InstructMPC: A Human-LLM-in-the-Loop Framework for Context-Aware Control
作者: Ruixiang Wu, Jiahao Ai, Tongxin Li
分类: eess.SY
发布日期: 2025-04-08 (更新: 2025-09-05)
💡 一句话要点
提出InstructMPC以解决传统MPC缺乏上下文感知的问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型预测控制 上下文感知 大型语言模型 动态交互 优化算法
📋 核心要点
- 传统MPC方法在实际应用中难以有效整合上下文信息和专家指令,导致控制效果受限。
- InstructMPC框架通过引入大型语言模型,实时整合人类指令,生成上下文感知的预测轨迹。
- 该方法在理论上提供了性能保证,并在优化过程中实现了显著的控制效果提升。
📝 摘要(中文)
模型预测控制(MPC)是一种在能源管理、建筑控制和自主系统等领域广泛应用的强大控制策略。然而,传统MPC在实际应用中面临挑战,无法有效整合上下文特定的预测和专家指令。为此,本文提出了InstructMPC框架,通过大型语言模型(LLM)实时整合人类指令,以生成上下文感知的预测。该方法采用语言到分布(L2D)模块,将上下文信息转换为预测干扰轨迹,并将其纳入MPC优化中。与现有的上下文感知和基于语言的MPC模型不同,InstructMPC实现了动态的人类-LLM交互,并在闭环中微调L2D模块,理论上保证了性能,在线性动态下实现了$O( ext{sqrt}(T ext{log} T))$的遗憾界限。
🔬 方法详解
问题定义:本文旨在解决传统MPC在实际应用中无法有效整合上下文特定预测和人类专家指令的问题,导致控制效果不足。
核心思路:InstructMPC框架通过实时整合人类指令,利用大型语言模型(LLM)生成上下文感知的预测,提升MPC的控制性能。
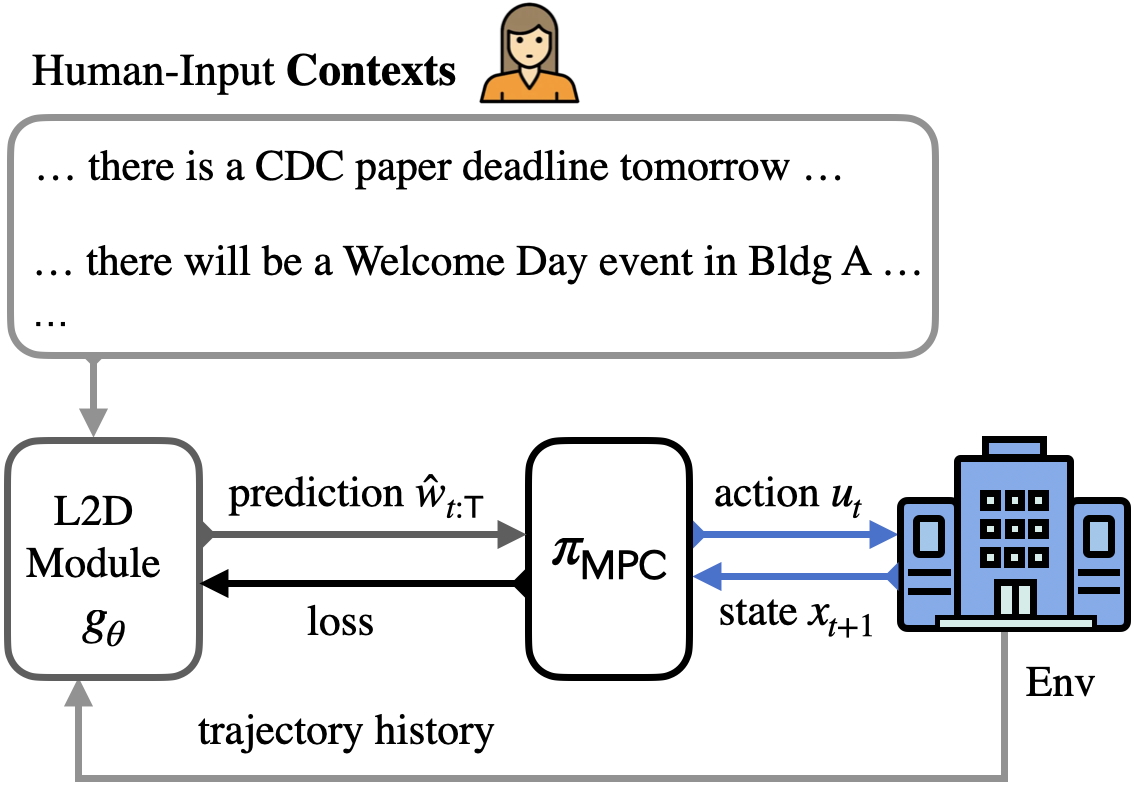
技术框架:整体架构包括一个语言到分布(L2D)模块,该模块将上下文信息转换为预测干扰轨迹,并将这些轨迹纳入MPC的优化过程。该框架支持动态的人类-LLM交互,并在闭环中微调L2D模块。
关键创新:InstructMPC的核心创新在于实现了动态的人类-LLM交互,允许实时调整预测,并在理论上提供了性能保证,与现有方法相比,显著提升了上下文感知能力。
关键设计:在技术细节上,采用了定制的损失函数和先进的微调方法(如直接偏好优化DPO),确保L2D模块的有效性,并实现了在线优化过程中的性能提升。
🖼️ 关键图片

📊 实验亮点
实验结果表明,InstructMPC在优化过程中实现了显著的性能提升,在线性动态下达到了$O( ext{sqrt}(T ext{log} T))$的遗憾界限,相较于传统MPC方法,控制效果有了明显改善,验证了其理论性能保证。
🎯 应用场景
InstructMPC框架具有广泛的应用潜力,特别是在需要实时决策和控制的领域,如智能建筑管理、自动驾驶汽车和能源系统优化等。通过有效整合人类专家的指令,该方法能够提升系统的响应能力和控制精度,具有重要的实际价值和未来影响。
📄 摘要(原文)
Model Predictive Control (MPC) is a powerful control strategy widely utilized in domains like energy management, building control, and autonomous systems. However, its effectiveness in real-world settings is challenged by the need to incorporate context-specific predictions and expert instructions, which traditional MPC often neglects. We propose InstructMPC, a novel framework that addresses this gap by integrating real-time human instructions through a Large Language Model (LLM) to produce context-aware predictions for MPC. Our method employs a Language-to-Distribution (L2D) module to translate contextual information into predictive disturbance trajectories, which are then incorporated into the MPC optimization. Unlike existing context-aware and language-based MPC models, InstructMPC enables dynamic human-LLM interaction and fine-tunes the L2D module in a closed loop with theoretical performance guarantees, achieving a regret bound of $O(\sqrt{T\log T})$ for linear dynamics when optimized via advanced fine-tuning methods such as Direct Preference Optimization (DPO) using a tailored loss function.