Markov Potential Game Construction and Multi-Agent Reinforcement Learning with Applications to Autonomous Driving
作者: Huiwen Yan, Mushuang Liu
分类: eess.SY
发布日期: 2025-03-28 (更新: 2025-11-21)
💡 一句话要点
提出马尔可夫势博弈构造方法,并应用于自动驾驶多智能体强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 马尔可夫博弈 马尔可夫势博弈 纳什均衡 自动驾驶
📋 核心要点
- 多智能体强化学习中,求解一般马尔可夫博弈的纳什均衡非常困难,阻碍了智能体策略的优化。
- 论文提出了构造马尔可夫势博弈的充分条件,通过设计奖励函数和MDP,保证纳什均衡的存在和算法的收敛性。
- 在自动驾驶场景下进行了数值实验,验证了所提方法的有效性,为多智能体强化学习算法提供了理论保障。
📝 摘要(中文)
马尔可夫博弈(MGs)为多智能体强化学习(MARL)提供了一个数学基础,使自利的智能体能够在共享环境中与其他智能体交互时学习其最优策略。然而,由于MG问题的复杂性,对于一般和的MG,寻求(马尔可夫完美)纳什均衡(NE)通常非常具有挑战性。马尔可夫势博弈(MPGs)是MGs的一个特殊类别,它具有吸引人的特性,例如保证纯NE的存在和保证梯度博弈算法的收敛性,从而为许多MARL算法在其NE寻求过程中带来理想的特性。然而,如何构造MPGs的问题仍然悬而未决。本文提供了奖励设计和马尔可夫决策过程(MDP)的充分条件,在该条件下,MG是一个MPG。报告了在自动驾驶应用中的数值结果。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中,一般马尔可夫博弈难以求解纳什均衡的问题。现有方法在复杂环境中难以保证收敛性和解的质量,限制了其在实际场景中的应用,例如自动驾驶等需要多智能体协作的场景。
核心思路:论文的核心思路是寻找马尔可夫博弈成为马尔可夫势博弈的充分条件。马尔可夫势博弈具有良好的性质,如保证纯纳什均衡的存在和梯度博弈算法的收敛性。通过将一般马尔可夫博弈转化为马尔可夫势博弈,可以更容易地找到纳什均衡,从而提高多智能体强化学习算法的性能。
技术框架:论文的技术框架主要包括以下几个步骤:1) 定义马尔可夫博弈和马尔可夫势博弈;2) 推导马尔可夫博弈成为马尔可夫势博弈的充分条件,这些条件与奖励函数的设计和马尔可夫决策过程的结构有关;3) 基于这些条件,设计奖励函数和MDP,使得构建的马尔可夫博弈成为马尔可夫势博弈;4) 在自动驾驶等实际场景中进行实验验证。
关键创新:论文的关键创新在于提出了构造马尔可夫势博弈的充分条件。与现有方法相比,该方法提供了一种系统性的方法来设计奖励函数和MDP,从而保证构建的马尔可夫博弈具有良好的性质。这为多智能体强化学习算法的设计和分析提供了理论基础。
关键设计:论文的关键设计在于如何选择合适的奖励函数和MDP结构,以满足马尔可夫势博弈的充分条件。具体的奖励函数和MDP结构需要根据具体的应用场景进行设计。论文在自动驾驶场景下,设计了考虑交通规则、安全性和效率的奖励函数,并构建了相应的MDP模型。具体的参数设置和网络结构在论文中未详细描述,属于未知信息。
🖼️ 关键图片
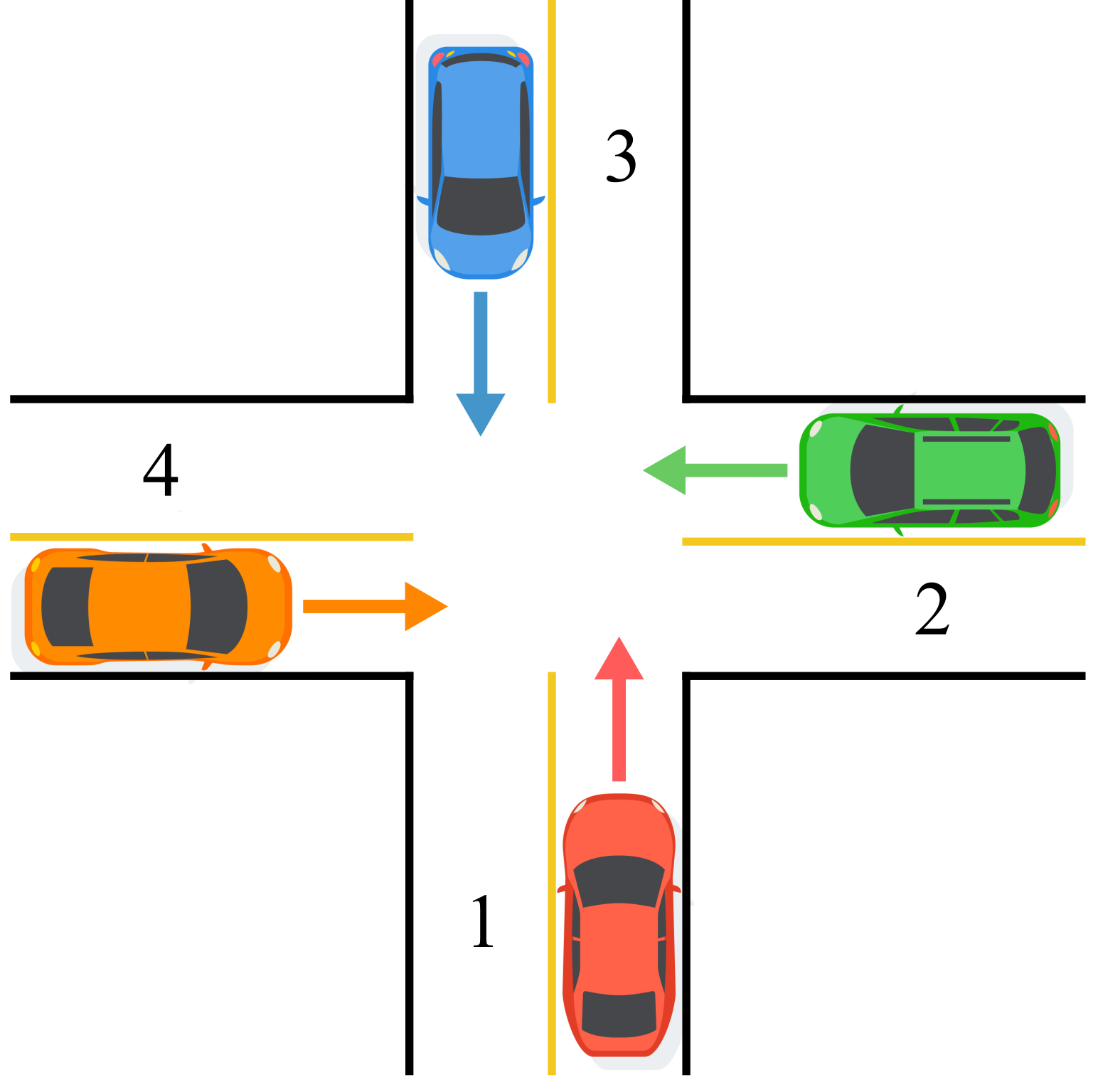


📊 实验亮点
论文在自动驾驶场景下进行了数值实验,验证了所提方法的有效性。具体的性能数据、对比基线和提升幅度在摘要中未提及,属于未知信息。但论文强调了该方法为多智能体强化学习算法提供了理论保障,并展示了其在实际应用中的潜力。
🎯 应用场景
该研究成果可广泛应用于多智能体协作的场景,例如自动驾驶、机器人协同、交通控制、资源分配等。通过将一般马尔可夫博弈转化为马尔可夫势博弈,可以更容易地设计和训练多智能体强化学习算法,提高系统的性能和鲁棒性。未来,该方法有望推动多智能体系统的智能化发展。
📄 摘要(原文)
Markov games (MGs) provide a mathematical foundation for multi-agent reinforcement learning (MARL), enabling self-interested agents to learn their optimal policies while interacting with others in a shared environment. However, due to the complexities of an MG problem, seeking (Markov perfect) Nash equilibrium (NE) is often very challenging for a general-sum MG. Markov potential games (MPGs), which are a special class of MGs, have appealing properties such as guaranteed existence of pure NEs and guaranteed convergence of gradient play algorithms, thereby leading to desirable properties for many MARL algorithms in their NE-seeking processes. However, the question of how to construct MPGs has remained open. This paper provides sufficient conditions on the reward design and on the Markov decision process (MDP), under which an MG is an MPG. Numerical results on autonomous driving applications are reported.