Comparing Behavioural Cloning and Reinforcement Learning for Spacecraft Guidance and Control Networks
作者: Harry Holt, Sebastien Origer, Dario Izzo
分类: eess.SY, astro-ph.EP, astro-ph.IM, cs.LG
发布日期: 2025-07-22
💡 一句话要点
对比行为克隆与强化学习训练航天器制导与控制网络
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 航天器制导与控制 行为克隆 强化学习 神经网络 轨迹优化
📋 核心要点
- 现有航天器制导与控制网络训练缺乏行为克隆与强化学习的直接对比评估。
- 提出一种针对制导与控制网络的强化学习训练框架,解耦动作和控制频率,并采用奖励重分配策略。
- 实验表明,行为克隆擅长模仿专家策略,而强化学习在随机环境和发现更优策略方面表现更佳。
📝 摘要(中文)
制导与控制网络(G&CNETs)为航天器在轨制导与控制(G&C)架构提供了一种有前景的替代方案,它提供了一种可微的、端到端的制导与控制架构表示。在训练G&CNETs时,主要有两种范式:行为克隆(BC),它模仿最优轨迹;以及强化学习(RL),它通过试错学习最优行为。尽管这两种方法都在G&CNET相关文献中被采用,但缺乏直接的比较。为了解决这个问题,我们专门针对连续推力航天器轨迹优化任务,对训练G&CNETs的BC和RL进行了系统评估。我们引入了一种为G&CNETs量身定制的新的RL训练框架,该框架结合了解耦的动作和控制频率以及奖励重新分配策略,以稳定训练并提供公平的比较。我们的结果表明,BC训练的G&CNETs擅长紧密复制专家策略行为,从而复制确定性环境的最优控制结构,但可能受到训练数据集质量和覆盖范围的负面限制。相比之下,RL训练的G&CNETs不仅展示了对随机条件的卓越适应性,还可以发现改进次优专家演示的解决方案,有时还会揭示在生成训练样本时未能发现的全局最优策略。
🔬 方法详解
问题定义:论文旨在解决航天器制导与控制网络(G&CNETs)训练中,行为克隆(BC)和强化学习(RL)两种方法的优劣对比问题。现有研究缺乏对这两种方法在G&CNETs训练上的直接比较,无法指导实际应用中如何选择合适的训练方法。同时,传统的RL方法直接应用于G&CNETs训练可能存在训练不稳定等问题。
核心思路:论文的核心思路是通过构建一个公平的实验平台,系统地比较BC和RL在训练G&CNETs上的性能。针对RL训练G&CNETs的挑战,论文提出了一种新的RL训练框架,通过解耦动作和控制频率,以及采用奖励重分配策略,来稳定训练过程,从而实现BC和RL的公平比较。
技术框架:整体框架包括以下几个主要部分:1) G&CNETs模型构建:使用神经网络表示航天器的制导与控制策略。2) BC训练:使用专家轨迹数据训练G&CNETs,使其模仿专家行为。3) RL训练:使用提出的RL训练框架训练G&CNETs,通过试错学习最优策略。4) 性能评估:在不同的任务和环境下评估BC和RL训练的G&CNETs的性能,包括轨迹优化、适应性和鲁棒性等。
关键创新:论文的关键创新在于提出了一个针对G&CNETs的RL训练框架,该框架包含两个主要创新点:1) 解耦动作和控制频率:允许RL算法以较低的频率更新动作,而G&CNETs以较高的频率执行控制,从而提高训练效率和稳定性。2) 奖励重分配策略:通过重新分配奖励,鼓励G&CNETs探索更优的策略,并避免陷入局部最优。
关键设计:在RL训练框架中,动作频率和控制频率的比例是一个关键参数,需要根据具体任务进行调整。奖励重分配策略的具体形式也需要根据任务特点进行设计,例如可以使用稀疏奖励或形状奖励等。G&CNETs的网络结构可以采用不同的设计,例如可以使用多层感知机或循环神经网络等。
🖼️ 关键图片
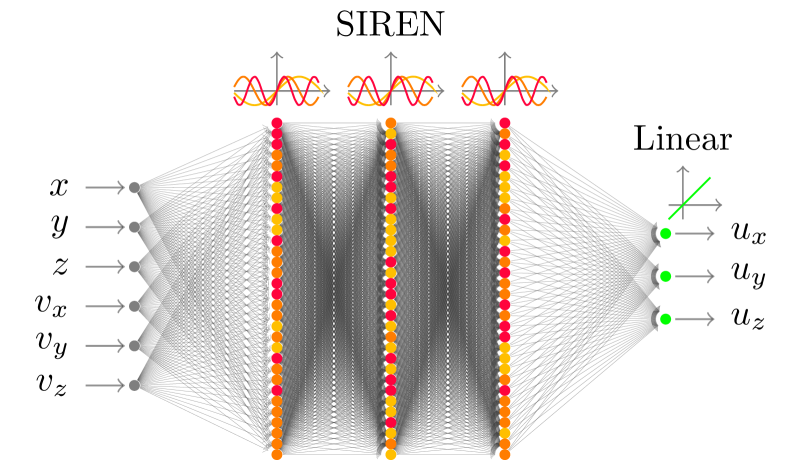
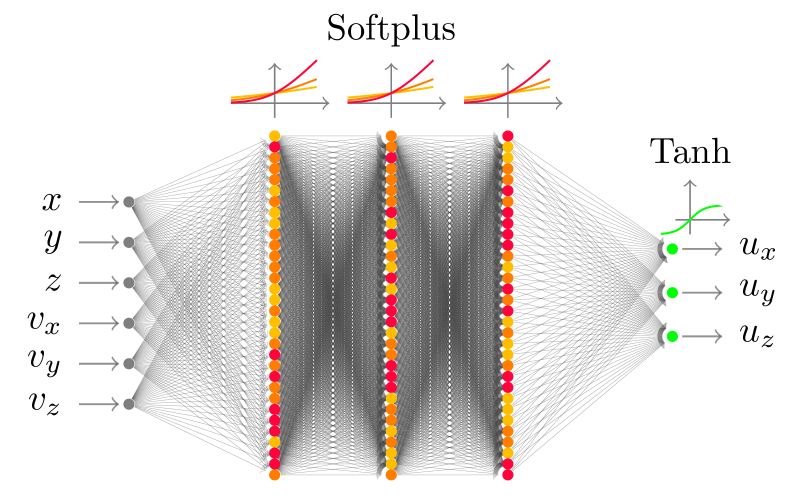

📊 实验亮点
实验结果表明,BC训练的G&CNETs能够很好地复制专家策略,但在随机环境下表现较差。RL训练的G&CNETs不仅能够适应随机环境,还能发现优于专家策略的解决方案。在某些情况下,RL甚至能够找到全局最优策略,而这些策略在生成训练样本时并未被发现。具体性能数据未知,但结论表明RL在探索更优解方面具有优势。
🎯 应用场景
该研究成果可应用于航天器自主导航、轨迹优化和姿态控制等领域。通过选择合适的训练方法(BC或RL),可以提高航天器在轨任务的效率、可靠性和自主性。该研究还有助于推动基于人工智能的航天器G&C技术的发展,为未来的深空探测和空间资源利用提供技术支持。
📄 摘要(原文)
Guidance & control networks (G&CNETs) provide a promising alternative to on-board guidance and control (G&C) architectures for spacecraft, offering a differentiable, end-to-end representation of the guidance and control architecture. When training G&CNETs, two predominant paradigms emerge: behavioural cloning (BC), which mimics optimal trajectories, and reinforcement learning (RL), which learns optimal behaviour through trials and errors. Although both approaches have been adopted in G&CNET related literature, direct comparisons are notably absent. To address this, we conduct a systematic evaluation of BC and RL specifically for training G&CNETs on continuous-thrust spacecraft trajectory optimisation tasks. We introduce a novel RL training framework tailored to G&CNETs, incorporating decoupled action and control frequencies alongside reward redistribution strategies to stabilise training and to provide a fair comparison. Our results show that BC-trained G&CNETs excel at closely replicating expert policy behaviour, and thus the optimal control structure of a deterministic environment, but can be negatively constrained by the quality and coverage of the training dataset. In contrast RL-trained G&CNETs, beyond demonstrating a superior adaptability to stochastic conditions, can also discover solutions that improve upon suboptimal expert demonstrations, sometimes revealing globally optimal strategies that eluded the generation of training samples.