Robust Mean Field Social Control: A Unified Reinforcement Learning Framework
作者: Zhenhui Xu, Jiayu Chen, Bing-Chang Wang, Yuhu Wu, Tielong Shen
分类: eess.SY
发布日期: 2025-02-27 (更新: 2025-09-14)
💡 一句话要点
提出一种鲁棒平均场社会控制的统一强化学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 平均场控制 强化学习 鲁棒控制 多智能体系统 Riccati方程
📋 核心要点
- 现有方法在解决具有乘性噪声的平均场社会控制问题时,面临求解不定Riccati方程的挑战。
- 论文提出一个统一的双环迭代框架,处理不定Riccati型方程,并证明了内外环迭代的收敛性。
- 通过积分强化学习,该方法降低了对智能体动态精确知识的需求,并验证了算法的鲁棒性。
📝 摘要(中文)
本文研究了存在乘性噪声的线性二次高斯鲁棒平均场社会控制问题。目标是在不需要完全了解智能体动态的情况下,计算渐近分散策略。主要的挑战在于求解用于反馈增益的不定随机代数Riccati方程和用于前馈增益的不定代数Riccati方程。为了克服这些挑战,首先提出了一个统一的双环迭代框架,用于处理这两种不定Riccati型方程,并为外环和内环迭代提供了严格的收敛性证明。其次,考虑到迭代过程中由于估计和建模误差可能产生的偏差,使用小扰动输入-状态稳定性技术验证了所提出算法的鲁棒性。因此,即使存在扰动,也能保证收敛到最优解的邻域。最后,为了放宽需要精确了解智能体动态的限制,采用积分强化学习技术在双环迭代框架内开发了一种数据驱动方法。数值例子验证了所提出算法的有效性。
🔬 方法详解
问题定义:论文旨在解决具有乘性噪声的线性二次高斯鲁棒平均场社会控制问题。现有方法通常需要精确的智能体动态知识,并且在求解不定Riccati方程时面临挑战,这限制了它们在实际复杂系统中的应用。此外,建模误差和估计偏差可能导致算法性能下降。
核心思路:论文的核心思路是设计一个双环迭代框架,该框架能够有效地求解不定Riccati型方程,并利用积分强化学习技术来学习智能体的动态,从而降低对先验知识的依赖。此外,通过鲁棒性分析,确保算法在存在扰动的情况下仍然能够收敛到最优解的邻域。
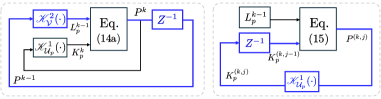
技术框架:该框架包含两个主要循环:外环和内环。内环用于求解不定随机代数Riccati方程和不定代数Riccati方程,以获得反馈和前馈增益。外环则利用积分强化学习技术,基于数据驱动的方式更新智能体的动态模型。此外,还进行了鲁棒性分析,以确保算法在存在扰动的情况下仍然能够稳定收敛。
关键创新:该论文的关键创新在于:1) 提出了一个统一的双环迭代框架,能够有效地处理不定Riccati型方程;2) 利用积分强化学习技术,降低了对智能体动态精确知识的需求,实现了数据驱动的控制;3) 通过小扰动输入-状态稳定性分析,验证了算法的鲁棒性,确保了在存在扰动的情况下仍然能够收敛到最优解的邻域。
关键设计:双环迭代框架的具体实现涉及选择合适的迭代算法来求解不定Riccati方程,例如,可以使用策略迭代或值迭代方法。积分强化学习部分需要设计合适的奖励函数和状态表示,以便智能体能够有效地学习动态模型。鲁棒性分析则需要选择合适的扰动模型,并利用输入-状态稳定性理论来证明算法的鲁棒性。
🖼️ 关键图片


📊 实验亮点
论文通过数值实验验证了所提出算法的有效性。实验结果表明,即使在存在乘性噪声和建模误差的情况下,该算法仍然能够有效地控制多智能体系统,并实现良好的性能。与传统的基于模型的方法相比,该算法具有更强的鲁棒性和适应性。
🎯 应用场景
该研究成果可应用于大规模多智能体系统,例如交通控制、电力网络管理、金融市场调控等领域。通过学习智能体的动态,并设计鲁棒的控制策略,可以有效地提高系统的稳定性和性能,并降低对先验知识的依赖。未来,该方法有望推广到更复杂的非线性系统和非高斯噪声环境。
📄 摘要(原文)
This paper studies linear quadratic Gaussian robust mean field social control problems in the presence of multiplicative noise. We aim to compute asymptotic decentralized strategies without requiring full prior knowledge of agents' dynamics. The primary challenges lie in solving an indefinite stochastic algebraic Riccati equation for feedback gains, and an indefinite algebraic Riccati equation for feedforward gains. To overcome these challenges, we first propose a unified dual-loop iterative framework that handles both indefinite Riccati-type equations, and provide rigorous convergence proofs for both the outer-loop and inner-loop iterations. Secondly, considering the potential biases arising in the iterative processes due to estimation and modeling errors, we verify the robustness of the proposed algorithm using the small-disturbance input-to-state stability technique. Convergence to a neighborhood of the optimal solution is thus ensured, even in the existence of disturbances. Finally, to relax the limitation of requiring precise knowledge of agents' dynamics, we employ the integral reinforcement learning technique to develop a data-driven method within the dual-loop iterative framework. A numerical example is provided to demonstrate the effectiveness of the proposed algorithm.