Efficient LLM Inference over Heterogeneous Edge Networks with Speculative Decoding
作者: Bingjie Zhu, Zhixiong Chen, Liqiang Zhao, Hyundong Shin, Arumugam Nallanathan
分类: eess.SY
发布日期: 2025-10-13
💡 一句话要点
提出基于推测解码的异构边缘网络LLM高效推理框架,降低服务延迟。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 边缘计算 推测解码 异构网络 资源分配
📋 核心要点
- 现有边缘LLM推理系统采用自回归解码,每次前向传播仅生成一个token,导致服务延迟高,难以支持多用户。
- 提出基于推测解码的LLM服务框架,利用小型模型快速生成草稿,大型模型并行验证,实现多token生成。
- 实验结果表明,该框架相比自回归解码系统降低了服务延迟,联合优化方法降低了高达44.9%的延迟。
📝 摘要(中文)
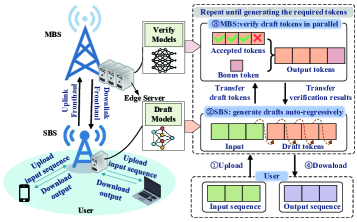
本文提出了一种基于推测解码(SD)的LLM服务框架,用于在异构边缘网络上高效地进行LLM推理。该框架利用小型模型快速生成草稿token,并由大型模型并行验证,从而实现每个前向传播生成多个token,降低服务延迟。为了提高边缘节点的资源利用率,本文采用流水线并行来重叠多个推理任务的草稿生成和验证过程。基于此框架,分析并推导了一个包含通信和推理延迟的综合延迟模型。然后,制定了一个联合优化问题,用于优化推测长度、任务批处理和无线通信资源分配,以最小化总服务延迟。针对该问题,推导了无线通信资源分配的闭式解,并开发了一种动态规划算法,用于联合批处理和推测控制策略。实验结果表明,与基于自回归解码(AD)的服务系统相比,所提出的框架实现了更低的服务延迟。此外,与基准方案相比,所提出的联合优化方法可降低高达44.9%的延迟。
🔬 方法详解
问题定义:论文旨在解决边缘网络中大型语言模型(LLM)推理服务延迟高的问题。现有的自回归解码(AD)方法在边缘节点计算资源有限的情况下,推理速度慢,无法满足日益增长的用户需求。
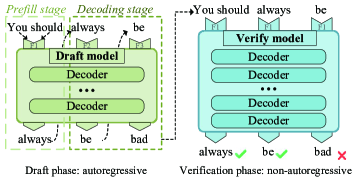
核心思路:论文的核心思路是利用推测解码(SD)技术,通过部署小型模型和大型模型协同工作,加速LLM推理过程。小型模型快速生成多个token作为草稿,然后由大型模型并行验证这些草稿的正确性,从而实现每个前向传播生成多个token,降低整体推理延迟。
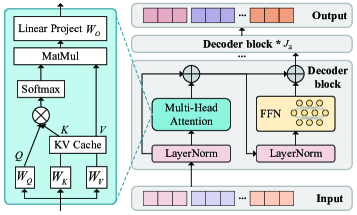
技术框架:该框架包含以下主要模块:1) 小型模型(Draft Model):部署在边缘节点上,负责快速生成token草稿。2) 大型模型(Verification Model):部署在更强大的边缘节点或云端,负责验证小型模型生成的草稿token。3) 推理任务调度器:负责将推理任务分配给不同的边缘节点,并协调小型模型和大型模型之间的通信。4) 资源分配模块:负责优化无线通信资源分配,以最小化通信延迟。整个流程包括:用户发起推理请求 -> 任务调度器分配任务 -> 小型模型生成草稿 -> 大型模型验证草稿 -> 返回结果给用户。
关键创新:论文的关键创新在于将推测解码技术应用于异构边缘网络中的LLM推理,并提出了一个联合优化框架,同时考虑了推测长度、任务批处理和无线通信资源分配,以最小化总服务延迟。与传统的自回归解码方法相比,该方法能够显著提高推理速度。
关键设计:论文的关键设计包括:1) 推测长度的动态调整:根据网络状况和模型性能动态调整推测长度,以平衡草稿生成速度和验证成本。2) 任务批处理策略:将多个推理任务合并成一个批次进行处理,以提高资源利用率。3) 无线通信资源分配:采用闭式解优化无线通信资源分配,以最小化通信延迟。4) 延迟模型:建立了一个综合延迟模型,考虑了通信延迟和推理延迟,为优化问题提供了理论基础。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的基于推测解码的LLM服务框架相比于基于自回归解码的服务系统,能够显著降低服务延迟。具体而言,所提出的联合优化方法与基准方案相比,实现了高达44.9%的延迟降低。这些结果验证了该框架在异构边缘网络中进行高效LLM推理的有效性。
🎯 应用场景
该研究成果可应用于各种边缘计算场景,例如智能家居、自动驾驶、智慧城市等,在这些场景中,需要在本地快速响应用户的自然语言请求。通过降低LLM推理延迟,可以提升用户体验,并支持更多实时性要求高的应用,例如本地语音助手、实时翻译等。未来,该技术有望推动边缘智能的发展,实现更高效、更安全的AI服务。
📄 摘要(原文)
Large language model (LLM) inference at the network edge is a promising serving paradigm that leverages distributed edge resources to run inference near users and enhance privacy. Existing edge-based LLM inference systems typically adopt autoregressive decoding (AD), which only generates one token per forward pass. This iterative process, compounded by the limited computational resources of edge nodes, results in high serving latency and constrains the system's ability to support multiple users under growing demands.To address these challenges, we propose a speculative decoding (SD)-based LLM serving framework that deploys small and large models across heterogeneous edge nodes to collaboratively deliver inference services. Specifically, the small model rapidly generates draft tokens that the large model verifies in parallel, enabling multi-token generation per forward pass and thus reducing serving latency. To improve resource utilization of edge nodes, we incorporate pipeline parallelism to overlap drafting and verification across multiple inference tasks. Based on this framework, we analyze and derive a comprehensive latency model incorporating both communication and inference latency. Then, we formulate a joint optimization problem for speculation length, task batching, and wireless communication resource allocation to minimize total serving latency. To address this problem, we derive the closed-form solutions for wireless communication resource allocation, and develop a dynamic programming algorithm for joint batching and speculation control strategies. Experimental results demonstrate that the proposed framework achieves lower serving latency compared to AD-based serving systems. In addition,the proposed joint optimization method delivers up to 44.9% latency reduction compared to benchmark schemes.