Falsification-Driven Reinforcement Learning for Maritime Motion Planning
作者: Marlon Müller, Florian Finkeldei, Hanna Krasowski, Murat Arcak, Matthias Althoff
分类: eess.SY, cs.LG
发布日期: 2025-10-08
💡 一句话要点
提出基于违规驱动的强化学习方法,提升自主船舶在复杂海况下的规则遵循能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自主船舶 运动规划 海上交通规则 违规驱动 信号时序逻辑 对抗训练
📋 核心要点
- 现有强化学习方法难以生成足够复杂的海上导航场景,导致自主船舶难以有效学习并遵守海上交通规则。
- 提出一种违规驱动的强化学习方法,通过生成对抗性场景,迫使智能体违反规则,从而学习如何避免违规行为。
- 实验表明,该方法能够生成更相关的训练场景,显著提升自主船舶在开放水域导航中对海上交通规则的遵守程度。
📝 摘要(中文)
自主船舶的安全运行至关重要,必须遵守海上交通规则。然而,训练强化学习(RL)智能体遵守这些规则极具挑战。RL智能体的行为受训练场景的影响,但创建能够捕捉海上导航复杂性的场景并非易事,且仅靠真实世界数据是不够的。为了解决这个问题,我们提出了一种违规驱动的RL方法,该方法生成对抗性训练场景,其中被测船舶违反了以信号时序逻辑规范表达的海上交通规则。在双船开放水域导航的实验表明,该方法提供了更相关的训练场景,并实现了更一致的规则遵守。
🔬 方法详解
问题定义:论文旨在解决自主船舶在复杂海上环境中,如何通过强化学习方法安全且有效地遵守海上交通规则的问题。现有方法依赖于预定义的或从真实数据中学习的场景,但这些场景往往无法充分覆盖所有可能的违规情况,导致训练出的智能体在实际应用中容易违反规则。
核心思路:论文的核心思路是利用“违规驱动”的方式来生成训练场景。具体来说,就是主动寻找并创建那些能够导致智能体违反海上交通规则的场景,迫使智能体在这些“逆境”中学习如何避免违规行为。这种方法类似于软件测试中的“fuzzing”,旨在发现并修复潜在的漏洞。
技术框架:整体框架包含两个主要部分:强化学习智能体和违规场景生成器。强化学习智能体负责学习导航策略,而违规场景生成器则负责根据智能体的当前策略,生成能够导致其违反海上交通规则的场景。这两个部分相互作用,形成一个对抗训练的循环。具体流程如下:1) 强化学习智能体根据当前策略执行导航任务;2) 违规场景生成器分析智能体的行为,并生成新的场景,使得智能体更容易违反规则;3) 智能体在新的场景中进行训练,学习如何避免违规行为;4) 重复以上步骤,直到智能体能够稳定地遵守海上交通规则。
关键创新:该论文的关键创新在于提出了“违规驱动”的训练方法。与传统的强化学习方法不同,该方法不是被动地依赖于预定义的或从真实数据中学习的场景,而是主动地生成对抗性场景,迫使智能体学习如何避免违规行为。这种方法能够更有效地发现并修复智能体中的潜在漏洞,从而提高其在实际应用中的安全性和可靠性。
关键设计:论文使用信号时序逻辑(STL)来形式化地描述海上交通规则。违规场景生成器通过优化一个目标函数来生成场景,该目标函数旨在最大化智能体违反STL规则的可能性。具体的优化方法未知,论文可能使用了梯度下降或其他优化算法。强化学习智能体可以使用任何合适的强化学习算法,例如DQN或PPO。具体的网络结构和超参数设置未知。
🖼️ 关键图片

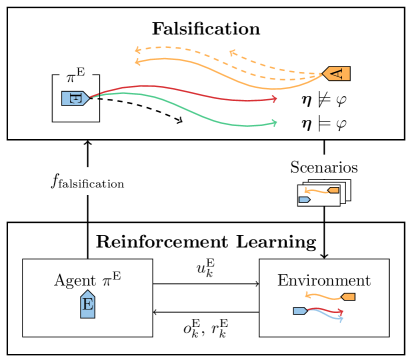

📊 实验亮点
该论文通过实验验证了所提出的违规驱动强化学习方法的有效性。实验结果表明,与传统的强化学习方法相比,该方法能够生成更相关的训练场景,并显著提升自主船舶在开放水域导航中对海上交通规则的遵守程度。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于自主船舶的运动规划与控制系统,提高其在复杂海况下的安全性和可靠性。此外,该方法也可推广到其他需要遵守规则的自主系统,例如自动驾驶汽车、无人机等。通过主动生成对抗性场景,可以更有效地训练这些系统,使其能够更好地应对各种复杂和不确定的环境。
📄 摘要(原文)
Compliance with maritime traffic rules is essential for the safe operation of autonomous vessels, yet training reinforcement learning (RL) agents to adhere to them is challenging. The behavior of RL agents is shaped by the training scenarios they encounter, but creating scenarios that capture the complexity of maritime navigation is non-trivial, and real-world data alone is insufficient. To address this, we propose a falsification-driven RL approach that generates adversarial training scenarios in which the vessel under test violates maritime traffic rules, which are expressed as signal temporal logic specifications. Our experiments on open-sea navigation with two vessels demonstrate that the proposed approach provides more relevant training scenarios and achieves more consistent rule compliance.