Safe Deployment of Offline Reinforcement Learning via Input Convex Action Correction
作者: Alex Durkin, Jasper Stolte, Matthew Jones, Raghuraman Pitchumani, Bei Li, Christian Michler, Mehmet Mercangöz
分类: eess.SY, cs.AI, cs.LG, stat.ML
发布日期: 2025-07-30
💡 一句话要点
提出基于输入凸动作校正的离线强化学习安全部署方法,用于化工过程控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 化工过程控制 安全部署 输入凸神经网络 动作校正
📋 核心要点
- 现有离线强化学习方法在化工过程控制中存在稳态偏移和设定点附近性能下降等问题。
- 提出一种基于输入凸神经网络(PICNN)的部署时安全层,通过梯度下降进行动作校正,无需重新训练或环境交互。
- 实验表明,结合凸动作校正的离线RL优于传统控制方法,并在启动、换批等场景中保持了系统稳定性。
📝 摘要(中文)
本文研究了离线强化学习(offline RL)在化工过程系统控制策略开发中的应用,利用历史数据,避免了在线实验的风险和成本。针对放热聚合连续搅拌釜式反应器,构建了一个兼容Gymnasium的仿真环境,模拟了反应器的非线性动力学、反应动力学、能量平衡和操作约束。该环境支持启动、降级换批和升级换批三种工业场景,并提供了由随机整定的比例-积分控制器生成的离线数据集,为评估离线RL算法在实际过程控制任务中的性能提供了基准。评估了行为克隆和隐式Q学习作为基线算法,并提出了一个新颖的部署时安全层,该安全层使用输入凸神经网络(PICNN)作为学习的成本模型,执行基于梯度的动作校正。实验结果表明,离线RL,特别是与凸动作校正相结合时,可以优于传统的控制方法,并在所有场景中保持稳定性。这些发现证明了将离线RL与可解释且具有安全意识的校正相结合,用于高风险化工过程控制的可行性,并为工业系统中更可靠的数据驱动自动化奠定了基础。
🔬 方法详解
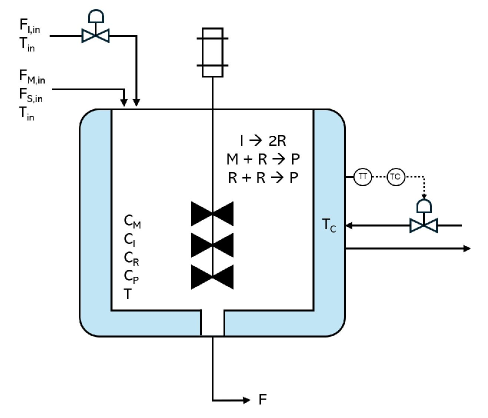
问题定义:论文旨在解决离线强化学习在化工过程控制中安全部署的问题。现有离线RL方法在实际应用中面临挑战,例如,由于数据分布偏移,策略可能产生不安全的动作,导致系统不稳定或性能下降。特别是在化工过程中,细微的偏差都可能导致严重的后果。此外,传统的控制方法需要人工调整参数,难以适应复杂和动态的化工过程。
核心思路:论文的核心思路是在离线训练的策略基础上,增加一个部署时的安全层,对策略输出的动作进行校正,确保动作的安全性和有效性。该安全层基于学习到的成本模型,通过梯度下降的方式,将动作调整到成本较低的区域。这种方法无需重新训练策略,可以在部署时实时进行动作校正,提高了系统的安全性和鲁棒性。
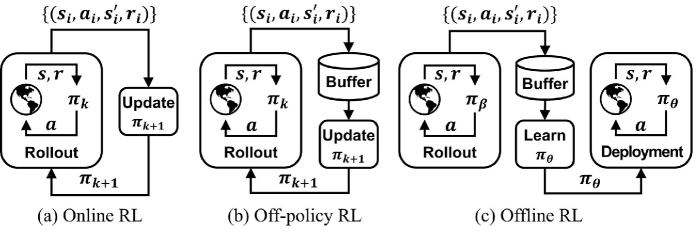
技术框架:整体框架包括三个主要部分:1) 离线数据集的生成,通过仿真环境和随机PID控制器生成包含各种工况的数据;2) 离线策略的学习,使用行为克隆或隐式Q学习等算法,从离线数据中学习控制策略;3) 部署时安全层的应用,使用输入凸神经网络(PICNN)学习状态相关的成本模型,并使用梯度下降对策略输出的动作进行校正。
关键创新:论文的关键创新在于提出了基于输入凸神经网络(PICNN)的动作校正方法。PICNN保证了成本函数的凸性,从而保证了梯度下降的收敛性,避免了陷入局部最优解。此外,PICNN可以实时计算梯度,实现快速的动作校正,满足化工过程控制的实时性要求。这种方法不需要重新训练策略,可以在部署时灵活地调整动作,提高了系统的适应性。
关键设计:PICNN的网络结构需要保证输出的凸性,通常采用特定的激活函数和权重约束来实现。成本函数的选择需要能够反映系统的安全性和性能指标,例如,可以包括反应温度、压力等关键参数的约束。梯度下降的步长需要根据实际情况进行调整,以保证收敛速度和稳定性。此外,论文还设计了Gymnasium兼容的仿真环境,用于生成离线数据集和评估算法性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结合凸动作校正的离线RL方法在启动、降级换批和升级换批三种工业场景中均优于传统的PID控制方法。具体而言,在保证系统稳定性的前提下,离线RL方法能够更快地达到设定点,并减少稳态误差。此外,PICNN的动作校正能够有效地避免不安全动作的发生,提高了系统的安全性。
🎯 应用场景
该研究成果可应用于各种化工过程控制场景,例如连续搅拌釜式反应器、精馏塔等。通过离线学习历史数据,并结合安全层进行动作校正,可以实现安全、高效的自动化控制,降低人工干预的需求,提高生产效率和产品质量。此外,该方法还可以推广到其他高风险的工业控制领域,例如电力系统、航空航天等。
📄 摘要(原文)
Offline reinforcement learning (offline RL) offers a promising framework for developing control strategies in chemical process systems using historical data, without the risks or costs of online experimentation. This work investigates the application of offline RL to the safe and efficient control of an exothermic polymerisation continuous stirred-tank reactor. We introduce a Gymnasium-compatible simulation environment that captures the reactor's nonlinear dynamics, including reaction kinetics, energy balances, and operational constraints. The environment supports three industrially relevant scenarios: startup, grade change down, and grade change up. It also includes reproducible offline datasets generated from proportional-integral controllers with randomised tunings, providing a benchmark for evaluating offline RL algorithms in realistic process control tasks. We assess behaviour cloning and implicit Q-learning as baseline algorithms, highlighting the challenges offline agents face, including steady-state offsets and degraded performance near setpoints. To address these issues, we propose a novel deployment-time safety layer that performs gradient-based action correction using input convex neural networks (PICNNs) as learned cost models. The PICNN enables real-time, differentiable correction of policy actions by descending a convex, state-conditioned cost surface, without requiring retraining or environment interaction. Experimental results show that offline RL, particularly when combined with convex action correction, can outperform traditional control approaches and maintain stability across all scenarios. These findings demonstrate the feasibility of integrating offline RL with interpretable and safety-aware corrections for high-stakes chemical process control, and lay the groundwork for more reliable data-driven automation in industrial systems.