Beyond Quadratic Costs: A Bregman Divergence Approach to H$_\infty$ Control
作者: Joudi Hajar, Reza Ghane, Babak Hassibi
分类: eess.SY
发布日期: 2025-05-01 (更新: 2025-08-20)
💡 一句话要点
提出基于Bregman散度的H∞控制方法,扩展非二次代价函数适用性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: H∞控制 Bregman散度 非二次代价函数 鲁棒控制 平方完成 最优控制 非线性控制
📋 核心要点
- 传统H∞控制难以处理非二次凸代价函数,导致设计复杂或需依赖近似方法。
- 利用Bregman散度重构目标函数,实现平方完成分解,推导出闭式解的H∞控制器。
- 提出的非线性控制器能实现安全包络、稀疏驱动等策略,并提供严格的H∞性能保证。
📝 摘要(中文)
过去几十年,非二次凸惩罚已经在信号处理和机器学习领域重塑格局;然而,在鲁棒控制中,一般的凸代价函数打破了Riccati和存储函数的结构,使得设计变得难以处理。因此,从业者通常采用近似、启发式方法或在线求解短时域的鲁棒模型预测控制。本文通过将离散时间线性系统的H∞控制扩展到状态、输入和扰动上的严格凸惩罚来弥合这一差距,使用Bregman散度重构目标函数,从而允许平方完成分解。结果是一个闭式、时不变、全信息的稳定控制器,可在无限时域内最小化最坏情况性能比。必要和充分的存在性/最优性条件由类Riccati恒等式以及凹性要求给出;对于二次代价函数,这些条件会简化为经典的H∞代数Riccati方程和相关的负半定条件,从而恢复线性中心控制器。否则,最优控制器是非线性的,并且能够实现具有严格H∞保证的安全包络、稀疏驱动和bang-bang策略。
🔬 方法详解
问题定义:传统的H∞控制主要基于二次代价函数,这限制了其在处理更复杂的控制问题时的灵活性。当代价函数为非二次凸函数时,传统的Riccati方程和存储函数结构不再适用,导致控制器设计变得困难,需要依赖近似方法或在线优化,计算成本高昂。
核心思路:本文的核心思路是利用Bregman散度来重新表达控制目标,从而将非二次凸代价函数纳入H∞控制框架。Bregman散度具有良好的数学性质,允许进行平方完成分解,从而推导出闭式解的控制器。这种方法避免了直接处理复杂的非二次代价函数,而是通过Bregman散度将其转化为更易于处理的形式。
技术框架:该方法首先将H∞控制问题转化为一个基于Bregman散度的优化问题。然后,利用平方完成技术,将优化问题分解为一系列更简单的子问题。通过求解这些子问题,可以得到一个闭式解的控制器。该控制器是一个时不变的、全信息的稳定控制器,能够在无限时域内最小化最坏情况性能比。该框架的关键在于Riccati-like恒等式和凹性条件,它们保证了控制器的存在性和最优性。
关键创新:最重要的技术创新在于将Bregman散度引入H∞控制框架,从而能够处理非二次凸代价函数。与传统的基于二次代价函数的H∞控制相比,该方法具有更强的灵活性和适应性,能够应对更复杂的控制问题。此外,该方法还提供了一个闭式解的控制器,避免了在线优化,降低了计算成本。
关键设计:关键的设计包括选择合适的Bregman散度来匹配特定的非二次凸代价函数。不同的Bregman散度对应于不同的代价函数形式,因此需要根据实际问题进行选择。此外,Riccati-like恒等式和凹性条件是保证控制器存在性和最优性的关键,需要在设计过程中仔细考虑。对于二次代价函数,该方法可以退化为经典的H∞代数Riccati方程,从而验证了该方法的正确性。
🖼️ 关键图片
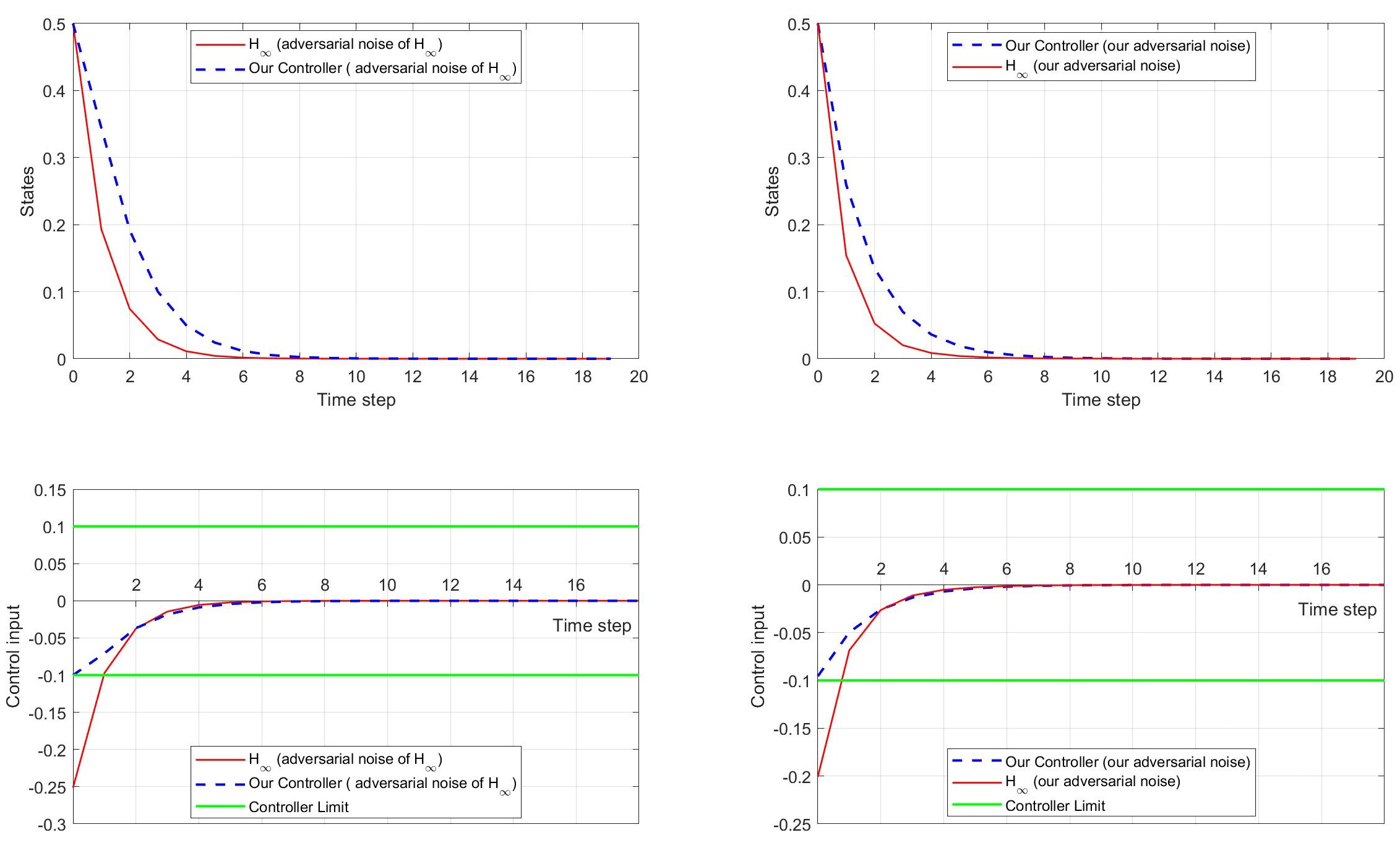

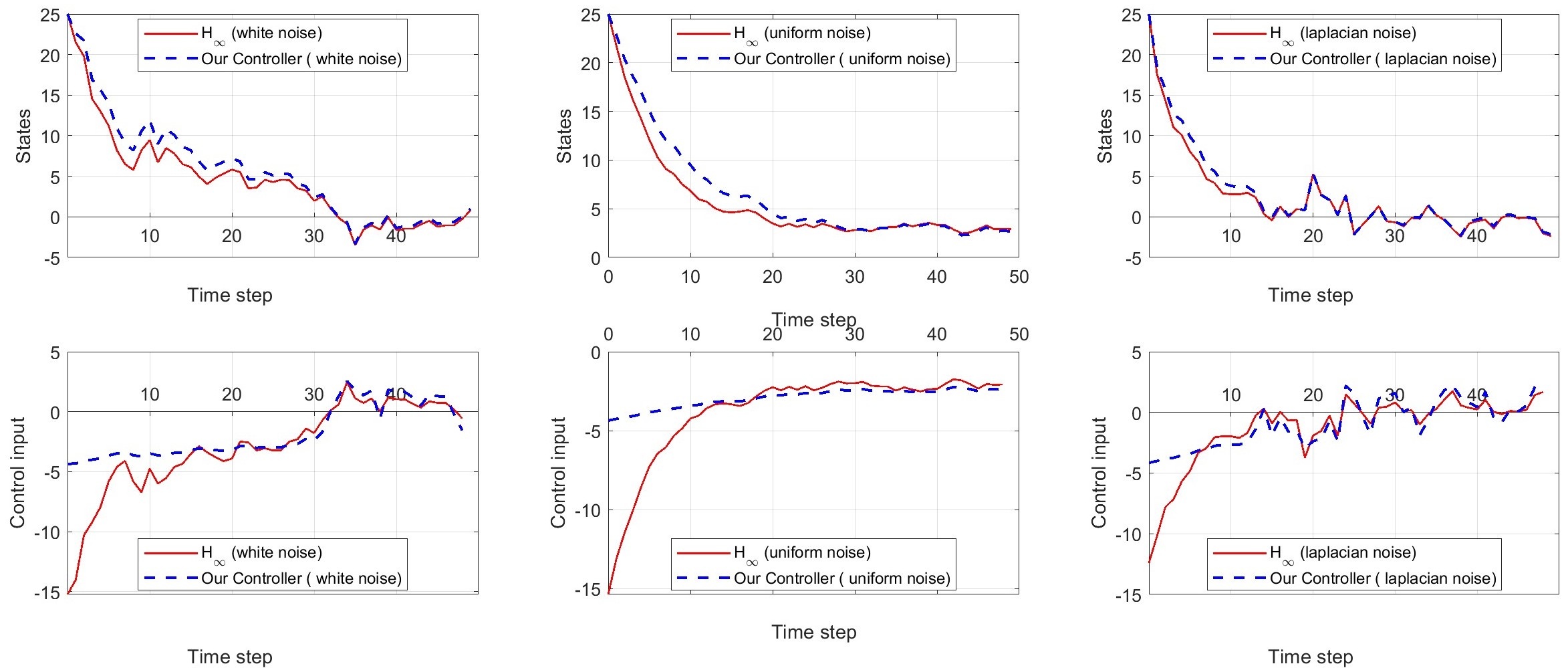
📊 实验亮点
论文通过理论分析证明了所提出的基于Bregman散度的H∞控制方法的有效性。当代价函数为二次函数时,该方法可以退化为经典的H∞代数Riccati方程,验证了其正确性。此外,该方法能够设计出非线性控制器,实现安全包络、稀疏驱动和bang-bang策略,并提供严格的H∞性能保证,这在传统的H∞控制中是难以实现的。
🎯 应用场景
该研究成果可应用于机器人控制、航空航天、电力系统等领域,尤其是在需要考虑安全约束、稀疏控制或bang-bang控制策略的场景下。例如,在机器人控制中,可以利用非二次代价函数来避免碰撞或限制关节力矩;在电力系统中,可以利用稀疏控制策略来降低能源消耗。该方法为设计具有严格性能保证的复杂控制系统提供了新的工具。
📄 摘要(原文)
In the past couple of decades, non-quadratic convex penalties have reshaped signal processing and machine learning; in robust control, however, general convex costs break the Riccati and storage function structure that make the design tractable. Practitioners thus default to approximations, heuristics or robust model predictive control that are solved online for short horizons. We close this gap by extending $H_\infty$ control of discrete-time linear systems to strictly convex penalties on state, input, and disturbance, recasting the objective with Bregman divergences that admit a completion-of-squares decomposition. The result is a closed-form, time-invariant, full-information stabilizing controller that minimizes a worst-case performance ratio over the infinite horizon. Necessary and sufficient existence/optimality conditions are given by a Riccati-like identity together with a concavity requirement; with quadratic costs, these collapse to the classical $H_\infty$ algebraic Riccati equation and the associated negative-semidefinite condition, recovering the linear central controller. Otherwise, the optimal controller is nonlinear and can enable safety envelopes, sparse actuation, and bang-bang policies with rigorous $H_\infty$ guarantees.