Reinforcement Learning Based Traffic Signal Design to Minimize Queue Lengths
作者: Anirud Nandakumar, Chayan Banerjee, Lelitha Devi Vanajakshi
分类: eess.SY, cs.LG
发布日期: 2025-09-26
💡 一句话要点
提出基于PPO强化学习的交通信号灯优化方法,最小化车辆排队长度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 交通信号控制 近端策略优化 车辆排队长度 智能交通系统
📋 核心要点
- 传统交通信号控制方法难以适应动态交通变化,导致拥堵和延误。
- 利用PPO强化学习算法,通过多种状态表示方法,最小化交通信号相位上的车辆排队长度。
- 实验结果表明,该方法在SUMO仿真中优于传统方法,平均排队长度减少约29%。
📝 摘要(中文)
高效的交通信号控制(TSC)对于减少拥堵、延误、污染和确保道路安全至关重要。传统的固定信号控制和感应控制方法难以应对动态交通模式。本研究提出了一种新的自适应TSC框架,该框架利用强化学习(RL),使用近端策略优化(PPO)算法,以最小化所有信号相位上的总排队长度。通过多种状态表示,包括扩展状态空间、自编码器表示和受K-Planes启发的表示,解决了为RL控制器有效表示高度随机交通状况的挑战。该算法已使用城市交通模拟器(SUMO)实现,并证明了其在减少排队长度方面优于传统方法和其他基于RL的传统方法。最佳配置比传统的韦伯斯特方法减少了约29%的平均排队长度。此外,对替代奖励函数的比较评估证明了所提出的基于队列的方法的有效性,展示了可扩展和自适应城市交通管理的潜力。
🔬 方法详解
问题定义:论文旨在解决城市交通信号控制问题,目标是减少车辆排队长度,缓解交通拥堵。现有方法,如固定配时和感应控制,无法有效应对动态变化的交通流量,导致效率低下。传统的强化学习方法在处理高维、随机的交通状态空间时面临挑战。
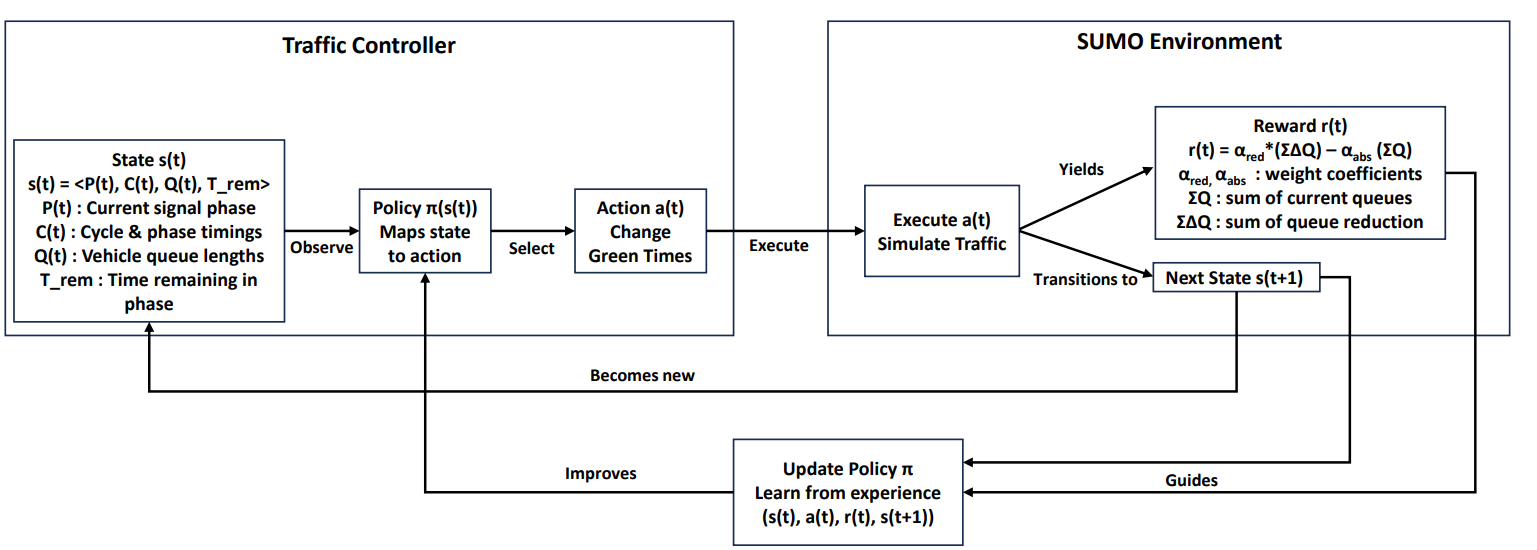
核心思路:论文的核心思路是利用强化学习,通过智能体与交通环境的交互,学习最优的交通信号控制策略。通过PPO算法优化信号配时,以最小化车辆排队长度。关键在于设计有效的状态表示方法,使智能体能够准确感知交通状况,并做出合理的决策。
技术框架:整体框架包括:1) 使用SUMO交通仿真器模拟交通环境;2) 定义状态空间,包括车辆排队长度、车辆速度等信息;3) 使用PPO算法训练强化学习智能体,智能体根据当前状态选择交通信号相位;4) 定义奖励函数,鼓励智能体减少排队长度;5) 评估智能体的性能,并与传统方法进行比较。论文探索了三种状态表示方法:扩展状态空间、自编码器表示和K-Planes启发式表示。
关键创新:论文的关键创新在于提出了多种状态表示方法,以更有效地表示复杂的交通状态。相比于传统的直接使用车辆数量作为状态,这些方法能够提取更抽象、更鲁棒的特征。此外,论文还探索了不同的奖励函数设计,发现基于排队长度的奖励函数能够取得更好的效果。
关键设计:论文使用PPO算法作为强化学习算法,PPO算法是一种策略梯度算法,具有较好的稳定性和收敛性。状态空间的设计是关键,论文尝试了扩展状态空间(直接使用排队长度)、自编码器表示(学习交通状态的低维表示)和K-Planes启发式表示(将状态空间划分为多个区域)。奖励函数的设计也至关重要,论文比较了基于排队长度、车辆等待时间和通行量的奖励函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于PPO强化学习的交通信号控制方法在SUMO仿真环境中优于传统的韦伯斯特方法。最佳配置下,平均排队长度减少了约29%。此外,通过比较不同的状态表示方法和奖励函数设计,验证了所提出的基于排队长度的奖励函数和K-Planes启发式状态表示方法的有效性。
🎯 应用场景
该研究成果可应用于城市智能交通管理系统,通过自适应调整交通信号灯配时,有效减少交通拥堵,提高道路通行效率,降低车辆尾气排放,改善城市空气质量。未来可扩展到更大规模的交通网络,并与其他智能交通技术相结合,实现更智能化的交通管理。
📄 摘要(原文)
Efficient traffic signal control (TSC) is crucial for reducing congestion, travel delays, pollution, and for ensuring road safety. Traditional approaches, such as fixed signal control and actuated control, often struggle to handle dynamic traffic patterns. In this study, we propose a novel adaptive TSC framework that leverages Reinforcement Learning (RL), using the Proximal Policy Optimization (PPO) algorithm, to minimize total queue lengths across all signal phases. The challenge of efficiently representing highly stochastic traffic conditions for an RL controller is addressed through multiple state representations, including an expanded state space, an autoencoder representation, and a K-Planes-inspired representation. The proposed algorithm has been implemented using the Simulation of Urban Mobility (SUMO) traffic simulator and demonstrates superior performance over both traditional methods and other conventional RL-based approaches in reducing queue lengths. The best performing configuration achieves an approximately 29% reduction in average queue lengths compared to the traditional Webster method. Furthermore, comparative evaluation of alternative reward formulations demonstrates the effectiveness of the proposed queue-based approach, showcasing the potential for scalable and adaptive urban traffic management.