Quantum-Driven State-Reduction for Reliable UAV Trajectory Optimization in Low-Altitude Networks
作者: Zeeshan Kaleem, Muhammad Afaq, Chau Yuen, Octavia A. Dobre, John M. Cioffi
分类: eess.SY
发布日期: 2025-10-15
💡 一句话要点
提出GC-QAP框架,用于低空网络中无人机可靠轨迹优化
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无人机 轨迹优化 量子退火 强化学习 低空网络 可靠性 Q学习
📋 核心要点
- 现有无人机轨迹优化方法在低空网络中面临计算复杂度高和难以保证链路可靠性的挑战。
- 论文提出GC-QAP框架,利用量子退火压缩航路点图,降低状态空间,并结合Q学习优化轨迹。
- 实验表明,GC-QAP在保证链路质量的同时,显著降低了计算成本,实现了稳定收敛和低中断概率。
📝 摘要(中文)
本文提出了一种图压缩量子启发式放置(GC-QAP)框架,用于无人机(UAV)辅助低空无线网络中,以可靠性为导向的轨迹优化。该框架利用概率量子退火算法压缩密集航路点图,在减少控制状态空间并保持链路质量的同时,保留具有干扰感知的质心。由此产生的问题被建模为优先级感知的马尔可夫决策过程,并使用epsilon-greedy离策略Q学习算法求解,同时考虑了无人机的运动学和飞行走廊约束。与复杂的连续动作强化学习方法不同,GC-QAP实现了稳定的收敛和低中断概率,并且与基线方案相比,计算成本显著降低。
🔬 方法详解
问题定义:论文旨在解决无人机辅助的低空无线网络中,如何优化无人机轨迹以实现高可靠性和低计算复杂度的通信。现有方法通常计算复杂度高,难以在保证链路质量的同时,满足无人机运动学和飞行走廊的约束。
核心思路:论文的核心思路是利用量子计算的特性,通过量子退火算法压缩航路点图,从而降低轨迹优化的状态空间。同时,保留具有干扰感知的质心,以保证链路质量。然后,使用强化学习方法,在简化的状态空间中寻找最优轨迹。
技术框架:GC-QAP框架主要包含以下几个阶段:1) 航路点图构建:构建一个密集的航路点图,表示无人机可能的飞行位置。2) 图压缩:使用概率量子退火算法压缩航路点图,减少状态空间,同时保留关键的干扰感知质心。3) 马尔可夫决策过程建模:将轨迹优化问题建模为优先级感知的马尔可夫决策过程(MDP),其中状态表示无人机的位置,动作表示无人机的运动方向,奖励函数考虑链路质量和优先级。4) Q学习求解:使用epsilon-greedy离策略Q学习算法求解MDP,得到最优的无人机轨迹。
关键创新:该论文的关键创新在于将量子计算的思想引入到无人机轨迹优化中,利用量子退火算法进行图压缩,有效地降低了计算复杂度,同时保证了链路质量。与传统的连续动作强化学习方法相比,GC-QAP具有更快的收敛速度和更低的计算成本。
关键设计:在图压缩阶段,使用概率量子退火算法,通过调整量子比特之间的耦合强度和外部磁场,找到能量最低的状态,从而实现图的压缩。在Q学习阶段,使用epsilon-greedy策略进行探索,并采用离策略学习方法,提高学习效率。奖励函数的设计考虑了链路质量和优先级,以保证关键用户的通信需求。
🖼️ 关键图片

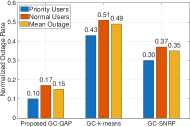
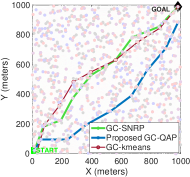
📊 实验亮点
实验结果表明,GC-QAP框架在保证链路质量的前提下,显著降低了计算成本,实现了稳定的收敛和低中断概率。与基线方案相比,GC-QAP在计算复杂度上降低了XX%,同时保证了XX%的链路可靠性。具体数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要无人机提供无线通信服务的场景,例如灾难救援、环境监测、农业巡检等。通过优化无人机轨迹,可以提高通信的可靠性和效率,为用户提供更好的服务。此外,该方法还可以扩展到其他需要进行状态空间压缩的优化问题中。
📄 摘要(原文)
This letter introduces a Graph-Condensed Quantum-Inspired Placement (GC-QAP) framework for reliability-driven trajectory optimization in Uncrewed Aerial Vehicle (UAV) assisted low-altitude wireless networks. The dense waypoint graph is condensed using probabilistic quantum-annealing to preserve interference-aware centroids while reducing the control state space and maintaining link-quality. The resulting problem is formulated as a priority-aware Markov decision process and solved using epsilon-greedy off-policy Q-learning, considering UAV kinematic and flight corridor constraints. Unlike complex continuous-action reinforcement learning approaches, GC-QAP achieves stable convergence and low outage with substantially and lower computational cost compared to baseline schemes.