Multi-Agent Deep Reinforcement Learning for UAV-Assisted 5G Network Slicing: A Comparative Study of MAPPO, MADDPG, and MADQN
作者: Ghoshana Bista, Abbas Bradai, Emmanuel Moulay, Abdulhalim Dandoush
分类: eess.SY
发布日期: 2025-12-03
备注: 19 pages, 13 figures. Under review for journal submission
💡 一句话要点
提出基于多智能体深度强化学习的UAV辅助5G网络切片方案,优化QoS与能效。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 无人机 5G网络切片 资源分配 服务质量 能源效率 集中式训练分散式执行
📋 核心要点
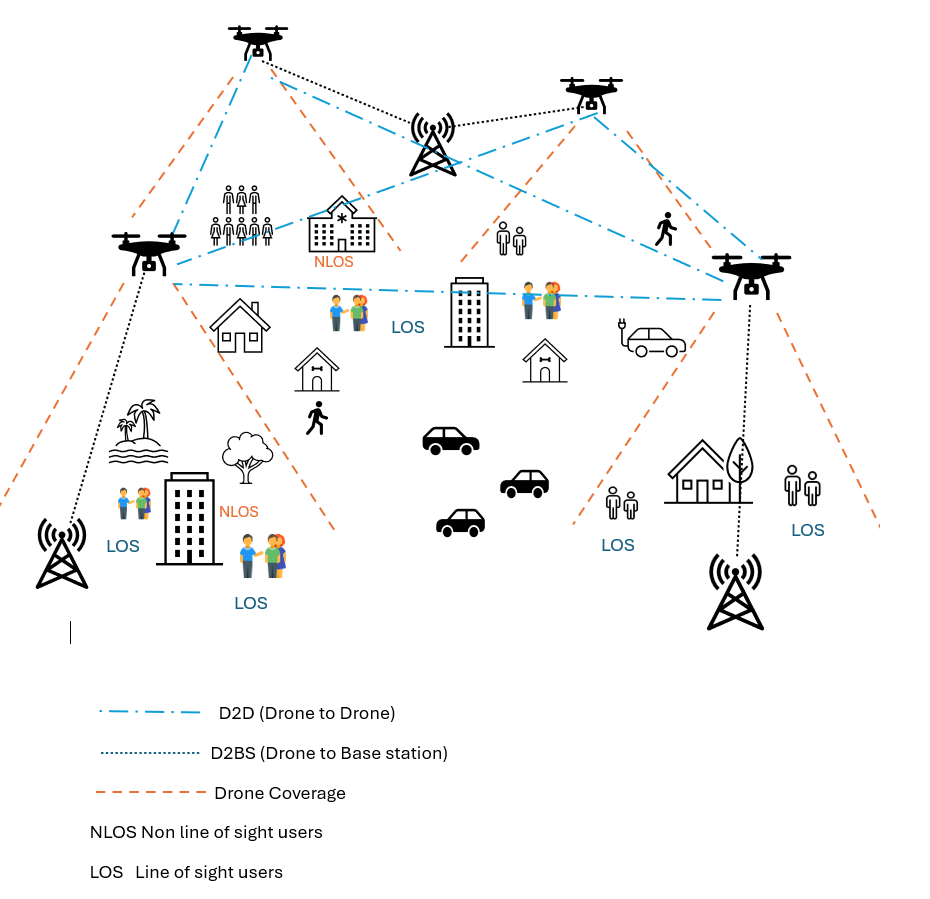
- 5G及未来无线网络对高鲁棒性和可扩展性需求日益增长,无人机作为移动基站可增强密集城市和欠发达农村地区的覆盖。
- 论文提出基于MADRL的框架,利用MAPPO、MADDPG和MADQN联合优化UAV定位、资源分配、QoS和能效,实现网络切片。
- 实验表明,MAPPO在干扰环境中QoS-能效权衡最佳,MADDPG在开阔农村场景SINR略高但能耗增加,MADQN为离散动作空间提供高效基线。
📝 摘要(中文)
本文提出了一种多智能体深度强化学习(MADRL)框架,该框架集成了近端策略优化(MAPPO)、多智能体深度确定性策略梯度(MADDPG)和多智能体深度Q网络(MADQN),通过5G网络切片联合优化无人机(UAV)定位、资源分配、服务质量(QoS)和能源效率。该框架采用集中式训练分散式执行(CTDE),在保持全局协调的同时实现自主实时决策。用户被划分为具有不同QoS要求的Premium(A)、Silver(B)和Bronze(C)切片。在现实的城市和农村场景中的实验表明,MAPPO实现了最佳的整体QoS-能源权衡,尤其是在干扰丰富的环境中;MADDPG提供了更精确的连续控制,并且在开放的农村环境中可以以增加能源消耗为代价获得稍高的SINR;MADQN为离散化动作空间提供了一个计算效率高的基线。这些发现表明,没有一种MARL算法是普遍占优的;相反,算法的适用性取决于环境拓扑、用户密度和服务要求。所提出的框架突出了MARL驱动的UAV系统在下一代无线网络中增强可扩展性、可靠性和差异化QoS交付的潜力。
🔬 方法详解
问题定义:论文旨在解决在5G网络中,如何利用无人机(UAV)作为移动基站,通过网络切片技术,在满足不同用户服务质量(QoS)需求的同时,优化无人机的定位、资源分配和能源效率的问题。现有方法在处理复杂环境、用户动态变化以及多智能体协作方面存在不足,难以实现全局优化。
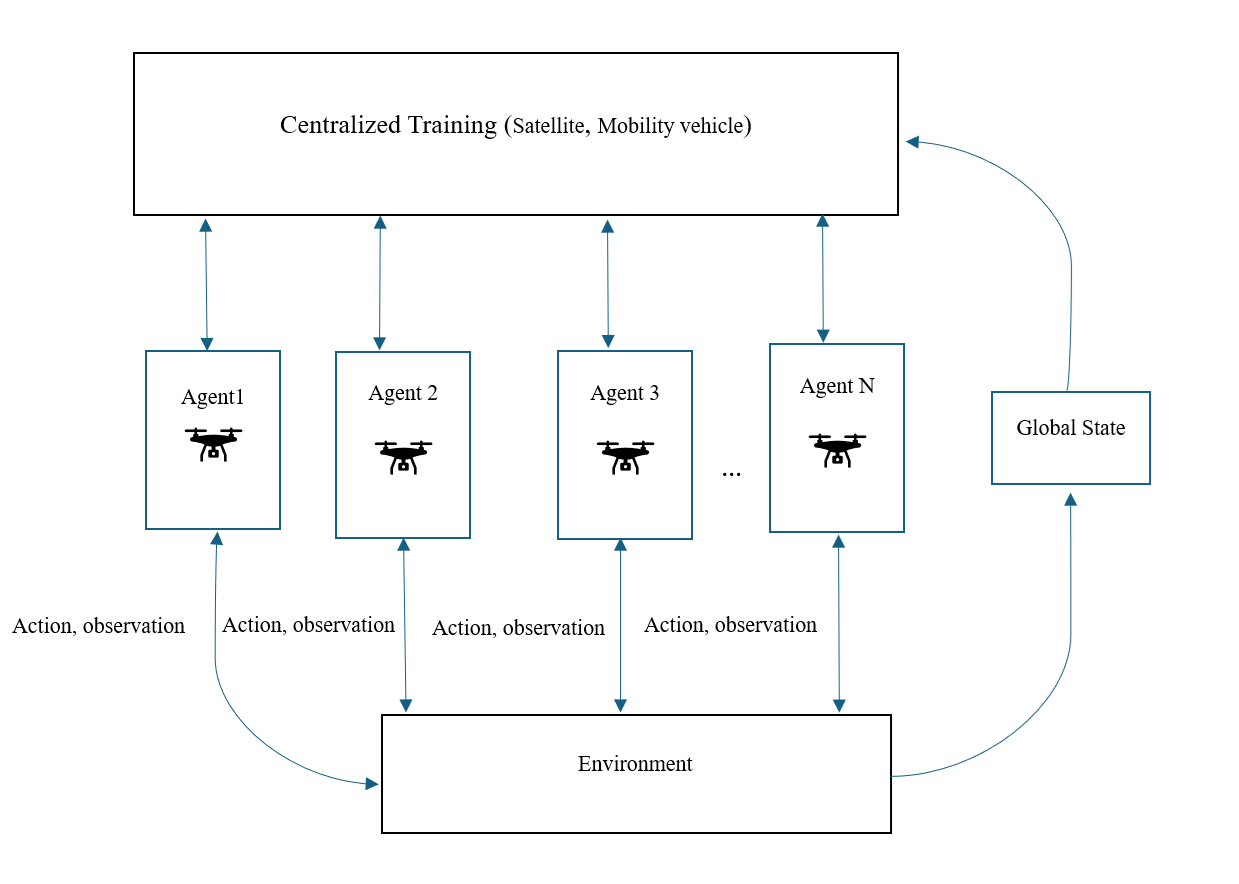
核心思路:论文的核心思路是利用多智能体深度强化学习(MADRL)框架,将每个无人机视为一个智能体,通过学习环境中的策略,实现无人机之间的协同,从而优化整个网络的性能。采用集中式训练分散式执行(CTDE)架构,允许智能体在训练阶段共享全局信息,但在执行阶段独立决策,以适应实际应用中的分布式环境。
技术框架:该框架包含以下主要模块:1) 环境建模:模拟真实的城市和农村环境,包括用户分布、信道模型和干扰情况。2) 智能体设计:每个无人机配备一个MADRL算法(MAPPO、MADDPG或MADQN),负责学习最优策略。3) 奖励函数设计:根据QoS(如SINR)、能源效率和网络切片优先级等因素,设计奖励函数,引导智能体学习期望的行为。4) 训练过程:使用CTDE架构,在集中式训练阶段,所有智能体共享信息并共同学习;在分散式执行阶段,每个智能体根据自身观测独立决策。
关键创新:论文的关键创新在于将MADRL应用于UAV辅助的5G网络切片,并比较了三种不同的MADRL算法(MAPPO、MADDPG和MADQN)的性能。通过实验分析,揭示了不同算法在不同环境下的适用性,为实际应用中选择合适的算法提供了指导。此外,CTDE架构的应用使得智能体能够在分布式环境中实现高效的协作。
关键设计:论文中关键的设计包括:1) 网络切片策略:将用户划分为Premium、Silver和Bronze三个等级,并为每个等级设置不同的QoS要求。2) 奖励函数设计:综合考虑SINR、能源消耗和切片优先级,设计奖励函数,鼓励智能体在满足QoS要求的同时,降低能源消耗。3) 算法参数设置:针对MAPPO、MADDPG和MADQN三种算法,分别调整学习率、折扣因子和探索策略等参数,以获得最佳性能。
🖼️ 关键图片
📊 实验亮点
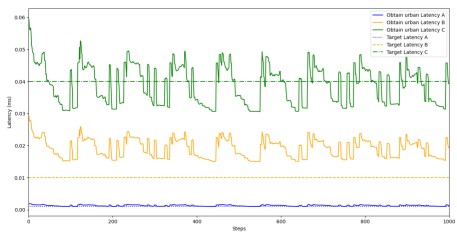
实验结果表明,MAPPO在干扰丰富的环境中实现了最佳的QoS-能源权衡。MADDPG在开放的农村环境中可以获得稍高的SINR,但能耗较高。MADQN为离散动作空间提供了一个计算效率高的基线。这些结果表明,算法的选择应根据具体的环境和需求进行调整,没有一种算法能够普遍适用。
🎯 应用场景
该研究成果可应用于未来的5G和Beyond网络,尤其是在需要灵活部署和快速响应的场景中,如灾难救援、大型活动保障、临时网络覆盖等。通过智能化的无人机部署和资源分配,可以显著提升网络性能,改善用户体验,并降低运营成本。该研究也为未来智能无线网络的设计和优化提供了新的思路。
📄 摘要(原文)
The growing demand for robust, scalable wireless networks in the 5G-and-beyond era has led to the deployment of Unmanned Aerial Vehicles (UAVs) as mobile base stations to enhance coverage in dense urban and underserved rural areas. This paper presents a Multi-Agent Deep Reinforcement Learning (MADRL) framework that integrates Proximal Policy Optimization (MAPPO), Multi-Agent Deep Deterministic Policy Gradient (MADDPG), and Multi-Agent Deep Q-Networks (MADQN) to jointly optimize UAV positioning, resource allocation, Quality of Service (QoS), and energy efficiency through 5G network slicing. The framework adopts Centralized Training with Decentralized Execution (CTDE), enabling autonomous real-time decision-making while preserving global coordination. Users are prioritized into Premium (A), Silver (B), and Bronze (C) slices with distinct QoS requirements. Experiments in realistic urban and rural scenarios show that MAPPO achieves the best overall QoS-energy tradeoff, especially in interference-rich environments; MADDPG offers more precise continuous control and can attain slightly higher SINR in open rural settings at the cost of increased energy usage; and MADQN provides a computationally efficient baseline for discretized action spaces. These findings demonstrate that no single MARL algorithm is universally dominant; instead, algorithm suitability depends on environmental topology, user density, and service requirements. The proposed framework highlights the potential of MARL-driven UAV systems to enhance scalability, reliability, and differentiated QoS delivery in next-generation wireless networks.