Dynamics-Invariant Quadrotor Control using Scale-Aware Deep Reinforcement Learning
作者: Varad Vaidya, Jishnu Keshavan
分类: eess.SY, cs.RO
发布日期: 2025-03-09
备注: This work has been submitted to the IEEE for possible publication
期刊: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
DOI: 10.1109/IROS60139.2025.11247554
💡 一句话要点
提出基于尺度感知深度强化学习的动力学不变四旋翼控制方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四旋翼控制 深度强化学习 动力学不变性 尺度感知 轨迹跟踪 无人机 动力学随机化
📋 核心要点
- 四旋翼飞行器在动态变化(如载荷、气动干扰)下难以实现鲁棒的轨迹跟踪。
- 提出一种深度强化学习框架,直接优化力/扭矩输入,实现动力学不变性,无需中间控制层。
- 通过尺度感知动力学随机化,该方法在不同尺寸的无人机上表现出优越的跟踪精度,提升达85%。
📝 摘要(中文)
针对有效载荷变化、气动干扰和平台差异等动态变化带来的四旋翼轨迹跟踪难题,本文提出了一种深度强化学习(DRL)框架,该框架通过直接优化力/扭矩输入来实现物理动力学不变性,无需传统中间控制层。该架构集成了时间轨迹编码器(处理有限范围的参考位置/速度)和一个潜在动力学编码器(基于历史状态-动作对训练,以建模特定平台特性)。此外,引入了由四旋翼臂长参数化的尺度感知动力学随机化方法,使该方法能够在30g到2.1kg的无人机上保持稳定,并且跟踪精度比其他DRL基线高85%。在Crazyflie 2.1四旋翼上的大量真实世界验证(包括200多次飞行)表明,该方法能够稳健地适应风、地面效应和摆动有效载荷,同时在高达2.0 m/s的速度下实现小于0.05m的RMSE。这项工作引入了一种通用的四旋翼控制范例,可以补偿各种条件和尺度下的动态差异,为更具弹性的空中系统铺平道路。
🔬 方法详解
问题定义:四旋翼飞行器在实际应用中,由于有效载荷变化、气动干扰以及不同平台之间的差异,其动力学特性会发生显著变化。传统的控制方法往往依赖于精确的动力学模型,难以适应这些动态变化,导致轨迹跟踪性能下降甚至不稳定。现有方法的痛点在于缺乏对不同尺度和动态环境的适应性,需要针对特定场景进行调整和优化。
核心思路:本文的核心思路是利用深度强化学习(DRL)直接学习从状态到力/扭矩输入的映射,从而避免对中间控制层的依赖。通过训练一个能够适应不同动力学特性的策略网络,实现对四旋翼的鲁棒控制。关键在于引入了尺度感知动力学随机化,使得训练得到的策略能够泛化到不同尺寸的四旋翼上。
技术框架:整体架构包含三个主要模块:1) 时间轨迹编码器,用于处理有限范围的参考位置和速度信息;2) 潜在动力学编码器,基于历史状态-动作对学习平台特定的动力学特性;3) 策略网络,根据编码器的输出,直接输出力/扭矩控制指令。训练过程中,采用尺度感知动力学随机化,模拟不同尺寸和动态环境下的四旋翼行为。
关键创新:最重要的技术创新点在于尺度感知动力学随机化。通过将四旋翼的臂长作为随机化参数,使得训练得到的策略能够适应不同尺寸的四旋翼。这与传统的动力学随机化方法不同,后者通常只关注质量、惯量等参数的变化,而忽略了尺寸对动力学的影响。这种尺度感知的方法能够显著提高策略的泛化能力。
关键设计:时间轨迹编码器和潜在动力学编码器均采用循环神经网络(RNN)结构,用于处理时序信息。策略网络采用多层感知机(MLP)结构,将编码器的输出映射到力/扭矩控制指令。损失函数主要包括轨迹跟踪误差和控制量惩罚项。尺度感知动力学随机化通过在训练过程中随机改变四旋翼的臂长来实现,臂长的范围根据实际应用场景进行设置。
🖼️ 关键图片

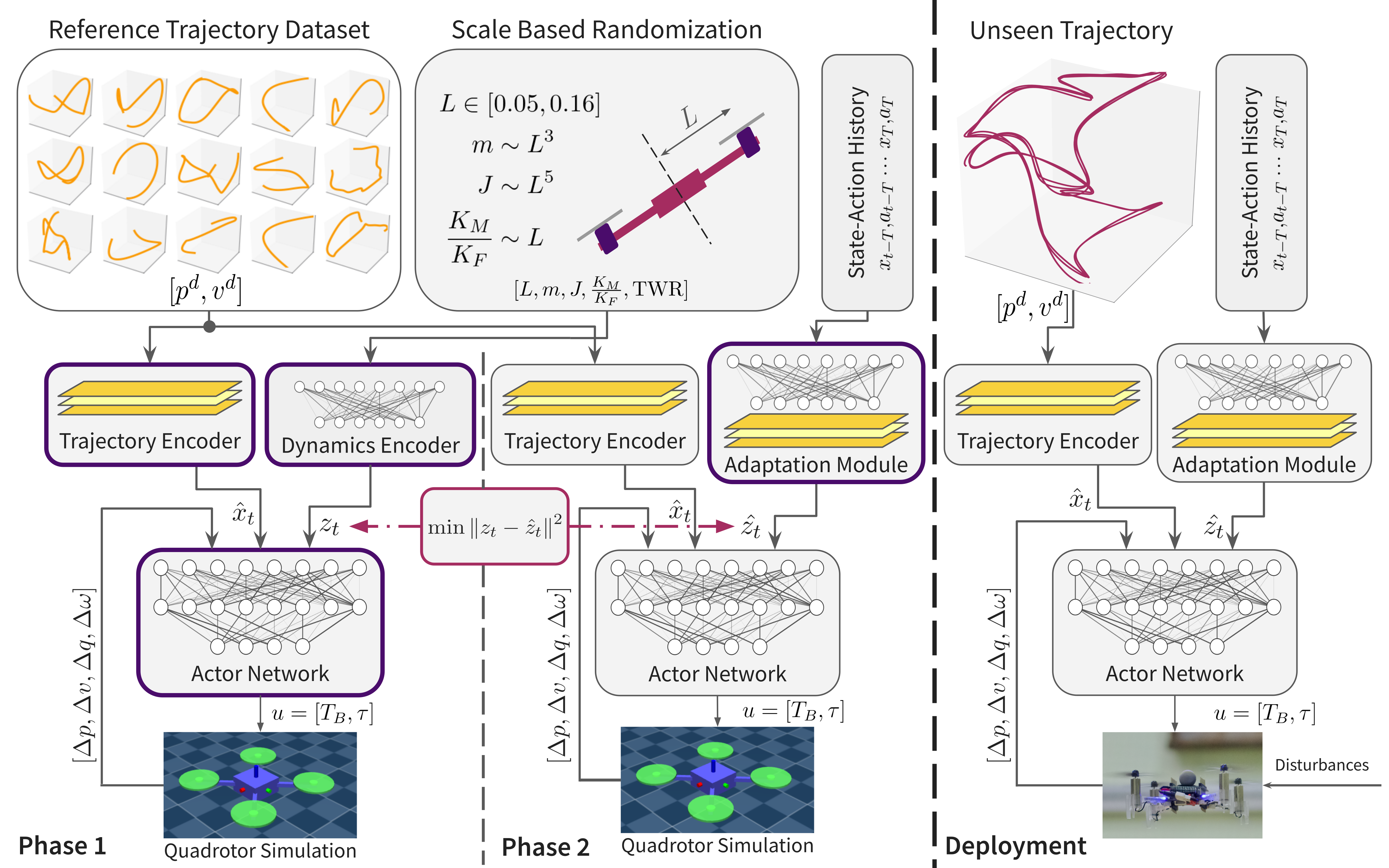

📊 实验亮点
实验结果表明,该方法在不同尺寸的四旋翼上均能实现精确的轨迹跟踪。在Crazyflie 2.1四旋翼上的真实飞行实验中,该方法能够在高达2.0 m/s的速度下实现小于0.05m的RMSE。与其他DRL基线相比,该方法的跟踪精度提高了85%。此外,该方法还表现出对风、地面效应和摆动有效载荷的良好适应性。
🎯 应用场景
该研究成果可广泛应用于物流配送、环境监测、农业植保、灾害救援等领域。通过提高四旋翼飞行器在复杂环境下的稳定性和鲁棒性,可以实现更高效、更安全的空中作业。该方法有望推动无人机技术的普及和应用,并为未来的自主飞行系统提供新的解决方案。
📄 摘要(原文)
Due to dynamic variations such as changing payload, aerodynamic disturbances, and varying platforms, a robust solution for quadrotor trajectory tracking remains challenging. To address these challenges, we present a deep reinforcement learning (DRL) framework that achieves physical dynamics invariance by directly optimizing force/torque inputs, eliminating the need for traditional intermediate control layers. Our architecture integrates a temporal trajectory encoder, which processes finite-horizon reference positions/velocities, with a latent dynamics encoder trained on historical state-action pairs to model platform-specific characteristics. Additionally, we introduce scale-aware dynamics randomization parameterized by the quadrotor's arm length, enabling our approach to maintain stability across drones spanning from 30g to 2.1kg and outperform other DRL baselines by 85% in tracking accuracy. Extensive real-world validation of our approach on the Crazyflie 2.1 quadrotor, encompassing over 200 flights, demonstrates robust adaptation to wind, ground effects, and swinging payloads while achieving less than 0.05m RMSE at speeds up to 2.0 m/s. This work introduces a universal quadrotor control paradigm that compensates for dynamic discrepancies across varied conditions and scales, paving the way for more resilient aerial systems.