Hierarchical Reinforcement Learning with Low-Level MPC for Multi-Agent Control
作者: Max Studt, Georg Schildbach
分类: eess.SY, cs.AI, cs.RO, math.OC
发布日期: 2025-09-19 (更新: 2025-10-09)
💡 一句话要点
提出基于分层强化学习与低层MPC的多智能体控制方法,提升安全性和协同性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 模型预测控制 多智能体系统 协同控制 机器人控制
📋 核心要点
- 端到端学习在复杂环境中样本效率低,基于模型的方法泛化能力弱,难以实现安全协同控制。
- 采用分层框架,高层RL策略选择抽象目标,低层MPC确保动态可行和安全运动。
- 在捕食者-猎物环境中,该方法在奖励、安全性和一致性方面优于现有方法。
📝 摘要(中文)
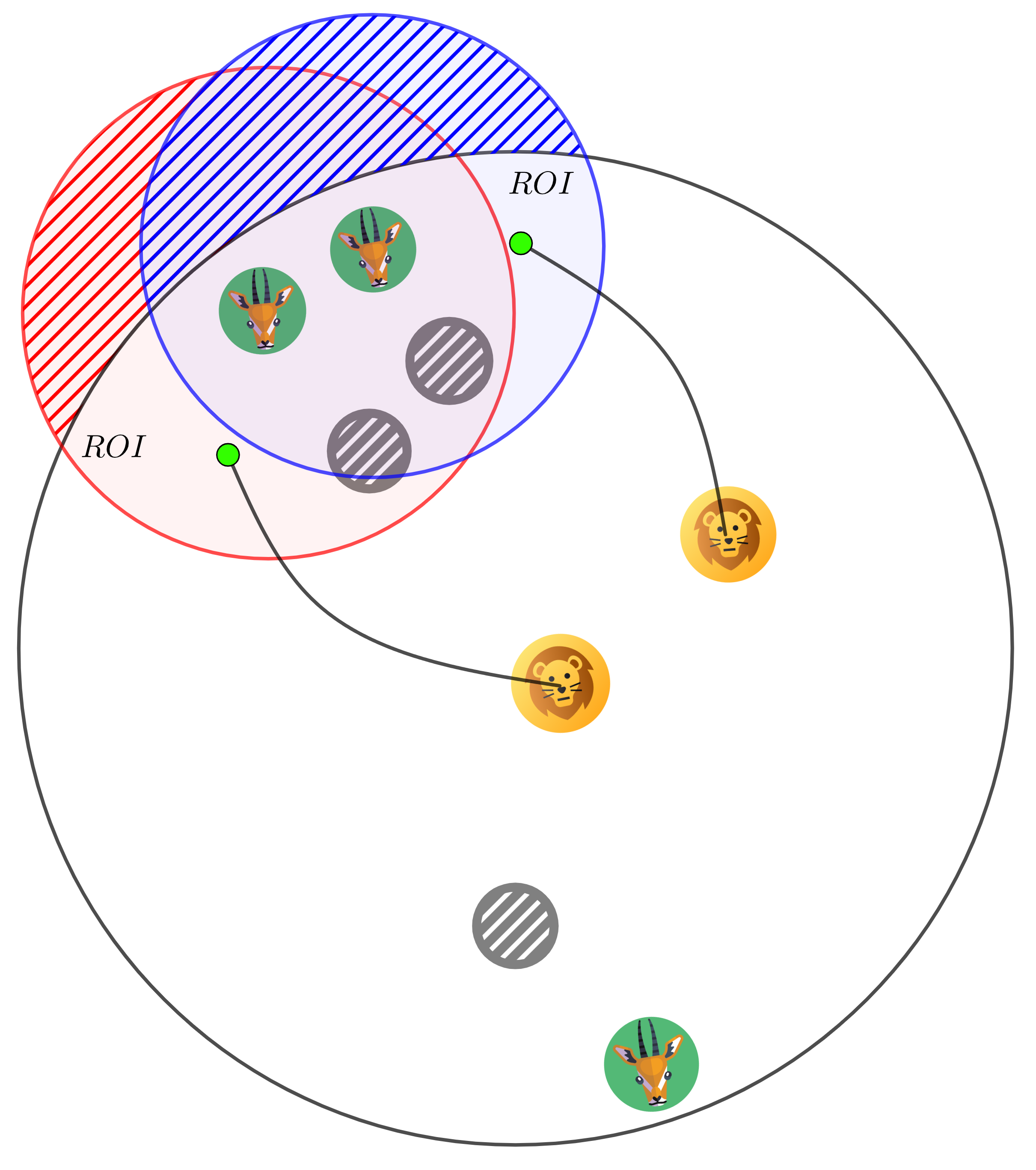
在动态、约束丰富的环境中实现安全和协同行为仍然是基于学习的控制面临的主要挑战。纯粹的端到端学习通常存在样本效率低和可靠性有限的问题,而基于模型的方法依赖于预定义的参考,并且难以泛化。我们提出了一种分层框架,该框架将通过强化学习(RL)进行战术决策与通过模型预测控制(MPC)进行低层执行相结合。对于多智能体系统,这意味着高层策略从结构化的感兴趣区域(ROI)中选择抽象目标,而MPC确保动态可行和安全的运动。在捕食者-猎物基准测试中,我们的方法在奖励、安全性和一致性方面优于端到端和基于屏蔽的RL基线,突出了将结构化学习与基于模型的控制相结合的优势。
🔬 方法详解
问题定义:论文旨在解决多智能体系统中,在动态、约束丰富的环境中实现安全和协同控制的问题。现有端到端强化学习方法样本效率低,难以训练;基于模型的方法依赖预定义参考轨迹,泛化能力不足,难以适应复杂环境的变化。
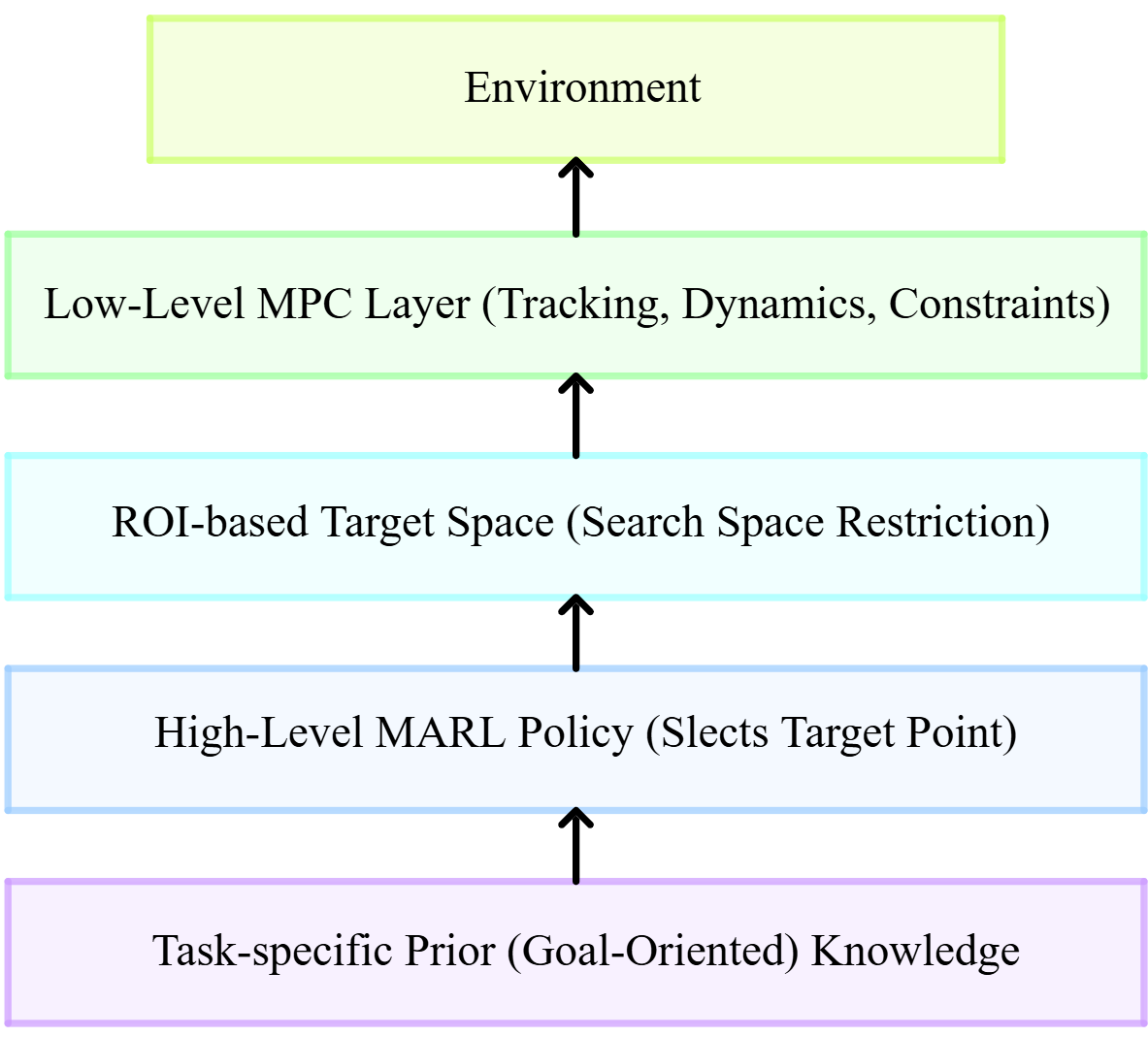
核心思路:论文的核心思路是将强化学习(RL)和模型预测控制(MPC)相结合,构建一个分层控制框架。高层使用RL进行战术决策,选择抽象目标;低层使用MPC进行运动规划和控制,确保安全性和动态可行性。这种分层结构可以有效利用RL的决策能力和MPC的精确控制能力,提高整体性能。
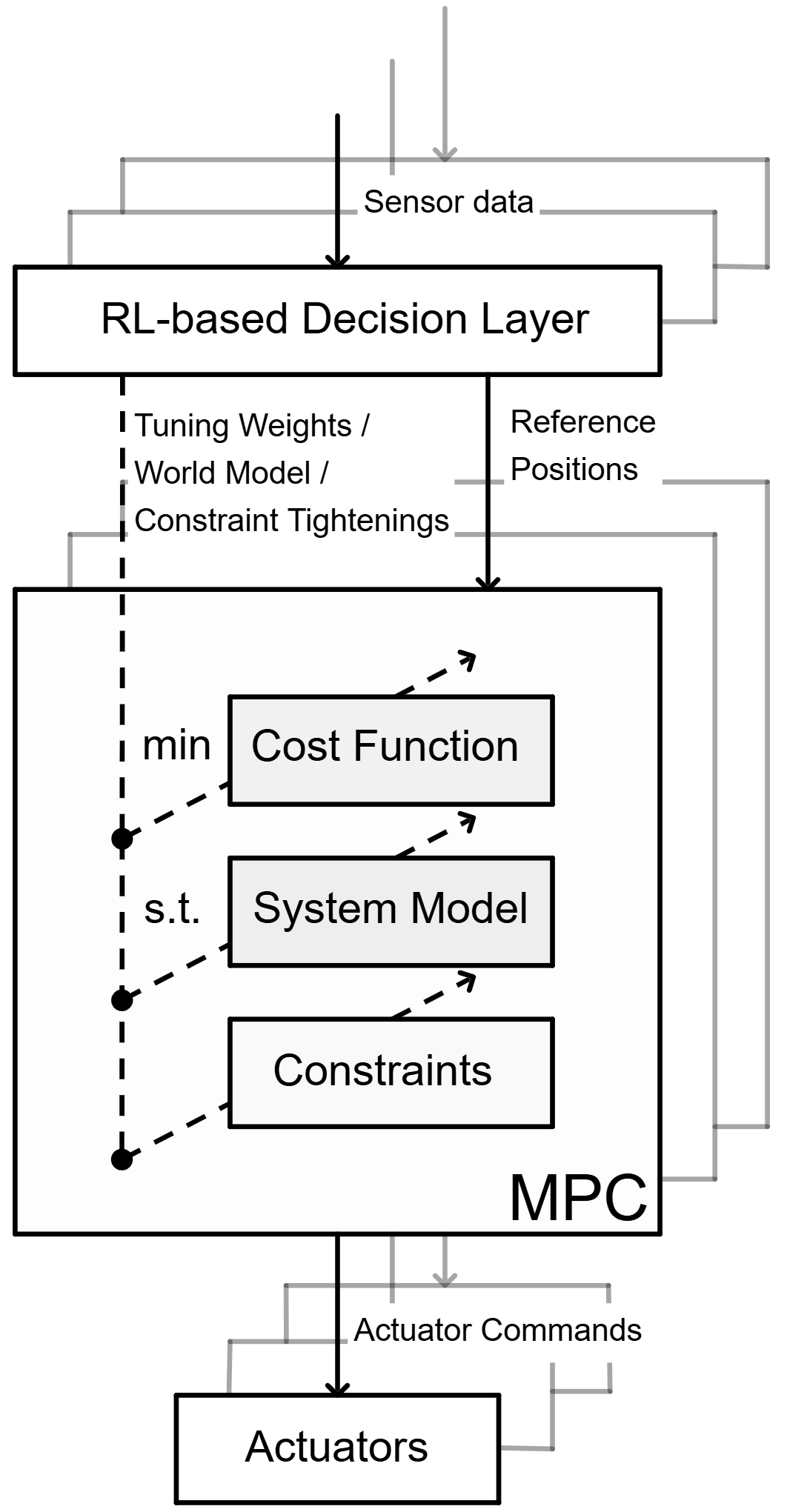
技术框架:该框架包含两个主要模块:高层RL策略和低层MPC控制器。高层RL策略接收环境状态作为输入,输出抽象目标,例如感兴趣区域(ROI)的中心点。低层MPC控制器接收高层策略输出的目标点,并根据智能体的动力学模型和约束条件,生成最优的控制指令,驱动智能体运动。整个系统通过不断迭代高层决策和低层执行,实现多智能体的协同控制。
关键创新:该方法最重要的创新点在于将强化学习和模型预测控制有机结合,形成一个分层控制框架。这种分层结构既能利用RL的决策能力,又能保证控制的安全性和动态可行性。此外,使用感兴趣区域(ROI)作为高层策略的输出,可以有效降低状态空间维度,提高学习效率。
关键设计:高层RL策略可以使用任意的强化学习算法,例如PPO或SAC。低层MPC控制器需要根据智能体的动力学模型和约束条件进行设计。关键参数包括MPC的预测时域长度、控制频率、以及目标函数的权重系数。损失函数的设计需要平衡目标跟踪精度、控制能量消耗和安全性。
🖼️ 关键图片
📊 实验亮点
在捕食者-猎物基准测试中,该方法在奖励、安全性和一致性方面优于端到端RL和基于屏蔽的RL基线。具体而言,该方法能够更快地学习到有效的策略,并且在面对未知环境时表现出更好的泛化能力。实验结果表明,分层控制框架能够有效提高多智能体系统的性能。
🎯 应用场景
该研究成果可应用于无人驾驶、机器人集群控制、交通流量优化等领域。通过分层控制架构,可以有效解决复杂环境下多智能体的协同控制问题,提高系统的安全性、效率和鲁棒性。未来可进一步扩展到更复杂的环境和任务中,例如多机器人协同搜索救援、智能交通系统等。
📄 摘要(原文)
Achieving safe and coordinated behavior in dynamic, constraint-rich environments remains a major challenge for learning-based control. Pure end-to-end learning often suffers from poor sample efficiency and limited reliability, while model-based methods depend on predefined references and struggle to generalize. We propose a hierarchical framework that combines tactical decision-making via reinforcement learning (RL) with low-level execution through Model Predictive Control (MPC). For the case of multi-agent systems this means that high-level policies select abstract targets from structured regions of interest (ROIs), while MPC ensures dynamically feasible and safe motion. Tested on a predator-prey benchmark, our approach outperforms end-to-end and shielding-based RL baselines in terms of reward, safety, and consistency, underscoring the benefits of combining structured learning with model-based control.