公路这种复杂场景下。现有的强化学习方法在探索和利用之间难以平衡,容易出现不安全的行为。此外,如何有效地利用环境信息(例如其他车辆的意图)也是一个挑战。
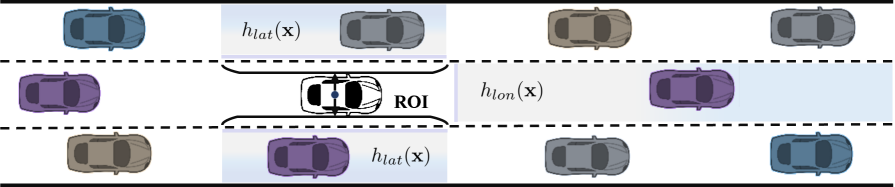
核心思路:论文的核心思路是将大型语言模型(LLM)的语义理解能力融入到强化学习框架中,利用LLM对环境信息进行推理,指导策略学习。同时,引入一个安全层,使用模型预测控制(MPC)和离散控制障碍函数(DCBFs)来保证策略的安全性,防止出现危险行为。
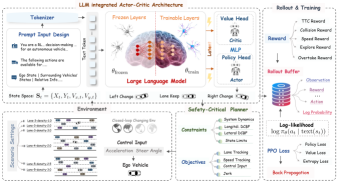
技术框架:LA-RL框架主要包含三个模块:1) 基于LLM的Actor-Critic网络,负责策略学习和价值评估;2) 任务特定的奖励塑造,用于平衡驾驶效率和安全性;3) 安全关键规划器,结合MPC和DCBFs,确保策略的安全性。整体流程是:首先,LLM根据环境信息生成动作建议;然后,Actor-Critic网络根据LLM的建议和当前状态选择动作;最后,安全关键规划器对选择的动作进行验证,确保其安全性,如果动作不安全,则将其修正为安全动作。
关键创新:最重要的创新点在于将LLM的语义推理能力与强化学习相结合,利用LLM对环境信息进行更深入的理解,从而指导策略学习。此外,安全关键规划器的设计也保证了策略的安全性,防止出现危险行为。与现有方法的本质区别在于,LA-RL能够更好地利用环境信息,并在保证安全性的前提下实现更高的驾驶效率。
关键设计:任务特定的奖励函数设计是关键,需要平衡驾驶效率和安全性。安全关键规划器中的MPC和DCBFs的参数设置也需要仔细调整,以保证其能够有效地约束策略,同时避免过度保守的行为。此外,LLM的选择和训练也对最终的性能有重要影响。论文中使用了slack机制来提高MPC的可行性,允许策略在一定范围内进行探索,而不会立即被安全层阻止。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LA-RL在自动驾驶任务中显著优于现有方法。与基于知识图(KG)的基线相比,成功率提高了约20%,与基于检索增强生成(RAG)的基线相比,成功率提高了约30%。在低密度环境中,LA-RL的成功率达到了100%,表明其具有很强的适应性和鲁棒性。这些结果验证了LA-RL在复杂交通环境中的有效性。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,尤其是在高速公路、城市道路等复杂交通环境中。通过提高自动驾驶系统的安全性和效率,可以减少交通事故,提高交通效率,并为未来的智能交通系统奠定基础。此外,该方法还可以扩展到其他需要安全保障的强化学习应用中,例如机器人控制、金融交易等。
📄 摘要(原文)
Autonomous highway driving demands a critical balance between proactive, efficiency-seeking behavior and robust safety guarantees. This paper proposes Language Action-guided Reinforcement Learning (LA-RL) with Safety Guarantees, a novel framework that integrates the semantic reasoning of large language models (LLMs) into the actor-critic architecture with an improved safety layer. Within this framework, task-specific reward shaping harmonizes the dual objectives of maximizing driving efficiency and ensuring safety, guiding decision-making based on both environmental insights and clearly defined goals. To enhance safety, LA-RL incorporates a safety-critical planner that combines model predictive control (MPC) with discrete control barrier functions (DCBFs). This layer formally constrains the LLM-informed policy to a safe action set, employs a slack mechanism that enhances solution feasibility, prevents overly conservative behavior and allows for greater policy exploration without compromising safety. Extensive experiments demonstrate that it significantly outperforms several current state-of-the-art methods, offering a more adaptive, reliable, and robust solution for autonomous highway driving. Compared to existing SOTA, it achieves approximately 20$\%$ higher success rate than the knowledge graph (KG) based baseline and about 30$\%$ higher than the retrieval augmented generation (RAG) based baseline. In low-density environments, LA-RL achieves a 100$\%$ success rate. These results confirm its enhanced exploration of the state-action space and its ability to autonomously adopt more efficient, proactive strategies in complex, mixed-traffic highway environments.