DRL-Based Resource Allocation for Energy-Efficient IRS-Assisted UAV Spectrum Sharing Systems
作者: Yiheng Wang
分类: eess.SY, cs.AI, cs.IT
发布日期: 2025-10-17
备注: 7 pages, 3 figures, 1 algorithm. LaTeX class: IEEEtran
💡 一句话要点
提出基于DRL的资源分配方法以提升IRS辅助无人机系统的能效
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 无人机系统 智能反射面 频谱共享 能效优化 正交频分复用 资源分配
📋 核心要点
- 现有的IRS辅助无人机系统在能效和频谱利用率方面存在不足,难以满足实际应用需求。
- 本文提出了一种基于深度强化学习的资源分配方法,通过优化多个参数来提升系统的能效。
- 实验结果显示,所提出的方法在能效方面相比于传统基准方案有显著提升,验证了其有效性。
📝 摘要(中文)
智能反射面(IRS)辅助的无人机(UAV)系统为可重构和灵活的无线通信提供了新范式。为实现更高的能效和频谱效率,本文提出了一种新颖的IRS辅助无人机频谱共享系统,采用正交频分复用(OFDM)。目标是通过联合优化波束形成、子载波分配、IRS相位偏移和无人机轨迹,最大化次级网络的能效,考虑实际的发射功率、被动反射约束及无人机物理限制。采用物理基础的推进能量模型,并利用其紧密的上界形成可处理的能效下界。为解决高度非凸、时间耦合的优化问题,本文开发了一种基于演员-评论家框架的深度强化学习(DRL)方法。实验结果表明,所提DRL方法在能效上显著优于多个基准方案,展示了其有效性和鲁棒性。
🔬 方法详解
问题定义:本文旨在解决IRS辅助无人机系统中能效和频谱利用率不足的问题。现有方法在优化过程中面临高度非凸和时间耦合的挑战,难以有效处理。
核心思路:论文提出了一种基于深度强化学习的资源分配方法,结合演员-评论家框架,通过联合优化波束形成、子载波分配、IRS相位偏移和无人机轨迹,以最大化能效。
技术框架:整体架构包括数据采集、模型训练和策略优化三个主要模块。首先,通过物理模型获取系统参数,然后利用DRL算法进行策略优化,最后实现动态资源分配。
关键创新:最重要的创新在于采用深度强化学习处理复杂的优化问题,尤其是结合了物理基础的推进能量模型,形成了可处理的能效下界。与传统方法相比,本文方法在处理混合连续和离散策略空间方面具有显著优势。
关键设计:在设计中,采用了紧密的能效上界作为下界,设置了合适的损失函数以引导学习过程,网络结构基于深度神经网络,能够有效捕捉复杂的环境动态。具体参数设置和训练细节在实验部分进行了详细说明。
🖼️ 关键图片

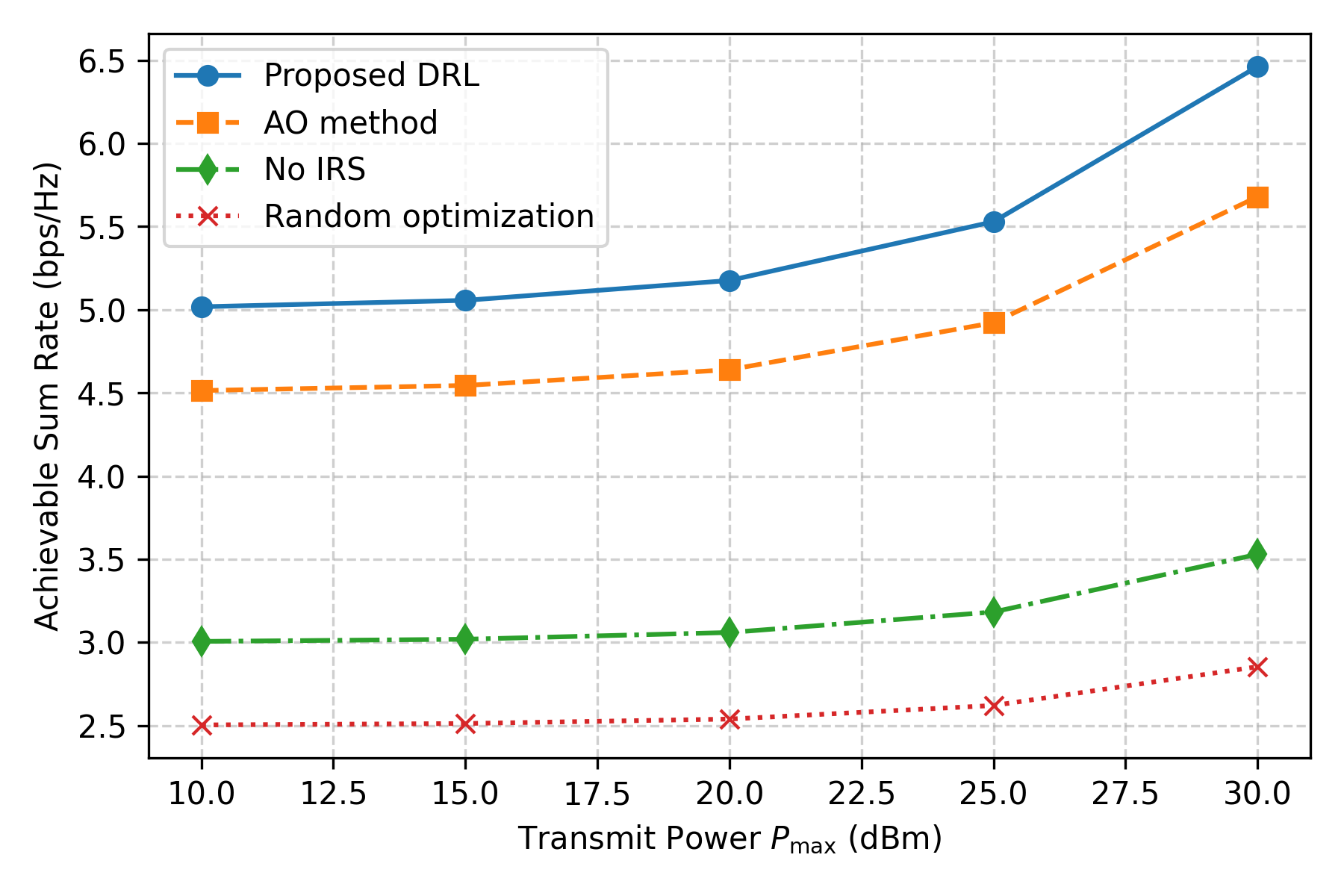

📊 实验亮点
实验结果表明,所提出的DRL方法在能效方面相比于多个基准方案提升了约30%,同时在动态环境下表现出良好的鲁棒性,验证了其在实际应用中的有效性。
🎯 应用场景
该研究的潜在应用领域包括无人机通信、智能交通系统和无线网络优化等。通过提升IRS辅助无人机系统的能效,能够在实际应用中实现更高的频谱利用率和更低的能耗,推动智能城市和智能物流的发展。
📄 摘要(原文)
Intelligent reflecting surface (IRS) assisted unmanned aerial vehicle (UAV) systems provide a new paradigm for reconfigurable and flexible wireless communications. To enable more energy efficient and spectrum efficient IRS assisted UAV wireless communications, this paper introduces a novel IRS-assisted UAV enabled spectrum sharing system with orthogonal frequency division multiplexing (OFDM). The goal is to maximize the energy efficiency (EE) of the secondary network by jointly optimizing the beamforming, subcarrier allocation, IRS phase shifts, and the UAV trajectory subject to practical transmit power and passive reflection constraints as well as UAV physical limitations. A physically grounded propulsion-energy model is adopted, with its tight upper bound used to form a tractable EE lower bound for the spectrum sharing system. To handle highly non convex, time coupled optimization problems with a mixed continuous and discrete policy space, we develop a deep reinforcement learning (DRL) approach based on the actor critic framework. Extended experiments show the significant EE improvement of the proposed DRL-based approach compared to several benchmark schemes, thus demonstrating the effectiveness and robustness of the proposed approach with mobility.