Policy Optimization for Unknown Systems using Differentiable Model Predictive Control
作者: Riccardo Zuliani, Efe C. Balta, John Lygeros
分类: eess.SY, math.OC
发布日期: 2025-11-14
💡 一句话要点
提出结合可微优化与零阶优化的MPC策略优化框架,解决未知系统控制问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模型预测控制 策略优化 可微优化 零阶优化 梯度估计 四旋翼控制 不确定系统
📋 核心要点
- 基于模型的策略优化易受系统动力学模型不准确的影响,导致闭环性能下降,尤其是在MPC策略中。
- 该方法结合可微优化与零阶优化,融合基于模型和无模型的梯度估计,加速瞬态性能并保证收敛性。
- 在12维四旋翼模型的非线性控制任务中验证了该方法的有效性,表明其在模型不确定性下的优越性。
📝 摘要(中文)
本文提出了一种针对基于模型预测控制(MPC)策略的优化框架,该框架结合了可微优化和零阶优化方法,以应对系统动力学模型不准确的问题。模型不准确会严重影响基于模型的策略优化,尤其是在MPC策略中,因为MPC依赖模型进行实时轨迹规划和优化。该方法融合了基于模型和无模型的梯度估计方法,与完全数据驱动的方法相比,实现了更快的瞬态性能,同时保持了收敛性保证,即使在模型不确定性下也能有效工作。在涉及12维四旋翼模型的非线性控制任务中,验证了所提出方法的有效性。
🔬 方法详解
问题定义:论文旨在解决模型预测控制(MPC)在未知或不确定系统中的策略优化问题。现有MPC方法依赖于精确的系统动力学模型,但在实际应用中,模型往往存在误差,导致控制性能下降,甚至系统不稳定。传统的策略优化方法要么依赖于精确的模型梯度,要么完全依赖数据驱动,前者对模型误差敏感,后者收敛速度慢,样本效率低。
核心思路:论文的核心思路是结合基于模型的梯度信息和无模型的梯度估计,利用可微优化和零阶优化方法,构建一个混合的策略优化框架。通过融合两种梯度信息,可以利用模型提供的先验知识加速学习过程,同时利用数据驱动的方法修正模型误差,提高策略的鲁棒性和泛化能力。
技术框架:该框架主要包含以下几个模块:1) 可微分MPC:使用可微分的优化求解器实现MPC策略,以便计算策略关于模型参数和控制输入的梯度。2) 基于模型的梯度估计:利用可微分MPC计算策略关于模型参数的梯度,用于指导模型参数的更新。3) 零阶优化:使用无梯度优化方法(如有限差分法或进化策略)估计策略关于控制输入的梯度,用于修正模型误差。4) 混合梯度更新:将基于模型的梯度和无模型的梯度进行加权融合,用于更新策略参数。
关键创新:该方法最重要的创新点在于混合梯度估计策略。它不像传统方法那样完全依赖模型或数据,而是将两者结合起来,充分利用了模型提供的先验知识和数据驱动的修正能力。这种混合方法可以在保证收敛性的前提下,显著提高学习效率和鲁棒性。
关键设计:关键设计包括:1) 可微分MPC的实现,需要选择合适的可微分优化求解器,并设计合适的损失函数和约束条件。2) 梯度融合的权重设计,需要根据模型误差的大小和数据质量进行调整,以平衡模型和数据驱动的贡献。3) 零阶优化方法的选择,需要考虑计算复杂度和样本效率,选择合适的优化算法和步长。
🖼️ 关键图片
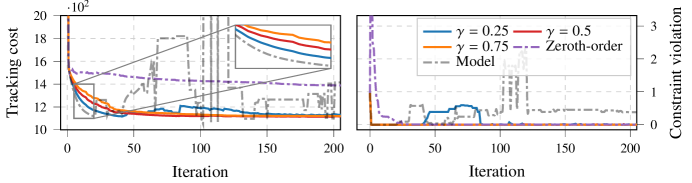
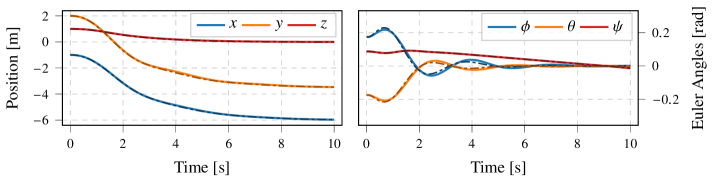
📊 实验亮点
实验结果表明,该方法在四旋翼飞行器的非线性控制任务中表现出色。与传统的基于模型的MPC方法相比,该方法能够更快地收敛到最优策略,并具有更强的鲁棒性,能够有效应对模型不确定性。具体而言,该方法在瞬态性能方面优于完全数据驱动的方法,同时保持了收敛性保证,验证了其在复杂控制任务中的有效性。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、飞行器控制等领域,尤其是在系统模型不确定或难以精确建模的场景下。例如,在复杂地形下的机器人导航、未知环境中的无人机飞行、以及存在干扰的车辆控制等。该方法能够提高控制系统的鲁棒性和适应性,降低对精确模型的依赖,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Model-based policy optimization often struggles with inaccurate system dynamics models, leading to suboptimal closed-loop performance. This challenge is especially evident in Model Predictive Control (MPC) policies, which rely on the model for real-time trajectory planning and optimization. We introduce a novel policy optimization framework for MPC-based policies combining differentiable optimization with zeroth-order optimization. Our method combines model-based and model-free gradient estimation approaches, achieving faster transient performance compared to fully data-driven approaches while maintaining convergence guarantees, even under model uncertainty. We demonstrate the effectiveness of the proposed approach on a nonlinear control task involving a 12-dimensional quadcopter model.