Closing the Loop Inside Neural Networks: Causality-Guided Layer Adaptation for Fault Recovery Control
作者: Mahdi Taheri, Soon-Jo Chung, Fred Y. Hadaegh
分类: eess.SY
发布日期: 2025-09-20 (更新: 2025-12-20)
💡 一句话要点
提出因果引导的神经网络层自适应方法,用于故障恢复控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 故障恢复控制 深度神经网络 因果推理 层自适应 李雅普诺夫稳定性 非线性控制 平均因果效应
📋 核心要点
- 现有基于深度神经网络的控制方法在故障恢复时计算负担大,通常需要全网络或仅最后一层更新。
- 本文提出一种因果引导的层自适应方法,通过离线因果分析选择关键层,在线阶段仅自适应这些层。
- 实验表明,该方法在保证系统稳定性的前提下,降低了计算开销,并在航天器姿态控制中验证了有效性。
📝 摘要(中文)
本文研究了针对执行器效能损失故障和外部扰动下非线性控制仿射系统的实时故障恢复控制问题。我们推导出一个两阶段框架,该框架结合了因果推理和选择性在线自适应,以实现有效的基于学习的恢复控制方法。在离线阶段,我们开发了一种基于平均因果效应(ACE)的因果层归因技术,以评估预训练深度神经网络(DNN)控制器中每一层在补偿故障方面的相对重要性。该方法识别出对鲁棒故障补偿负责的高影响力层子集。在在线阶段,我们部署基于李雅普诺夫的梯度更新,仅自适应ACE选择的层,从而避免了全网络或仅最后一层更新的需求。所提出的自适应控制器保证了闭环系统在存在执行器故障和外部扰动下的均匀最终有界(UUB)和指数收敛。与具有全网络自适应的传统自适应DNN控制器相比,我们的方法降低了计算开销。为了证明我们提出的方法的有效性,提供了一个关于具有四个反作用轮的航天器三轴姿态控制系统的案例研究。
🔬 方法详解
问题定义:本文旨在解决非线性控制仿射系统在面临执行器效能损失故障和外部扰动时,如何进行实时故障恢复控制的问题。现有基于深度神经网络的控制方法,如全网络自适应或仅最后一层自适应,存在计算负担过大的问题,难以满足实时性要求。
核心思路:本文的核心思路是利用因果推理来识别深度神经网络控制器中对故障补偿起关键作用的层,然后在在线自适应阶段仅更新这些关键层,从而降低计算复杂度,提高实时性。这种选择性自适应策略避免了对整个网络或仅最后一层进行更新,显著减少了计算开销。
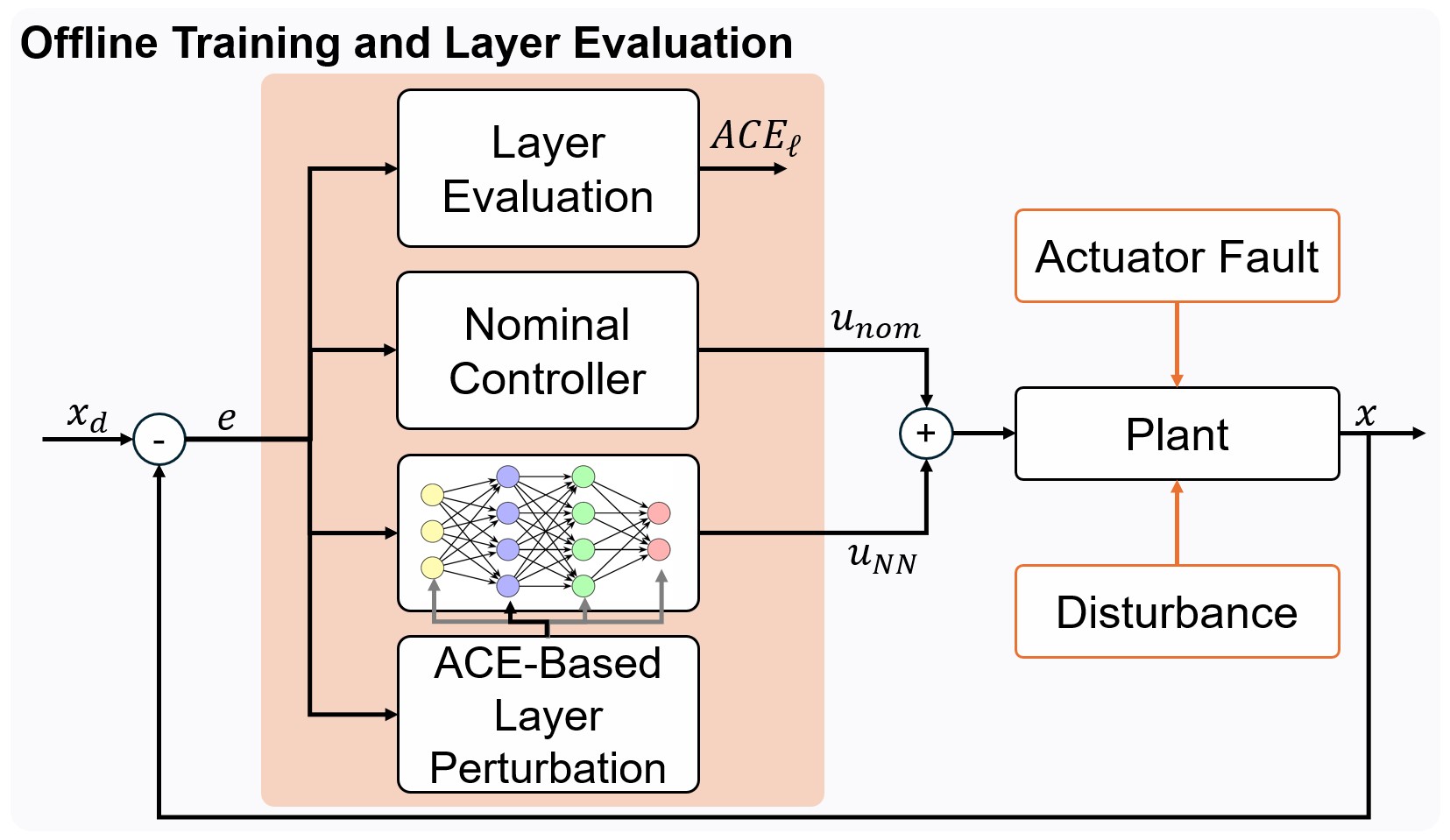
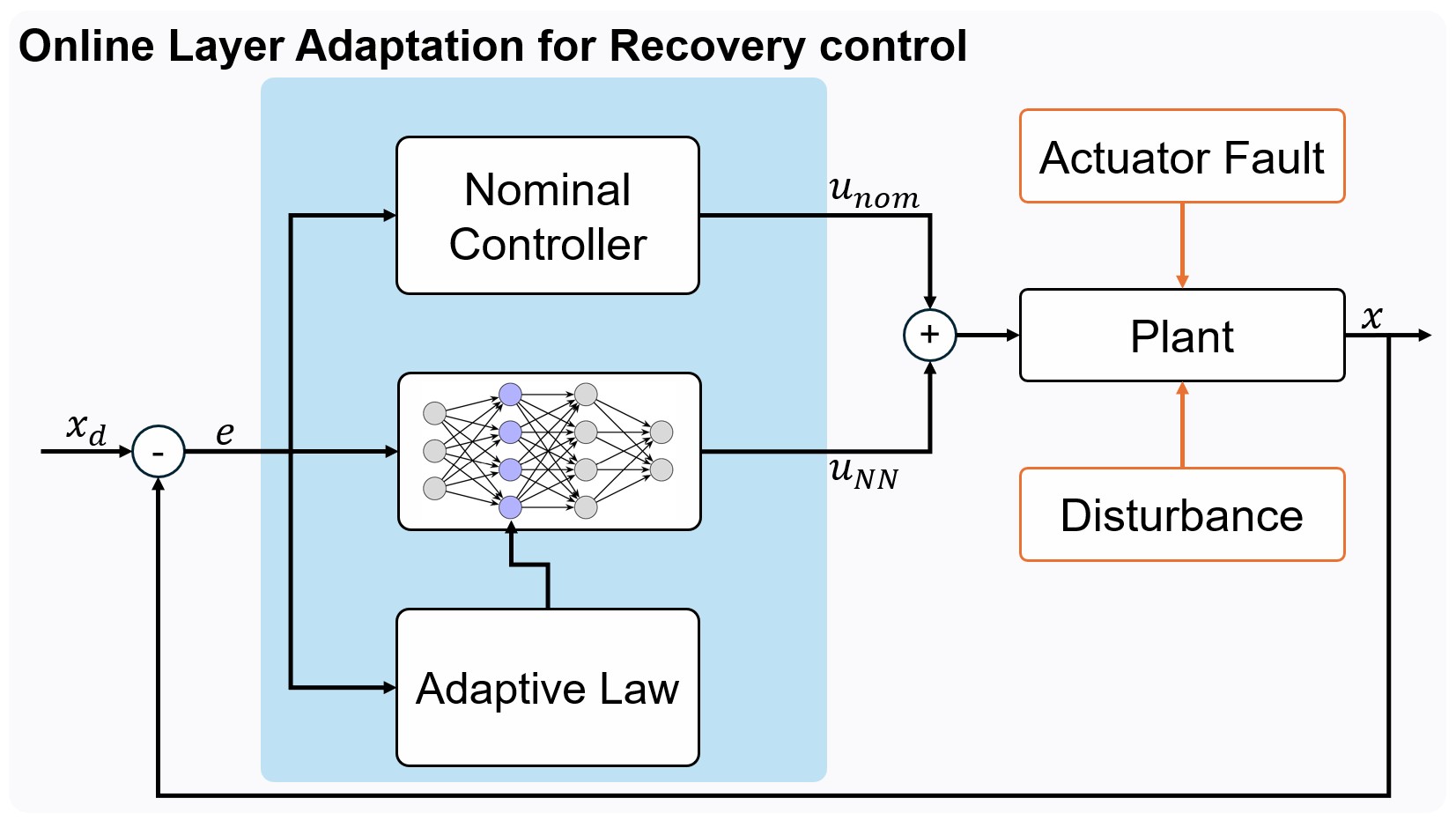
技术框架:该方法包含离线和在线两个阶段。离线阶段,使用基于平均因果效应(ACE)的因果层归因技术,评估预训练DNN控制器中每一层的重要性,并选择高影响力层。在线阶段,使用基于李雅普诺夫的梯度更新方法,仅自适应离线阶段选择的关键层。整个框架保证了闭环系统的均匀最终有界(UUB)和指数收敛。
关键创新:最重要的技术创新点在于将因果推理引入到神经网络控制器的层自适应中。通过因果分析,能够准确识别出对故障补偿至关重要的层,从而实现选择性的在线自适应。这与传统的全网络自适应或仅最后一层自适应方法有着本质的区别,显著降低了计算复杂度。
关键设计:离线阶段,使用平均因果效应(ACE)来量化每一层对输出的影响,ACE值越高,表示该层对故障补偿越重要。在线阶段,采用基于李雅普诺夫的梯度更新方法,确保自适应过程的稳定性。具体而言,设计合适的李雅普诺夫函数,并根据李雅普诺夫稳定性理论推导出自适应律,保证闭环系统的稳定性。
🖼️ 关键图片
📊 实验亮点
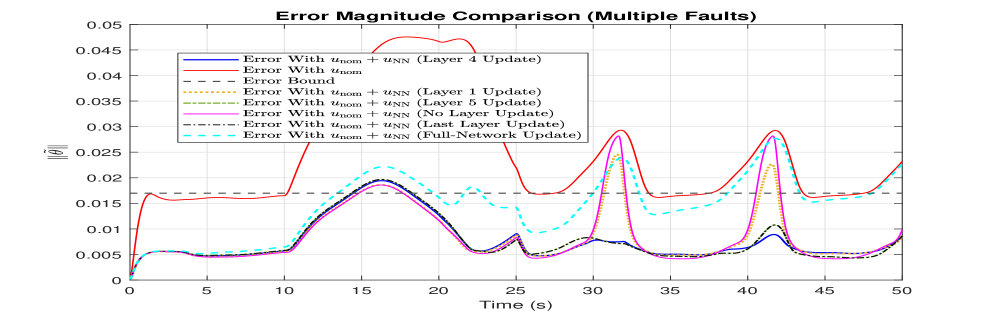
通过在航天器三轴姿态控制系统上的实验,验证了该方法的有效性。实验结果表明,与全网络自适应方法相比,该方法在保证系统稳定性的前提下,显著降低了计算开销,提高了控制系统的实时性。具体的性能数据(例如计算时间减少的百分比、控制精度提高的幅度等)在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于各种需要高可靠性和实时性的控制系统,例如航空航天、机器人、自动驾驶等领域。在这些领域,系统经常面临各种故障和扰动,快速有效的故障恢复能力至关重要。该方法能够降低计算负担,提高控制系统的实时性和鲁棒性,具有重要的实际应用价值。
📄 摘要(原文)
This paper studies the problem of real-time fault recovery control for nonlinear control-affine systems subject to actuator loss of effectiveness faults and external disturbances. We derive a two-stage framework that combines causal inference with selective online adaptation to achieve an effective learning-based recovery control method. In the offline phase, we develop a causal layer attribution technique based on the average causal effect (ACE) to evaluate the relative importance of each layer in a pretrained deep neural network (DNN) controller compensating for faults. This methodology identifies a subset of high-impact layers responsible for robust fault compensation. In the online phase, we deploy a Lyapunov-based gradient update to adapt only the ACE-selected layer to circumvent the need for full-network or last-layer only updates. The proposed adaptive controller guarantees uniform ultimate boundedness (UUB) with exponential convergence of the closed-loop system in the presence of actuator faults and external disturbances. Compared to conventional adaptive DNN controllers with full-network adaptation, our methodology has a reduced computational overhead. To demonstrate the effectiveness of our proposed methodology, a case study is provided on a 3-axis attitude control system of a spacecraft with four reaction wheels.