Deep Reinforcement Learning-Based Decision-Making Strategy Considering User Satisfaction Feedback in Demand Response Program
作者: Xin Li, Li Ding, Qiao Lin, Zhen-Wei Yu
分类: eess.SY
发布日期: 2025-09-03
备注: This version corrects equation display errors that occurred in the IEEE Xplore version. Please cite the official IEEE DOI:10.1109/ICPST65050.2025.11089098
期刊: 2025 IEEE 3rd International Conference on Power Science and Technology (ICPST)
💡 一句话要点
提出MBTF-TD3算法,解决需求响应中用户满意度与DRP收益的平衡问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 需求响应 强化学习 用户满意度 深度确定性策略梯度 时间序列预测
📋 核心要点
- 现有需求响应策略侧重DRP收益,忽略用户满意度,导致用户参与意愿降低。
- 提出MBTF-TD3算法,将用户满意度纳入奖励函数,并利用多分支时间融合提取时间特征。
- 实验表明,该方法能有效提升用户满意度,同时保证DRP的经济收益。
📝 摘要(中文)
本文针对需求响应(DR)项目中,需求响应提供商(DRP)作为中间方,在追求自身经济收益最大化时,往往忽略终端用户满意度的问题。同时,DRP通常难以获取用户决策策略和满意度评估机制的详细数学模型,给传统基于模型的方法带来挑战。为此,本文设计了一种用户侧满意度评估机制,并提出了一种多分支时间融合双延迟深度确定性策略梯度(MBTF-TD3)强化学习算法。该算法通过动态调整的惩罚项将用户满意度反馈纳入奖励函数中。所提出的MBTF结构有效地提取了时间序列观测数据中的时间特征依赖性,动态调整的惩罚函数成功地提高了用户的整体满意度。实验验证了所提算法的性能和有效性。
🔬 方法详解
问题定义:论文旨在解决需求响应项目中,需求响应提供商(DRP)在制定电价策略时,如何在最大化自身经济收益的同时,兼顾终端用户的满意度。现有方法通常采用双层优化模型,DRP作为领导者,用户作为跟随者,但这种模式往往忽略了用户满意度,导致用户参与DR项目的积极性不高。此外,DRP通常无法获得用户决策策略和满意度评估机制的详细数学模型,这使得传统的基于模型的方法难以应用。
核心思路:论文的核心思路是将用户满意度纳入DRP的决策过程中,通过强化学习算法学习最优的电价策略。具体来说,论文设计了一种用户侧满意度评估机制,并将用户满意度反馈融入到强化学习的奖励函数中,从而引导DRP在追求自身收益的同时,也关注用户的满意度。这种方法避免了对用户行为进行建模的需要,可以直接从与环境的交互中学习最优策略。
技术框架:整体框架包括DRP和用户两部分。DRP作为智能体,通过观察环境状态(如历史负荷、电价等)和用户满意度反馈,选择电价策略。用户根据电价策略调整自身用电行为,并产生满意度反馈。DRP的目标是最大化自身收益和用户满意度的加权和。论文采用强化学习算法MBTF-TD3来训练DRP的策略。该算法使用多分支时间融合结构来提取时间序列观测数据中的时间特征依赖性,并使用双延迟深度确定性策略梯度算法来提高训练的稳定性和效率。
关键创新:论文的关键创新点在于:1) 将用户满意度反馈纳入强化学习的奖励函数中,从而引导DRP在追求自身收益的同时,也关注用户的满意度。2) 提出了多分支时间融合(MBTF)结构,用于提取时间序列观测数据中的时间特征依赖性。3) 使用动态调整的惩罚函数来进一步提高用户的整体满意度。
关键设计:论文的关键设计包括:1) 用户满意度评估机制的设计,该机制根据用户的用电行为和电价变化来评估用户的满意度。2) 奖励函数的设计,该函数综合考虑了DRP的经济收益和用户的满意度,并使用动态调整的惩罚项来平衡两者之间的关系。3) MBTF结构的设计,该结构使用多个分支来提取不同时间尺度的特征,并将这些特征融合起来,从而更好地捕捉时间序列数据的依赖性。4) TD3算法的参数设置,包括学习率、折扣因子、目标网络更新频率等。
🖼️ 关键图片

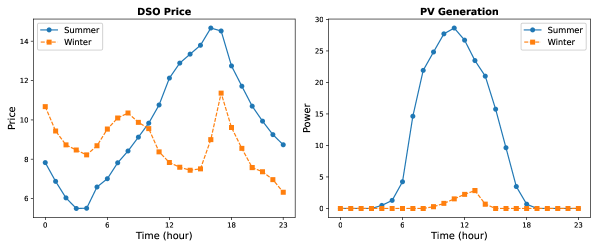
📊 实验亮点
实验结果表明,所提出的MBTF-TD3算法能够有效地提高用户的满意度,同时保证DRP的经济收益。与传统的TD3算法相比,MBTF-TD3算法在用户满意度方面有显著提升,并且能够更快地收敛到最优策略。具体性能数据未知,但结论表明该方法优于基线方法。
🎯 应用场景
该研究成果可应用于智能电网的需求响应管理,帮助电力公司或需求响应提供商制定更合理的电价策略,提高用户参与需求响应的积极性,实现电力资源的优化配置,降低电力系统的运行成本,并提升电力系统的可靠性和稳定性。该方法也适用于其他涉及用户参与和反馈的资源优化问题。
📄 摘要(原文)
Demand response providers (DRPs) are intermediaries between the upper-level distribution system operator and the lower-level participants in demand response (DR) programs. Usually, DRPs act as leaders and determine electricity pricing strategies to maximize their economic revenue, while end-users adjust their power consumption following the pricing signals. However, this profit-seeking bi-level optimization model often neglects the satisfaction of end-users participating in DR programs. In addition, the detailed mathematical models underlying user decision-making strategy and satisfaction evaluation mechanism are typically unavailable to DRPs, posing significant challenges to conventional model-based solution methods. To address these issues, this paper designs a user-side satisfaction evaluation mechanism and proposes a multi-branch temporal fusion twin-delayed deep deterministic policy gradient (MBTF-TD3) reinforcement learning algorithm. User satisfaction feedback is incorporated into the reward function via a dynamically adjusted penalty term. The proposed MBTF structure effectively extracts temporal feature dependencies in the time-series observation data, and the dynamically adjusted penalty function successfully enhances the overall satisfaction level of users. Several experiments are conducted to validate the performance and the effectiveness of our proposed solution algorithm.