CollaPipe: Adaptive Segment-Optimized Pipeline Parallelism for Collaborative LLM Training in Heterogeneous Edge Networks
作者: Jiewei Chen, Xiumei Deng, Zehui Xiong, Shaoyong Guo, Xuesong Qiu, Ping Wang, Dusit Niyato
分类: eess.SY, cs.AI, cs.NI
发布日期: 2025-09-24
备注: Submitted to IEEE for review
💡 一句话要点
CollaPipe:异构边缘网络中面向协同LLM训练的自适应分段优化流水线并行
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 大型语言模型 流水线并行 联邦学习 异构网络 模型分段 自适应优化
📋 核心要点
- 现有方法难以在移动边缘计算(MEC)网络中高效训练大型语言模型(LLM),面临计算量大、端到端延迟高和模型泛化能力有限等挑战。
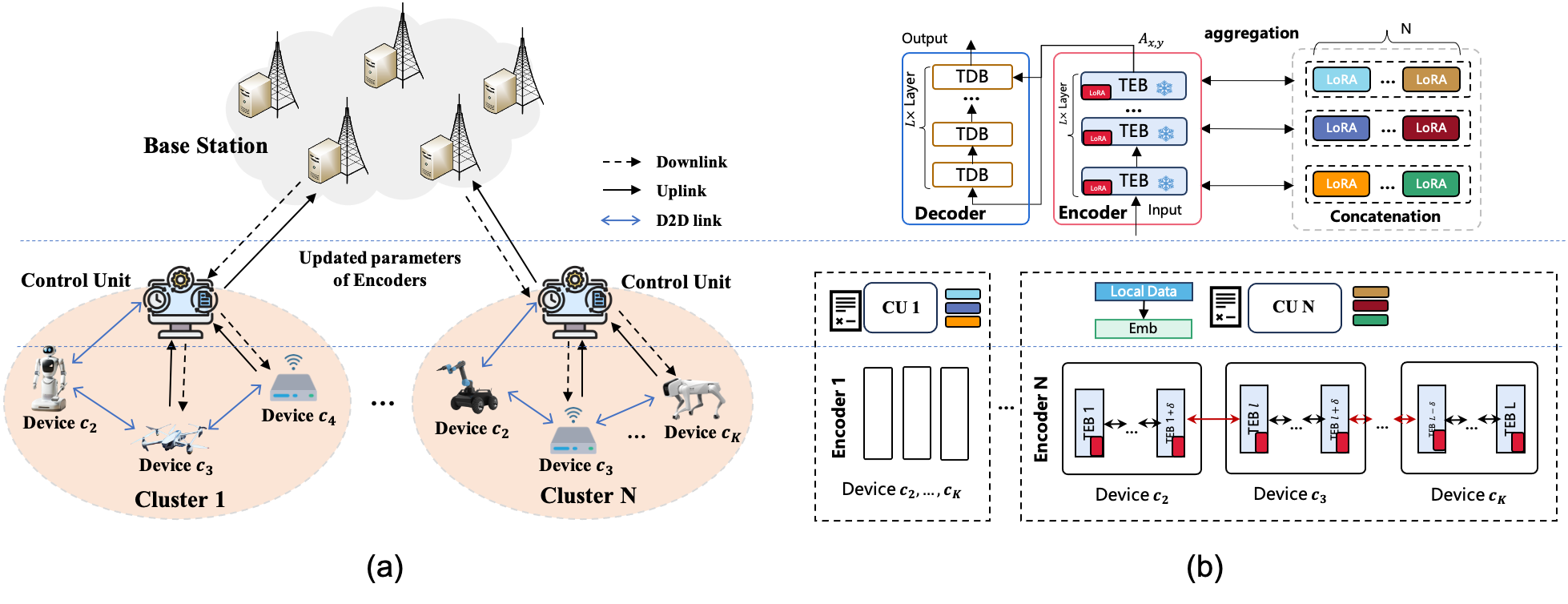
- CollaPipe通过结合协同流水线并行和联邦聚合,自适应地将LLM编码器分段部署到移动设备,解码器部署到边缘服务器,实现高效分布式训练。
- 实验结果表明,CollaPipe显著提高了计算效率(高达15.09%),降低了端到端延迟(至少48.98%),并减少了设备内存使用,支持在线学习。
📝 摘要(中文)
针对智能移动应用日益增长的需求,本文提出了一种混合分布式学习框架CollaPipe,它集成了协同流水线并行和联邦聚合,以支持自进化的智能网络。在CollaPipe中,编码器部分被自适应地划分为可变大小的段,并部署在移动设备上进行流水线并行训练,而解码器则部署在边缘服务器上以处理生成任务。然后,我们通过联邦聚合执行全局模型更新。为了提高训练效率,我们提出了一个联合优化问题,自适应地分配模型段、微批次、带宽和传输功率。我们推导并使用闭式收敛界来设计基于Lyapunov优化的动态分段调度和资源分配(DSSDA)算法,确保系统在长期约束下的稳定性。对Transformer和BERT模型进行的下游任务的大量实验表明,CollaPipe将计算效率提高了高达15.09%,将端到端延迟降低了至少48.98%,并将单个设备的内存使用量减少了一半以上,从而实现了异构和动态通信环境中的在线学习。
🔬 方法详解
问题定义:在异构边缘网络中,如何高效地训练大型语言模型(LLM)是一个关键问题。现有的集中式训练方法计算量巨大,无法在资源受限的边缘设备上直接应用。传统的联邦学习方法虽然可以利用边缘设备的算力,但难以处理LLM的巨大模型规模和高延迟需求。此外,异构网络环境下的设备能力差异和动态变化的网络状况也给模型训练带来了挑战。
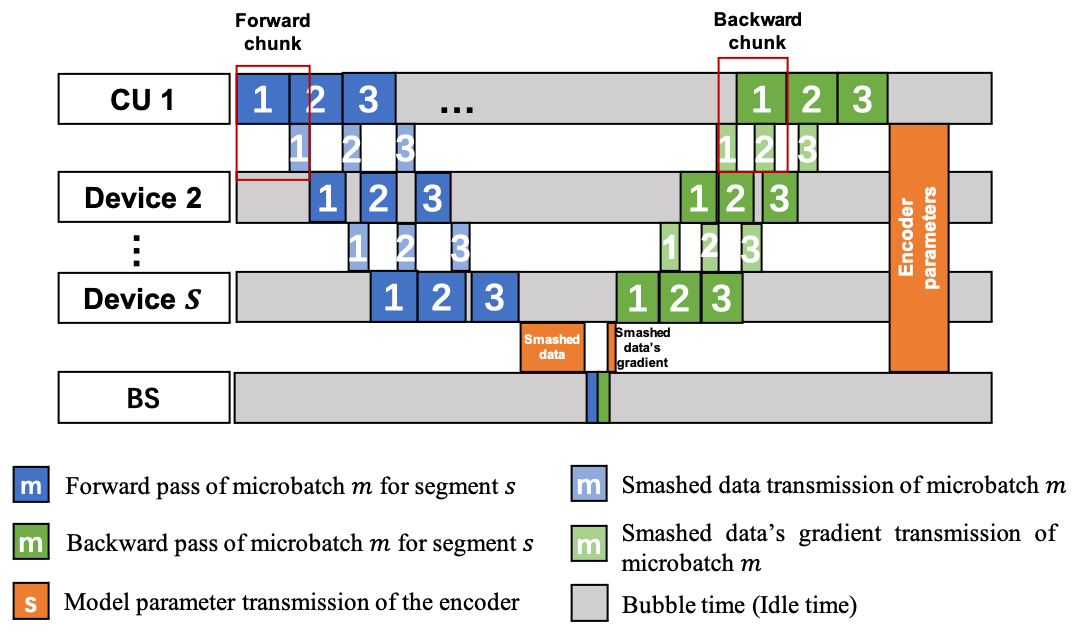
核心思路:CollaPipe的核心思路是将LLM的编码器部分进行分段,并利用流水线并行的方式在多个边缘设备上进行分布式训练。同时,将解码器部署在边缘服务器上,负责生成任务。通过联邦聚合的方式进行全局模型更新,从而实现协同训练。这种设计充分利用了边缘设备的算力,降低了单个设备的计算负担,并减少了端到端延迟。
技术框架:CollaPipe框架主要包含以下几个模块:1) 模型分段模块:将LLM的编码器部分自适应地划分为多个可变大小的段。2) 设备部署模块:将不同的模型段部署到不同的边缘设备上。3) 流水线并行训练模块:在多个设备上并行训练不同的模型段,形成流水线。4) 联邦聚合模块:将各个设备的模型更新聚合到全局模型。5) 动态分段调度和资源分配(DSSDA)模块:基于Lyapunov优化,动态地调整模型分段、资源分配和调度策略。
关键创新:CollaPipe的关键创新在于其自适应的分段优化流水线并行策略。与传统的静态分段方法不同,CollaPipe可以根据设备的计算能力和网络状况,动态地调整模型分段的大小和部署方案。此外,DSSDA算法能够有效地解决异构网络环境下的资源分配和调度问题,保证系统在长期约束下的稳定性。
关键设计:CollaPipe的关键设计包括:1) 自适应分段策略:根据设备的计算能力和网络带宽,动态地调整模型分段的大小。2) 基于Lyapunov优化的DSSDA算法:通过最小化Lyapunov漂移,实现长期系统稳定性和性能优化。3) 联合优化问题:同时优化模型分段、微批次大小、带宽和传输功率,以提高训练效率。4) 闭式收敛界:用于指导DSSDA算法的设计,确保模型收敛。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CollaPipe在Transformer和BERT模型上取得了显著的性能提升。与传统方法相比,CollaPipe将计算效率提高了高达15.09%,将端到端延迟降低了至少48.98%,并将单个设备的内存使用量减少了一半以上。这些结果验证了CollaPipe在异构边缘网络中进行LLM训练的有效性。
🎯 应用场景
CollaPipe适用于需要大规模语言模型支持的智能移动应用,例如智能助手、机器翻译、情感分析等。该框架能够在资源受限的边缘设备上高效地训练和部署LLM,从而实现低延迟、高可靠性的服务。未来,CollaPipe有望应用于自动驾驶、智能医疗、工业物联网等领域,推动边缘智能的发展。
📄 摘要(原文)
The increasing demand for intelligent mobile applications has made multi-agent collaboration with Transformer-based large language models (LLMs) essential in mobile edge computing (MEC) networks. However, training LLMs in such environments remains challenging due to heavy computation, high end-to-end latency, and limited model generalization. We introduce CollaPipe, a hybrid distributed learning framework that integrates collaborative pipeline parallelism with federated aggregation to support self-evolving intelligent networks. In CollaPipe, the encoder part is adaptively partitioned into variable-sized segments and deployed across mobile devices for pipeline-parallel training, while the decoder is deployed on edge servers to handle generative tasks. Then we perform global model update via federated aggregation. To enhance training efficiency, we formulate a joint optimization problem that adaptively allocates model segments, micro-batches, bandwidth, and transmission power. We derive and use a closed-form convergence bound to design an Dynamic Segment Scheduling and Resource Allocation (DSSDA) algorithm based on Lyapunov optimization, ensuring system stability under long-term constraints. Extensive experiments on downstream tasks with Transformer and BERT models show that CollaPipe improves computation efficiency by up to 15.09%, reduces end-to-end latency by at least 48.98%, and cuts single device memory usage by more than half, enabling online learning in heterogeneous and dynamic communication environments.