Comparative Field Deployment of Reinforcement Learning and Model Predictive Control for Residential HVAC
作者: Ozan Baris Mulayim, Elias N. Pergantis, Levi D. Reyes Premer, Bingqing Chen, Guannan Qu, Kevin J. Kircher, Mario Bergés
分类: eess.SY, cs.LG
发布日期: 2025-10-01
备注: 27 pages, 11 figures, 4 tables. Under review for Applied Energy
💡 一句话要点
强化学习与模型预测控制在住宅暖通空调系统中的实地部署对比研究
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型预测控制 暖通空调 能源效率 智能家居
📋 核心要点
- 现有暖通空调控制方法工程投入大,可扩展性受限,而强化学习在实际住宅应用中面临安全性、可解释性和样本效率等挑战。
- 论文对比研究了模型预测控制(MPC)和基于模型的强化学习(RL)控制器,旨在探索它们在实际住宅环境中的可扩展性和性能。
- 实验结果表明,RL在节能方面略优于MPC,但舒适度略有下降;当考虑舒适度时,MPC表现更优,揭示了RL在实际应用中的权衡。
📝 摘要(中文)
模型预测控制(MPC)等先进控制策略能显著节省暖通空调系统的能源,但通常需要大量的工程投入,限制了其可扩展性。强化学习(RL)有望实现更高的自动化和适应性,但其在现实住宅环境中的实际应用仍未得到充分验证,面临着安全性、可解释性和样本效率等挑战。为了研究这些实际问题,我们对MPC和基于模型的RL控制器进行了直接比较,每个控制器在印第安纳州西拉法叶的一栋有人居住的房屋中部署了一个月。这项研究旨在探索所选RL和MPC实现的可扩展性,同时确保安全性和可比性。先进的控制器相互评估,并与现有控制器进行比较。RL实现了显著的节能效果(相对于现有控制器节省22%),略高于MPC的节能效果(20%),但居住者的不适感略有增加。然而,当能源节省量根据所提供的舒适度进行标准化时,MPC表现出更优越的性能。这项研究的实证结果表明,虽然RL降低了工程开销,但它在模型准确性和运行鲁棒性方面引入了实际的权衡。从中吸取的主要教训涉及安全控制器初始化的困难、控制动作与其在实际实施中的不匹配,以及在实际环境中保持在线学习的完整性。这些见解指出了将RL从一个有希望的概念发展成为真正可扩展的HVAC控制解决方案所需的基本研究方向。
🔬 方法详解
问题定义:论文旨在解决住宅暖通空调(HVAC)系统中能源效率和舒适度之间的优化问题。现有方法,如传统控制策略,往往效率低下。模型预测控制(MPC)虽然能提高效率,但需要大量工程投入,难以扩展。强化学习(RL)有潜力自动化控制并适应环境变化,但其在实际住宅环境中的应用面临安全性、可解释性和样本效率等挑战。
核心思路:论文的核心思路是通过实地部署和对比实验,直接比较MPC和RL控制器在真实住宅环境中的性能。通过这种方式,可以量化两种方法在节能、舒适度和工程开销方面的优劣,并识别RL在实际应用中面临的关键挑战。这种对比研究有助于指导未来的研究方向,推动RL在HVAC控制领域的应用。
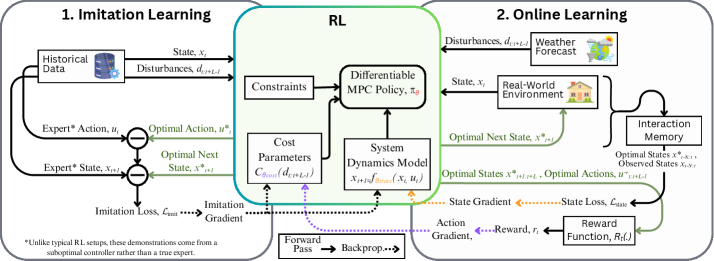
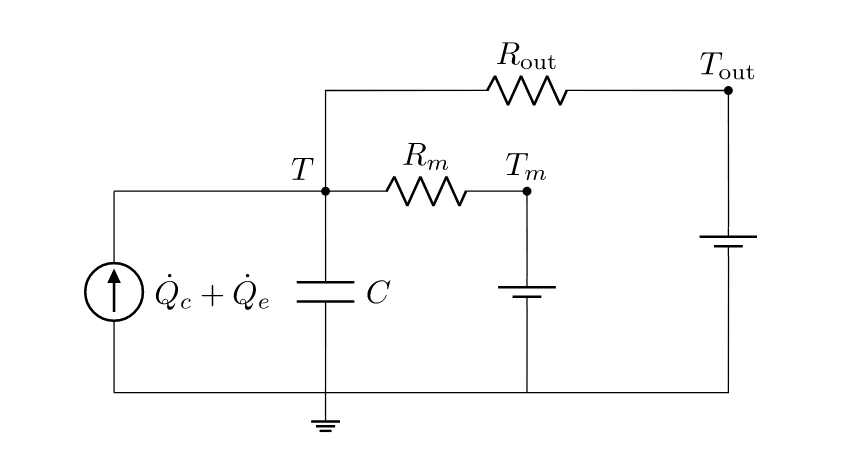
技术框架:研究采用的整体框架包括以下几个主要阶段:1) 选择合适的住宅环境并安装必要的传感器和执行器;2) 分别设计和实现MPC和RL控制器;3) 将两种控制器分别部署在一个月的周期内,并收集相关数据;4) 对收集到的数据进行分析,比较两种控制器在节能、舒适度和鲁棒性方面的性能。RL控制器采用基于模型的强化学习方法,利用环境模型进行策略学习。
关键创新:论文的关键创新在于首次在真实住宅环境中对MPC和RL控制器进行直接的实地对比。以往的研究大多集中在仿真环境或实验室环境中,缺乏对实际应用中各种复杂因素的考虑。通过实地部署,论文能够更真实地评估两种方法在节能、舒适度和鲁棒性方面的性能,并识别RL在实际应用中面临的关键挑战,例如安全初始化、控制动作与实际执行的不匹配以及在线学习的稳定性。
关键设计:RL控制器采用基于模型的强化学习算法,具体算法细节未知。MPC控制器采用标准模型预测控制框架,需要建立精确的HVAC系统模型。实验中,舒适度通过室内温度与设定温度的偏差来衡量。节能效果通过比较不同控制策略下的能源消耗量来评估。安全初始化通过限制控制动作的范围来实现。在线学习的稳定性通过监控策略的性能变化来评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RL控制器相对于现有控制器实现了22%的节能效果,略高于MPC控制器的20%。然而,在考虑舒适度因素后,MPC表现出更优越的性能。该研究揭示了RL在实际应用中面临的挑战,例如安全初始化、控制动作与实际执行的不匹配以及在线学习的稳定性,为未来的研究提供了重要的指导。
🎯 应用场景
该研究成果可应用于智能家居、楼宇自动化和能源管理等领域。通过优化暖通空调系统的控制策略,可以显著降低能源消耗,减少碳排放,提高居住舒适度。未来的研究可以进一步探索如何提高RL控制器的安全性和鲁棒性,使其能够更好地适应各种实际环境,从而实现更广泛的应用。
📄 摘要(原文)
Advanced control strategies like Model Predictive Control (MPC) offer significant energy savings for HVAC systems but often require substantial engineering effort, limiting scalability. Reinforcement Learning (RL) promises greater automation and adaptability, yet its practical application in real-world residential settings remains largely undemonstrated, facing challenges related to safety, interpretability, and sample efficiency. To investigate these practical issues, we performed a direct comparison of an MPC and a model-based RL controller, with each controller deployed for a one-month period in an occupied house with a heat pump system in West Lafayette, Indiana. This investigation aimed to explore scalability of the chosen RL and MPC implementations while ensuring safety and comparability. The advanced controllers were evaluated against each other and against the existing controller. RL achieved substantial energy savings (22\% relative to the existing controller), slightly exceeding MPC's savings (20\%), albeit with modestly higher occupant discomfort. However, when energy savings were normalized for the level of comfort provided, MPC demonstrated superior performance. This study's empirical results show that while RL reduces engineering overhead, it introduces practical trade-offs in model accuracy and operational robustness. The key lessons learned concern the difficulties of safe controller initialization, navigating the mismatch between control actions and their practical implementation, and maintaining the integrity of online learning in a live environment. These insights pinpoint the essential research directions needed to advance RL from a promising concept to a truly scalable HVAC control solution.