MAD: A Magnitude And Direction Policy Parametrization for Stability Constrained Reinforcement Learning
作者: Luca Furieri, Sucheth Shenoy, Danilo Saccani, Andrea Martin, Giancarlo Ferrari-Trecate
分类: eess.SY, cs.LG
发布日期: 2025-04-03 (更新: 2025-10-05)
💡 一句话要点
提出MAD策略参数化方法,保证非线性系统强化学习的闭环稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 稳定性约束 策略参数化 非线性系统 闭环控制
📋 核心要点
- 现有基于Youla参数化和系统级综合的强化学习方法难以参数化Lp稳定算子,限制了其在复杂系统中的应用。
- MAD策略将控制输入分解为幅度和方向,幅度由Lp稳定算子控制,方向由状态相关特征决定,从而保证闭环稳定性。
- 实验表明,基于DDPG训练的MAD策略在未见过的场景中表现良好,在保证闭环稳定性的同时,性能与标准神经网络策略相当。
📝 摘要(中文)
本文提出了一种幅度与方向(MAD)策略,这是一种用于强化学习(RL)的策略参数化方法,能够保持非线性动力系统的Lp闭环稳定性。尽管基于非线性Youla参数化和系统级综合的方法在描述所有稳定控制器方面具有完备性,但它们受到参数化Lp稳定算子的困难的显著影响。相比之下,MAD策略引入了对状态相关特征的显式反馈——这是强化学习流程成功的关键要素——而不会危及闭环稳定性。这是通过让控制输入的幅度由扰动反馈Lp稳定算子描述,同时基于状态相关特征通过通用函数逼近器选择其方向来实现的。我们进一步描述了MAD策略在模型失配下的鲁棒稳定性。与现有的扰动反馈策略参数化不同,MAD策略引入了与无模型RL流程兼容的状态反馈组件,确保闭环稳定性,而无需超出假设开环稳定性的模型信息。数值实验表明,使用深度确定性策略梯度(DDPG)方法训练的MAD策略可以推广到未见过的场景——匹配标准神经网络策略的性能,同时通过设计保证闭环稳定性。
🔬 方法详解
问题定义:论文旨在解决在非线性动力系统中使用强化学习时,如何保证闭环系统稳定性的问题。现有方法,如基于Youla参数化和系统级综合的方法,虽然理论上完备,但实际应用中难以参数化Lp稳定算子,导致难以训练出稳定的控制器。此外,许多强化学习方法依赖于神经网络等通用函数逼近器,难以提供稳定性保证。
核心思路:论文的核心思路是将控制输入分解为幅度和方向两部分,分别进行控制。幅度的控制采用Lp稳定的扰动反馈算子,保证幅度的稳定性。方向的控制则采用通用的函数逼近器,如神经网络,根据状态信息选择合适的控制方向。通过这种方式,既能利用函数逼近器的灵活性,又能保证系统的稳定性。
技术框架:MAD策略的整体框架如下:首先,将控制输入u分解为幅值r和方向v,即u = r * v。幅值r由一个Lp稳定的扰动反馈算子控制,该算子接收扰动信号作为输入,输出幅值。方向v由一个神经网络控制,该网络接收状态信息作为输入,输出控制方向。整个系统构成一个闭环控制系统,通过强化学习算法训练神经网络,优化控制方向,同时保证幅值的稳定性。
关键创新:MAD策略的关键创新在于将控制输入分解为幅度和方向,并分别进行控制。这种分解方式使得可以在保证幅值稳定性的前提下,利用函数逼近器灵活地控制方向。与现有的扰动反馈策略参数化方法相比,MAD策略引入了状态反馈组件,使其能够与无模型强化学习流程兼容。
关键设计:MAD策略的关键设计包括:1) 使用Lp稳定的扰动反馈算子控制幅值,保证幅值的稳定性。2) 使用神经网络控制方向,利用神经网络的函数逼近能力。3) 使用深度确定性策略梯度(DDPG)算法训练神经网络,优化控制方向。4) 论文还分析了MAD策略在模型失配情况下的鲁棒稳定性。
🖼️ 关键图片
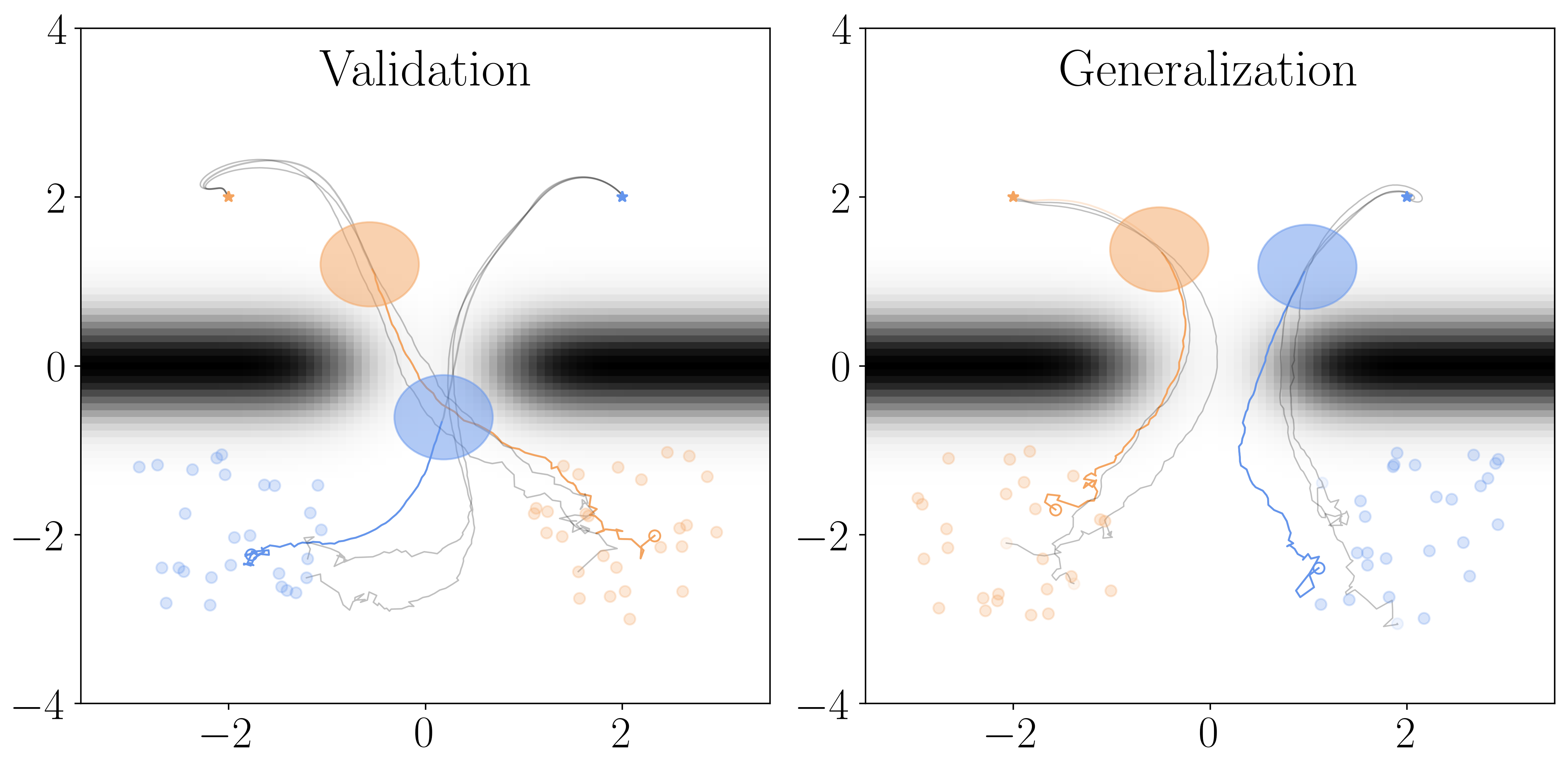

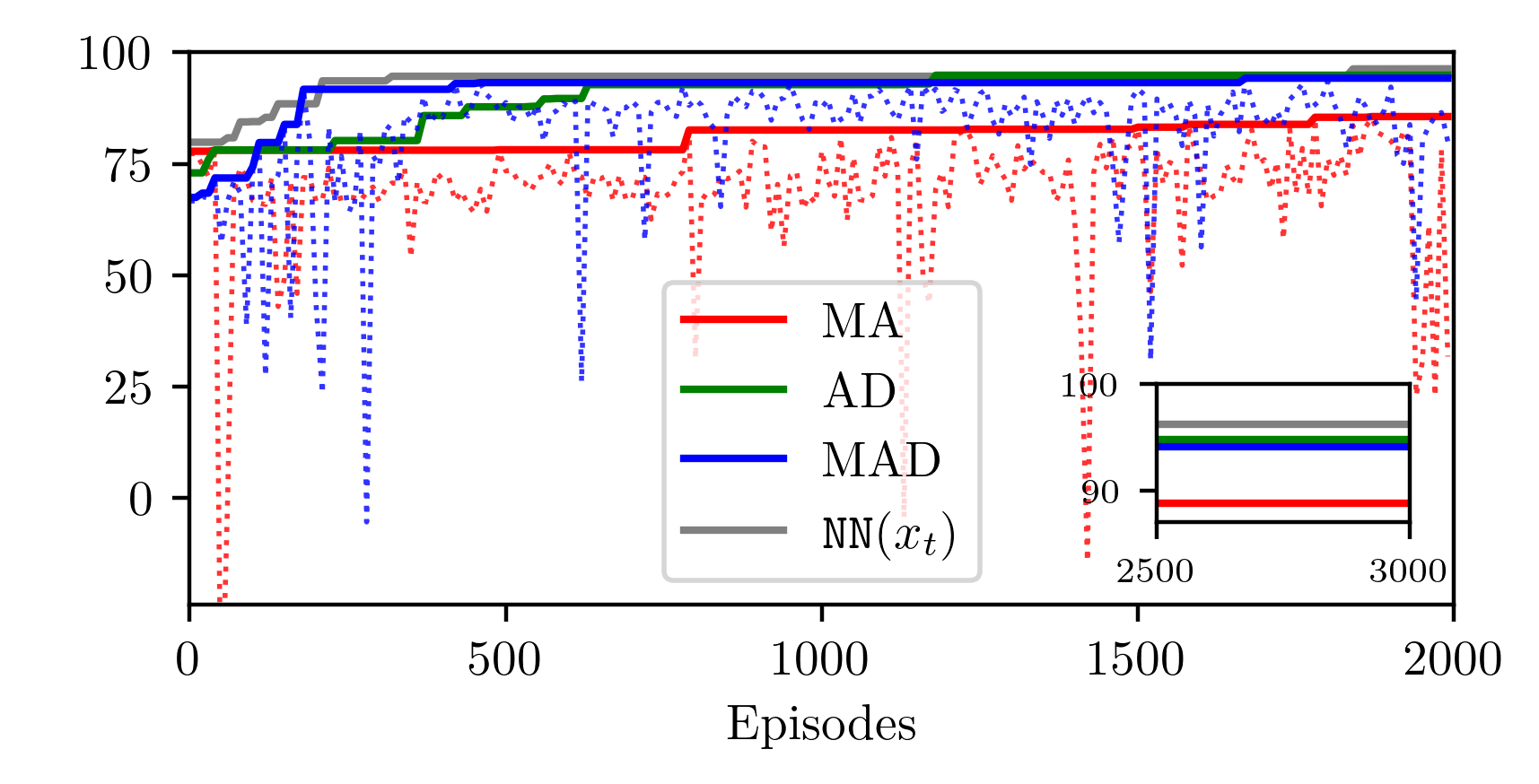
📊 实验亮点
实验结果表明,使用DDPG训练的MAD策略在未见过的场景中表现良好,能够匹配标准神经网络策略的性能,同时保证闭环稳定性。这表明MAD策略具有良好的泛化能力和鲁棒性,能够在实际应用中发挥重要作用。具体来说,MAD策略在保证稳定性的前提下,性能与传统神经网络策略相当,验证了该方法在实际应用中的有效性。
🎯 应用场景
MAD策略参数化方法可应用于各种需要保证稳定性的控制任务中,例如机器人控制、自动驾驶、飞行器控制等。该方法能够提高控制系统的鲁棒性和安全性,降低系统风险,具有重要的实际应用价值和广阔的应用前景。未来,该方法有望在更多复杂控制系统中得到应用,并推动强化学习在控制领域的进一步发展。
📄 摘要(原文)
We introduce magnitude and direction (MAD) policies, a policy parameterization for reinforcement learning (RL) that preserves Lp closed-loop stability for nonlinear dynamical systems. Despite their completeness in describing all stabilizing controllers, methods based on nonlinear Youla and system-level synthesis are significantly impacted by the difficulty of parametrizing Lp-stable operators. In contrast, MAD policies introduce explicit feedback on state-dependent features - a key element behind the success of reinforcement learning pipelines - without jeopardizing closed-loop stability. This is achieved by letting the magnitude of the control input be described by a disturbance-feedback Lp-stable operator, while selecting its direction based on state-dependent features through a universal function approximator. We further characterize the robust stability properties of MAD policies under model mismatch. Unlike existing disturbance-feedback policy parametrizations, MAD policies introduce state-feedback components compatible with model-free RL pipelines, ensuring closed-loop stability with no model information beyond assuming open-loop stability. Numerical experiments show that MAD policies trained with deep deterministic policy gradient (DDPG) methods generalize to unseen scenarios - matching the performance of standard neural network policies while guaranteeing closed-loop stability by design.