A Control-Barrier-Function-Based Algorithm for Policy Adaptation in Reinforcement Learning
作者: Wenjian Hao, Zehui Lu, Nicolas Miguel, Shaoshuai Mou
分类: eess.SY
发布日期: 2025-10-03
💡 一句话要点
提出基于控制障碍函数的策略自适应算法,解决强化学习中多目标权衡问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 策略自适应 控制障碍函数 约束优化 闭环控制
📋 核心要点
- 现有强化学习方法在策略调整时难以显式约束性能下降,导致策略自适应过程不稳定。
- 提出基于控制障碍函数的策略自适应方法,通过闭环控制确保策略参数演化满足性能约束。
- 在Cartpole、Lunar Lander和四足机器人等任务上验证了算法的有效性,展示了其在实际应用中的潜力。
📝 摘要(中文)
本文研究了策略自适应问题,即如何将一个预先设计的策略(由参数化函数类表示)从最小化原始代价函数的最优解调整为在最小化原始目标和附加代价函数之间进行权衡的解。该问题被形式化为一个约束优化问题,其中对原始代价函数最优值的偏差被显式约束。为了解决这个问题,我们开发了一个闭环系统来控制策略参数的演变,并设计了一个闭环控制器来调整附加代价梯度,以确保满足约束条件。由此产生的闭环系统,称为基于控制障碍函数的策略自适应,利用控制障碍函数的集合不变性来保证约束满足。通过OpenAI Gym中的Cartpole和Lunar Lander基准测试以及四足机器人的数值实验,证明了该方法的有效性,从而说明了其在实际策略自适应中的实用性和潜力。
🔬 方法详解
问题定义:论文旨在解决强化学习中策略自适应的问题,即如何在一个已有的策略基础上,引入新的目标函数,并在优化新目标的同时,保证原始策略的性能不会过度下降。现有方法通常难以显式地约束原始策略的性能损失,导致自适应后的策略可能偏离原始策略过远,甚至导致性能崩溃。
核心思路:论文的核心思路是将策略自适应问题转化为一个约束优化问题,并利用控制障碍函数(Control Barrier Function, CBF)来保证约束的满足。通过设计一个闭环控制器,动态调整附加代价函数的梯度,使得策略参数的演化始终保持在满足性能约束的区域内。
技术框架:整体框架包含以下几个主要部分:1) 定义原始代价函数和附加代价函数;2) 将策略自适应问题形式化为约束优化问题,其中约束条件是原始代价函数的性能损失小于一个预设的阈值;3) 设计基于控制障碍函数的闭环控制器,该控制器根据当前策略参数和性能约束,动态调整附加代价函数的梯度;4) 利用该控制器更新策略参数,实现策略的自适应。
关键创新:最重要的技术创新在于将控制障碍函数引入到强化学习的策略自适应中。控制障碍函数能够提供一种形式化的方法来保证约束的满足,从而避免了传统方法中需要手动调整参数或使用复杂的优化算法的问题。此外,闭环控制器的设计也保证了策略自适应过程的稳定性和鲁棒性。
关键设计:关键设计包括:1) 控制障碍函数的选择,需要保证其能够准确地反映性能约束;2) 闭环控制器的设计,需要保证其能够快速、准确地调整附加代价函数的梯度,同时避免引入额外的噪声或不稳定性;3) 策略参数的更新方式,需要保证其能够有效地利用控制器的输出,并实现策略的平滑自适应。
🖼️ 关键图片


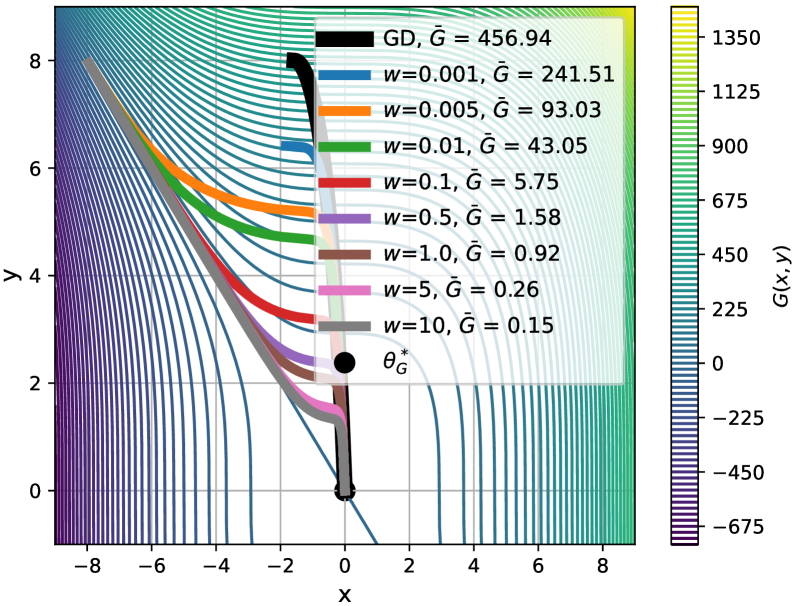
📊 实验亮点
论文通过在OpenAI Gym的Cartpole和Lunar Lander基准测试以及四足机器人上的实验,验证了所提出方法的有效性。实验结果表明,该方法能够在保证原始策略性能损失在可接受范围内的前提下,有效地优化附加代价函数。例如,在Lunar Lander任务中,该方法能够在保证着陆成功率的前提下,显著降低着陆时的冲击力。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、资源调度等领域。例如,在机器人控制中,可以利用该方法在保证机器人安全性的前提下,使其适应新的任务或环境。在自动驾驶中,可以在保证车辆行驶安全的前提下,优化车辆的行驶效率或舒适性。该方法具有广泛的应用前景,并有望推动强化学习在实际应用中的发展。
📄 摘要(原文)
This paper considers the problem of adapting a predesigned policy, represented by a parameterized function class, from a solution that minimizes a given original cost function to a trade-off solution between minimizing the original objective and an additional cost function. The problem is formulated as a constrained optimization problem, where deviations from the optimal value of the original cost are explicitly constrained. To solve it, we develop a closed-loop system that governs the evolution of the policy parameters, with a closed-loop controller designed to adjust the additional cost gradient to ensure the satisfaction of the constraint. The resulting closed-loop system, termed control-barrier-function-based policy adaptation, exploits the set-invariance property of control barrier functions to guarantee constraint satisfaction. The effectiveness of the proposed method is demonstrated through numerical experiments on the Cartpole and Lunar Lander benchmarks from OpenAI Gym, as well as a quadruped robot, thereby illustrating both its practicality and potential for real-world policy adaptation.