Adaptive DRL for IRS Mirror Orientation in Dynamic OWC Networks
作者: Ahrar N. Hamad, Ahmad Adnan Qidan, Taisir E. H. El-Gorashi, Jaafar M. H. Elmirghani
分类: eess.SY
发布日期: 2025-05-03 (更新: 2025-10-13)
备注: 6 pages, 5 figures
💡 一句话要点
提出基于自适应DRL的IRS镜面控制方法,优化动态OWC网络性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 智能反射面 光无线通信 深度强化学习 确定性策略梯度 动态环境
📋 核心要点
- 传统VLC系统易受视距阻塞影响,难以适应动态环境,需要更灵活的信号覆盖方案。
- 论文提出基于DRL的IRS镜面控制方法,通过实时调整镜面方向,优化动态VLC网络的总速率。
- 实验结果表明,该方法优于传统DQL算法,显著提升了动态环境下的VLC系统性能。
📝 摘要(中文)
智能反射面(IRS)已成为一种有前景的解决方案,可最大限度地减少光无线通信(OWC)系统中的视距(LoS)阻塞并增强信号覆盖,且只需极少的额外功率。本文考虑使用基于镜面的IRS来辅助动态室内可见光通信(VLC)环境。我们提出了一个优化问题,旨在通过调整IRS镜面的方向来最大化总速率。为了实现实时自适应性,该问题被建模为马尔可夫决策过程(MDP),并基于确定性策略梯度开发了一种深度强化学习(DRL)算法,用于动态VLC网络中基于镜面的IRS实时优化。所提出的DRL用于在阻塞和移动性约束下优化镜面朝向移动用户。仿真结果表明,我们提出的DRL算法优于传统的深度Q学习(DQL)算法,并且与随机方向的IRS配置相比,在总速率方面实现了显着改进。
🔬 方法详解
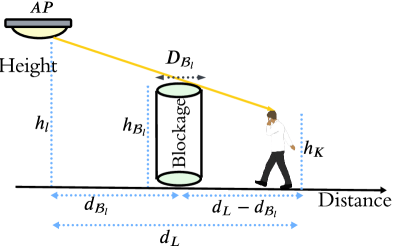
问题定义:论文旨在解决动态室内VLC环境中,由于移动用户和障碍物导致的视距阻塞问题,从而优化系统总速率。现有方法,如静态IRS配置或传统DQL算法,难以适应动态变化的环境,导致性能下降。
核心思路:论文的核心思路是将IRS镜面方向的优化问题建模为马尔可夫决策过程(MDP),并利用深度强化学习(DRL)算法,特别是基于确定性策略梯度的方法,来学习最优的镜面控制策略。这种方法能够根据环境的实时变化,自适应地调整镜面方向,从而最大化系统总速率。
技术框架:整体框架包含以下几个主要部分:1) 环境建模:建立动态VLC环境模型,包括移动用户的位置、障碍物信息等。2) 状态定义:定义MDP的状态空间,包括用户位置、信道状态等信息。3) 动作定义:定义MDP的动作空间,即IRS镜面的方向调整。4) 奖励函数设计:设计奖励函数,以最大化系统总速率为目标。5) DRL算法训练:使用基于确定性策略梯度的DRL算法,训练智能体学习最优的镜面控制策略。
关键创新:最重要的技术创新点在于将基于确定性策略梯度的DRL算法应用于IRS镜面控制。与传统的DQL算法相比,确定性策略梯度算法能够处理连续动作空间,更适合于控制IRS镜面的方向。此外,该方法能够实时适应动态环境,无需预先进行离线训练。
关键设计:论文采用Actor-Critic网络结构,Actor网络负责输出确定性的动作,Critic网络负责评估动作的价值。奖励函数设计为系统总速率的函数,鼓励智能体选择能够最大化总速率的动作。具体参数设置未知,但通常需要根据实际环境进行调整。
🖼️ 关键图片


📊 实验亮点
仿真结果表明,所提出的基于DRL的IRS镜面控制算法优于传统的DQL算法,并在总速率方面实现了显著提升。具体提升幅度未知,但论文强调了其在动态VLC网络中的优越性,证明了该方法在应对视距阻塞和用户移动性方面的有效性。
🎯 应用场景
该研究成果可应用于智能家居、智能办公等室内场景,通过动态调整IRS镜面方向,优化VLC网络的覆盖范围和传输速率,提升用户体验。未来可扩展到更复杂的无线通信环境,如工业自动化、智慧城市等领域,实现更高效、灵活的无线通信。
📄 摘要(原文)
Intelligent reflecting surfaces (IRSs) have emerged as a promising solution to mitigate line-of-sight (LoS) blockages and enhance signal coverage in optical wireless communication (OWC) systems with minimal additional power. In this work, we consider a mirror-based IRS to assist a dynamic indoor visible light communication (VLC) environment. We formulate an optimization problem that aims to maximize the sum rate by adjusting the orientation of the IRS mirrors. To enable real-time adaptability, the problem is modelled as a Markov decision process (MDP), and a deep reinforcement learning (DRL) algorithm is developed based on the deterministic policy gradient for real-time mirror-based IRS optimization in dynamic VLC networks. The proposed DRL is employed to optimize mirror orientation toward mobile users under blockage and mobility constraints. Simulation results demonstrate that our proposed DRL algorithm outperforms the conventional deep Q- learning (DQL) algorithm and achieves substantial improvements in sum rate compared to random-orientation IRS configurations