Lessons Learned from Developing a Privacy-Preserving Multimodal Wearable for Local Voice-and-Vision Inference
作者: Yonatan Tussa, Andy Heredia, Nirupam Roy
分类: cs.HC, eess.AS, eess.IV, eess.SY
发布日期: 2025-11-14 (更新: 2025-11-24)
💡 一句话要点
构建隐私保护的多模态可穿戴设备,用于本地语音和视觉推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态可穿戴设备 隐私保护 本地AI推理 边缘计算 语音视觉融合
📋 核心要点
- 现有可穿戴设备因隐私问题受限,无法充分利用多模态数据进行持续感知和计算。
- 设计耳戴式可穿戴设备,利用智能手机作为可信边缘,实现本地AI推理,保护用户隐私。
- 原型验证表明,在商品移动硬件上进行完全本地的多模态推理在交互延迟下是可行的。
📝 摘要(中文)
本文分享了构建一个耳戴式语音和视觉可穿戴设备的经验,该设备使用配对的智能手机作为可信的个人边缘设备执行本地AI推理。由于用户对隐私的担忧,许多有前景的多模态可穿戴设备应用需要持续感知和大量计算,但用户拒绝使用此类设备。我们描述了这个隐私保护系统的硬件-软件协同设计,包括在30克的外形尺寸内集成摄像头、麦克风和扬声器的挑战,实现唤醒词触发的捕获,以及完全离线运行量化的视觉-语言和大型语言模型。通过迭代原型设计,我们确定了功耗预算、连接性、延迟和社交可接受性方面的关键设计障碍。初步评估表明,完全本地的多模态推理在具有交互延迟的商品移动硬件上是可行的。最后,我们为研究人员开发嵌入式AI系统提供了设计经验,这些系统在日常环境中平衡了隐私、响应性和可用性。
🔬 方法详解
问题定义:论文旨在解决多模态可穿戴设备在隐私保护方面的挑战。现有方法通常依赖于云端计算,导致用户数据暴露的风险,阻碍了此类设备在日常生活中的广泛应用。因此,如何在保证设备功能的同时,最大限度地保护用户隐私是亟待解决的问题。
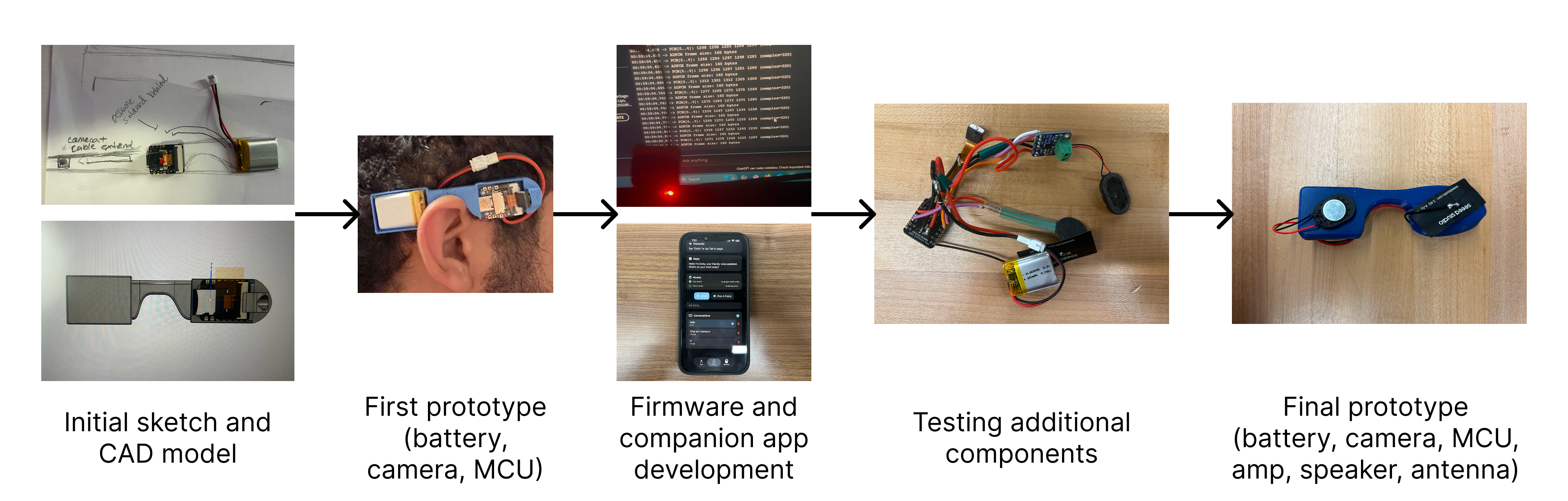
核心思路:论文的核心思路是将AI推理过程本地化,即在用户的智能手机上完成所有计算任务,避免将敏感数据上传到云端。通过这种方式,用户可以完全掌控自己的数据,从而提高对设备的信任度。同时,论文还关注了设备在功耗、连接性、延迟和社交可接受性等方面的设计挑战。
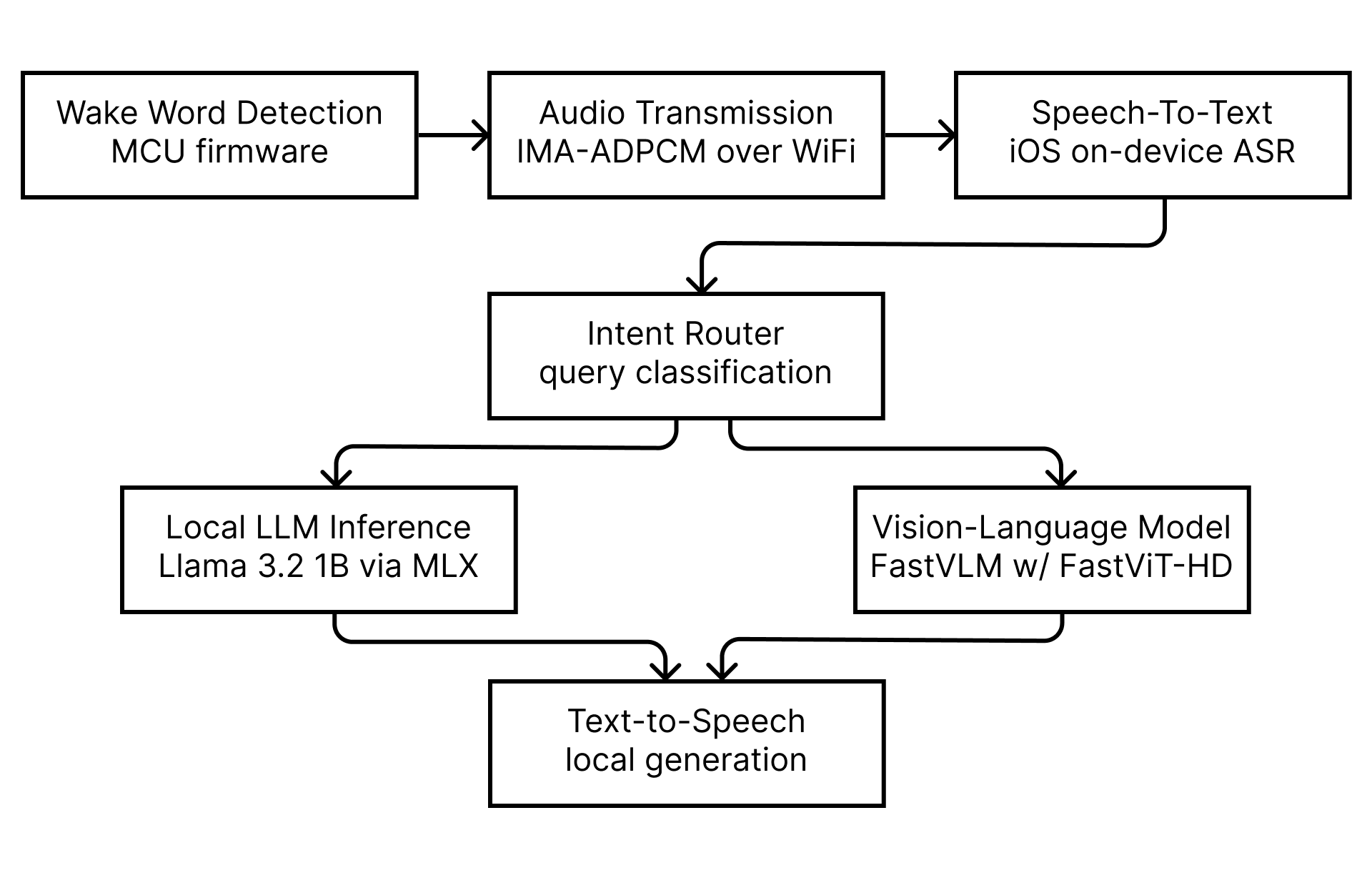
技术框架:该系统的整体架构包括一个耳戴式可穿戴设备和一个配对的智能手机。可穿戴设备负责采集语音和视觉数据,并通过蓝牙等无线连接方式将数据传输到智能手机。智能手机则负责运行量化的视觉-语言和大型语言模型,进行本地AI推理,并将结果反馈给用户。整个过程无需连接互联网,从而保证了用户数据的隐私安全。
关键创新:该论文的关键创新在于提出了一个完全本地化的多模态推理框架,该框架能够在保护用户隐私的前提下,实现可穿戴设备的智能化应用。此外,论文还关注了设备在功耗、连接性、延迟和社交可接受性等方面的设计挑战,并提出了相应的解决方案。
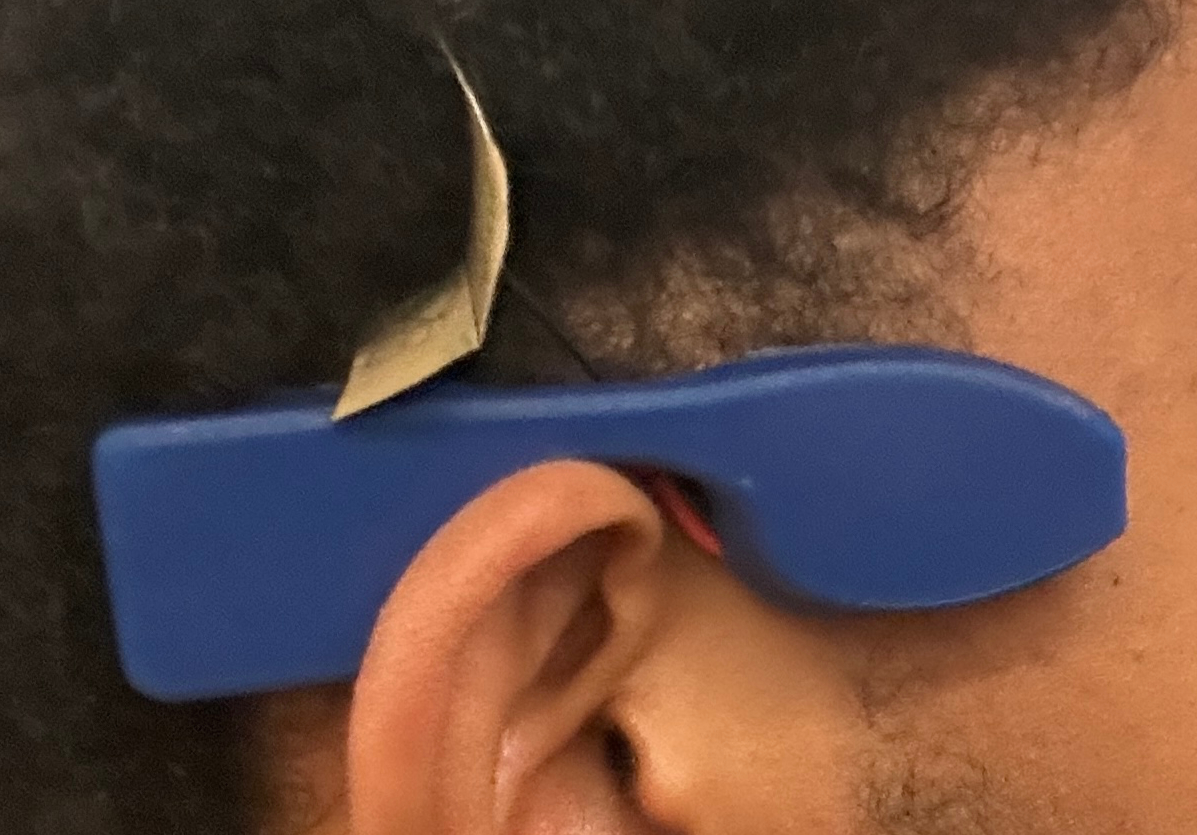
关键设计:在硬件设计方面,论文重点关注了如何在30克的外形尺寸内集成摄像头、麦克风和扬声器。在软件设计方面,论文采用了唤醒词触发的捕获机制,以降低功耗。此外,论文还对视觉-语言和大型语言模型进行了量化,以提高推理速度和降低内存占用。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
该研究成功构建了一个能够在商品移动硬件上进行完全本地多模态推理的可穿戴设备原型。初步评估表明,该系统能够在交互延迟下实现可用的性能,证明了本地AI推理在资源受限设备上的可行性。具体的性能数据和对比基线在摘要中未提供,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要隐私保护的可穿戴设备场景,例如:智能助手、健康监测、安全监控等。通过本地AI推理,用户可以在享受智能化服务的同时,避免个人数据泄露的风险。未来,该技术有望推动可穿戴设备在医疗、教育、工业等领域的广泛应用。
📄 摘要(原文)
Many promising applications of multimodal wearables require continuous sensing and heavy computation, yet users reject such devices due to privacy concerns. This paper shares our experiences building an ear-mounted voice-and-vision wearable that performs local AI inference using a paired smartphone as a trusted personal edge. We describe the hardware-software co-design of this privacy-preserving system, including challenges in integrating a camera, microphone, and speaker within a 30-gram form factor, enabling wake word-triggered capture, and running quantized vision-language and large-language models entirely offline. Through iterative prototyping, we identify key design hurdles in power budgeting, connectivity, latency, and social acceptability. Our initial evaluation shows that fully local multimodal inference is feasible on commodity mobile hardware with interactive latency. We conclude with design lessons for researchers developing embedded AI systems that balance privacy, responsiveness, and usability in everyday settings.