Off-Policy Reinforcement Learning with Anytime Safety Guarantees via Robust Safe Gradient Flow
作者: Pol Mestres, Arnau Marzabal, Jorge Cortés
分类: eess.SY
发布日期: 2025-10-01
💡 一句话要点
提出基于鲁棒安全梯度流的离线强化学习算法,实现任意时刻的安全保证
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 安全强化学习 离线强化学习 约束优化 鲁棒控制 梯度流 凸优化
📋 核心要点
- 现有约束强化学习方法难以保证在训练的每个阶段策略的安全性,存在探索风险。
- 论文提出基于鲁棒安全梯度流(RSGF)的离线强化学习算法,确保策略在任何迭代时刻都满足约束条件。
- 实验表明,RSGF-RL 在导航和倒立摆等任务上优于现有方法,验证了其安全性和有效性。
📝 摘要(中文)
本文研究了具有任意时刻安全保证的约束强化学习(RL)问题,即算法的解在演化的每个迭代步骤都必须产生满足约束的策略。我们的设计基于鲁棒安全梯度流(RSGF)的离散化,这是一种用于任意时刻约束优化的连续时间动力学,我们对其前向不变性和稳定性进行了形式化表征。所提出的策略,称为RSGF-RL,是一种离线算法,它使用 episodic 数据来估计价值函数及其梯度,并通过求解凸二次约束二次规划来更新策略参数。我们的技术分析结合了统计分析、随机逼近理论和凸分析,以确定足够的 episodes 数量,以确保安全策略被更新为安全策略,并从不安全策略中恢复,两者都具有任意用户指定的概率,并建立几乎必然地渐近收敛到 RL 问题的 KKT 点集。在导航示例和倒立摆系统上的仿真结果表明,RSGF-RL 相对于现有技术具有优越的性能。
🔬 方法详解
问题定义:论文旨在解决约束强化学习中,现有算法无法在训练的每个迭代步骤都保证策略安全性的问题。传统方法在探索过程中可能违反约束,导致系统进入危险状态,尤其是在安全攸关的应用中,这是一个严重的痛点。
核心思路:论文的核心思路是利用鲁棒安全梯度流(RSGF)的离散化版本来指导策略更新。RSGF 是一种连续时间动力学,其设计保证了前向不变性和稳定性,从而确保策略在更新过程中始终保持在安全区域内。通过离散化 RSGF,并将其应用于强化学习,可以在每个迭代步骤都获得满足约束的策略。
技术框架:RSGF-RL 算法是一个离线强化学习框架,主要包含以下几个模块:1) 数据收集:通过 episodic 数据收集环境信息。2) 价值函数估计:利用收集到的数据估计价值函数及其梯度。3) 策略更新:通过求解一个凸二次约束二次规划问题来更新策略参数,该优化问题基于 RSGF 的离散化形式,确保策略更新的方向是安全的。4) 安全性分析:利用统计分析、随机逼近理论和凸分析,证明算法的安全性,并确定收敛所需的 episodes 数量。
关键创新:论文的关键创新在于将鲁棒安全梯度流(RSGF)的概念引入到离线强化学习中,并设计了 RSGF-RL 算法。与现有方法相比,RSGF-RL 能够提供任意时刻的安全保证,即在训练的每个阶段,策略都满足约束条件。此外,论文还提供了严格的理论分析,证明了算法的安全性、收敛性和样本复杂度。
关键设计:RSGF-RL 算法的关键设计包括:1) 使用凸二次约束二次规划来更新策略参数,确保策略更新的方向是安全的。2) 利用 episodic 数据估计价值函数及其梯度,实现离线学习。3) 通过调整 RSGF 的参数,可以控制策略更新的保守程度,从而在安全性和性能之间进行权衡。4) 论文给出了确定 episodes 数量的公式,以确保安全策略被更新为安全策略,并从不安全策略中恢复,具有用户指定的概率。
🖼️ 关键图片
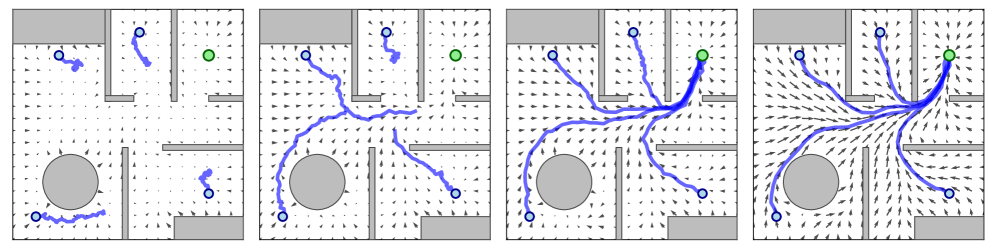
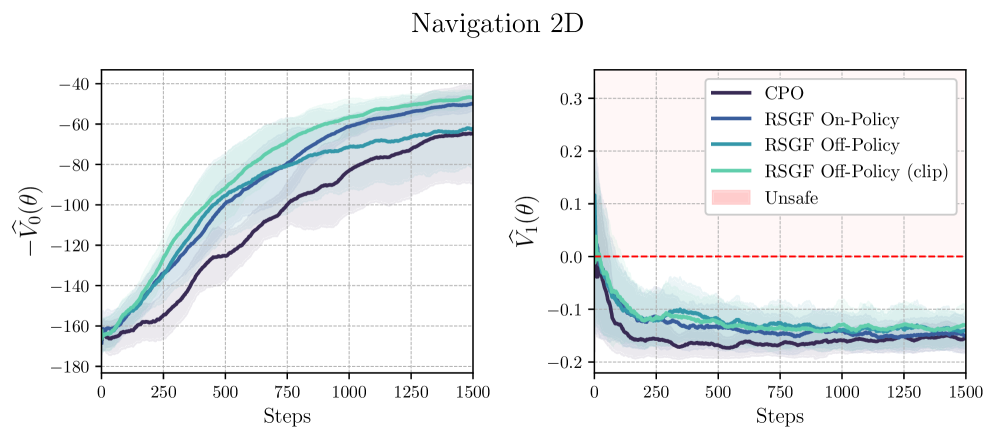
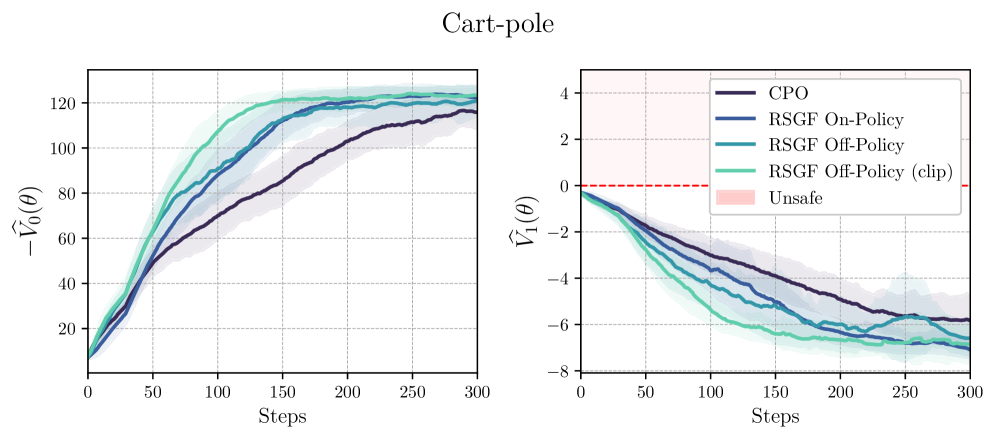
📊 实验亮点
实验结果表明,RSGF-RL 在导航和倒立摆等任务上优于现有方法。具体来说,在导航任务中,RSGF-RL 能够更快地找到安全路径,并避免进入危险区域。在倒立摆任务中,RSGF-RL 能够更稳定地控制摆杆,并保持其平衡。这些结果验证了 RSGF-RL 的安全性和有效性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、资源分配等安全攸关的领域。例如,在机器人导航中,可以保证机器人在规划路径时始终避开危险区域;在自动驾驶中,可以确保车辆在行驶过程中遵守交通规则,避免发生碰撞。该方法具有重要的实际应用价值,并有望推动安全强化学习的发展。
📄 摘要(原文)
This paper considers the problem of solving constrained reinforcement learning (RL) problems with anytime guarantees, meaning that the algorithmic solution must yield a constraint-satisfying policy at every iteration of its evolution. Our design is based on a discretization of the Robust Safe Gradient Flow (RSGF), a continuous-time dynamics for anytime constrained optimization whose forward invariance and stability properties we formally characterize. The proposed strategy, termed RSGF-RL, is an off-policy algorithm which uses episodic data to estimate the value functions and their gradients and updates the policy parameters by solving a convex quadratically constrained quadratic program. Our technical analysis combines statistical analysis, the theory of stochastic approximation, and convex analysis to determine the number of episodes sufficient to ensure that safe policies are updated to safe policies and to recover from an unsafe policy, both with an arbitrary user-specified probability, and to establish the asymptotic convergence to the set of KKT points of the RL problem almost surely. Simulations on a navigation example and the cart-pole system illustrate the superior performance of RSGF-RL with respect to the state of the art.