Large Language Model-Empowered Decision Transformer for UAV-Enabled Data Collection
作者: Zhixion Chen, Jiangzhou Wang, Hyundong Shin, Arumugam Nallanathan
分类: eess.SY, cs.LG
发布日期: 2025-09-17 (更新: 2025-09-19)
备注: 14pages, 8 figures
💡 一句话要点
提出LLM-CRDT框架,解决无人机数据收集中的轨迹规划与能效优化问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机 数据收集 轨迹规划 强化学习 决策Transformer 大型语言模型 能源效率 资源分配
📋 核心要点
- 现有无人机轨迹优化方法,如强化学习,在实际应用中面临高成本和风险,离线强化学习则依赖高质量数据集且训练不稳定。
- 论文提出LLM-CRDT框架,利用预训练LLM增强决策Transformer,并引入评论家网络进行正则化,从而在次优数据集上学习高效策略。
- 实验结果表明,LLM-CRDT在无人机数据收集任务中,相较于现有最优DT方法,能源效率提升高达36.7%。
📝 摘要(中文)
本文研究了利用无人机(UAV)从空间分布的设备进行可靠且节能的数据收集问题,这对于支持各种物联网(IoT)应用具有重要意义。针对无人机续航和通信范围的限制,需要智能轨迹规划。虽然强化学习(RL)已被广泛用于UAV轨迹优化,但其交互性导致现实环境中的高成本和风险。离线RL缓解了这些问题,但仍然容易受到不稳定训练的影响,并且严重依赖于专家质量的数据集。为了解决这些挑战,本文构建了一个联合UAV轨迹规划和资源分配问题,以最大化数据收集的能源效率。资源分配子问题首先被转换为等效的线性规划公式,并通过多项式时间复杂度进行最优求解。然后,本文提出了一种大型语言模型(LLM)赋能的评论家正则化决策Transformer(DT)框架,称为LLM-CRDT,以学习有效的UAV控制策略。在LLM-CRDT中,本文结合了评论家网络来正则化DT模型训练,从而将DT的序列建模能力与基于评论家的价值指导相结合,从而能够从次优数据集中学习有效的策略。此外,为了缓解Transformer模型的数据饥渴问题,本文采用预训练的LLM作为DT模型的Transformer骨干,并采用参数高效的微调策略,即LoRA,从而能够以小规模数据集和低计算开销快速适应UAV控制任务。大量的仿真结果表明,LLM-CRDT优于基准在线和离线RL方法,与当前最先进的DT方法相比,能源效率提高了36.7%。
🔬 方法详解
问题定义:论文旨在解决无人机(UAV)在物联网(IoT)环境中进行数据收集时的轨迹规划和资源分配问题,目标是最大化能量效率。现有方法,如在线强化学习,需要大量的环境交互,成本高昂且存在风险。离线强化学习虽然避免了在线交互,但对数据集质量要求高,且训练过程不稳定。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大表征能力和泛化能力,结合决策Transformer(DT)的序列建模能力,以及评论家网络(Critic Network)的价值指导,从而在有限的、次优的数据集上学习到高效的无人机控制策略。通过预训练LLM和参数高效微调(LoRA),降低了对数据量的需求和计算开销。
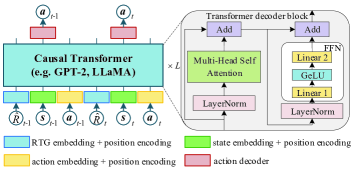
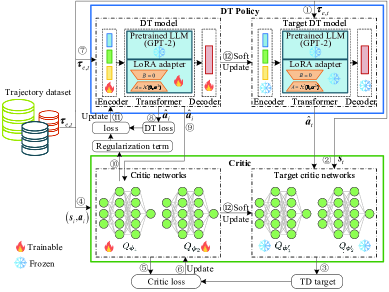
技术框架:LLM-CRDT框架主要包含以下几个部分:1) 将资源分配子问题转化为线性规划问题并求解;2) 使用预训练的LLM作为决策Transformer的骨干网络;3) 引入评论家网络,对决策Transformer的训练进行正则化,提供价值指导;4) 采用LoRA进行参数高效微调,快速适应无人机控制任务。整体流程是先利用线性规划求解资源分配,然后利用LLM-CRDT学习无人机轨迹控制策略。
关键创新:论文的关键创新在于将大型语言模型(LLM)引入到无人机轨迹规划的决策Transformer框架中,并结合评论家网络进行正则化。这使得模型能够在数据量有限且质量不高的情况下,学习到有效的控制策略。与传统的决策Transformer相比,LLM-CRDT利用了LLM的预训练知识,降低了对数据的依赖,并提高了泛化能力。
关键设计:论文的关键设计包括:1) 使用预训练的LLM作为Transformer的骨干网络,并采用LoRA进行参数高效微调,降低了计算成本;2) 引入评论家网络,通过最小化评论家网络预测值与实际回报之间的差异,对决策Transformer的训练进行正则化,避免过拟合;3) 将资源分配问题转化为线性规划问题,并采用多项式时间复杂度的算法进行最优求解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM-CRDT在无人机数据收集任务中表现出色,相较于基准在线和离线强化学习方法,性能显著提升。与当前最先进的决策Transformer(DT)方法相比,LLM-CRDT实现了高达36.7%的能源效率提升。这验证了LLM赋能的决策Transformer在解决无人机轨迹规划问题上的有效性,并表明该方法具有很强的实际应用潜力。
🎯 应用场景
该研究成果可应用于各种需要无人机进行数据收集的场景,例如:环境监测、农业数据采集、灾害救援、智慧城市等。通过优化无人机轨迹和资源分配,可以显著提高数据收集的效率和能源利用率,降低运营成本,并为物联网应用提供更可靠的数据支持。未来,该技术有望进一步扩展到多无人机协同数据收集、动态环境下的轨迹规划等更复杂的场景。
📄 摘要(原文)
The deployment of unmanned aerial vehicles (UAVs) for reliable and energy-efficient data collection from spatially distributed devices holds great promise in supporting diverse Internet of Things (IoT) applications. Nevertheless, the limited endurance and communication range of UAVs necessitate intelligent trajectory planning. While reinforcement learning (RL) has been extensively explored for UAV trajectory optimization, its interactive nature entails high costs and risks in real-world environments. Offline RL mitigates these issues but remains susceptible to unstable training and heavily rely on expert-quality datasets. To address these challenges, we formulate a joint UAV trajectory planning and resource allocation problem to maximize energy efficiency of data collection. The resource allocation subproblem is first transformed into an equivalent linear programming formulation and solved optimally with polynomial-time complexity. Then, we propose a large language model (LLM)-empowered critic-regularized decision transformer (DT) framework, termed LLM-CRDT, to learn effective UAV control policies. In LLM-CRDT, we incorporate critic networks to regularize the DT model training, thereby integrating the sequence modeling capabilities of DT with critic-based value guidance to enable learning effective policies from suboptimal datasets. Furthermore, to mitigate the data-hungry nature of transformer models, we employ a pre-trained LLM as the transformer backbone of the DT model and adopt a parameter-efficient fine-tuning strategy, i.e., LoRA, enabling rapid adaptation to UAV control tasks with small-scale dataset and low computational overhead. Extensive simulations demonstrate that LLM-CRDT outperforms benchmark online and offline RL methods, achieving up to 36.7\% higher energy efficiency than the current state-of-the-art DT approaches.