Learning-Enhanced Safeguard Control for High-Relative-Degree Systems: Robust Optimization under Disturbances and Faults
作者: Xinyang Wang, Hongwei Zhang, Shimin Wang, Wei Xiao, Martin Guay
分类: eess.SY, cs.AI, cs.LG, math.OC, nlin.AO
发布日期: 2025-01-26
备注: 16 pages, 6 figures
💡 一句话要点
针对高相对阶系统,提出学习增强的安全控制方法,实现抗扰动和容错的鲁棒优化。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 安全控制 控制 barrier 函数 高相对阶系统 鲁棒优化
📋 核心要点
- 现有方法在安全探索时过于保守,影响性能,而追求高性能又可能牺牲安全性,如何在学习控制中平衡安全与性能是一个挑战。
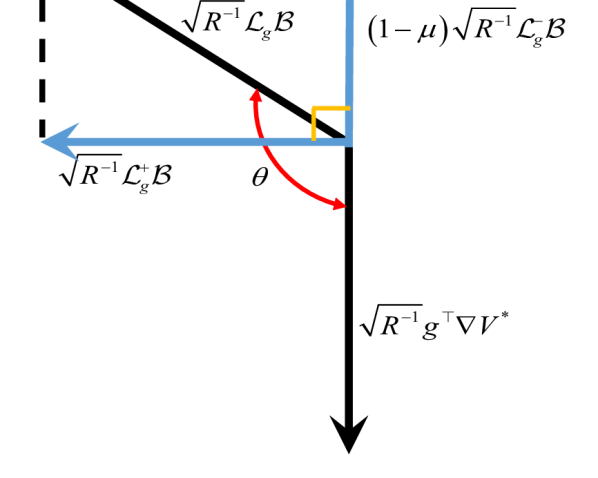
- 论文提出高阶倒数控制 barrier 函数(HO-RCBF)处理高相对阶约束,并利用梯度相似性量化安全与性能梯度的关系。
- 通过梯度操作和自适应机制,在安全RL框架下提升性能,仿真结果验证了该方法在处理高相对阶约束、增强鲁棒性和提高性能方面的有效性。
📝 摘要(中文)
本文旨在解决基于强化学习(RL)的非线性系统最优控制问题,该系统具有高相对阶状态约束以及未知的时变扰动/执行器故障,目标是在保证安全性的前提下提升系统性能。为了将控制 barrier 函数(CBF)与 RL 相结合,提出了一种新型的 CBF,称为高阶倒数控制 barrier 函数(HO-RCBF),以处理学习过程中的高相对阶约束。然后,提出了梯度相似性的概念,以量化安全梯度和性能梯度之间的关系。最后,在安全 RL 框架中引入了梯度操作和自适应机制,以增强性能并保证安全性。两个仿真例子表明,所提出的安全 RL 框架可以处理高相对阶约束,增强安全鲁棒性并提高系统性能。
🔬 方法详解
问题定义:论文旨在解决非线性系统在存在高相对阶状态约束、未知时变扰动和执行器故障的情况下,如何利用强化学习进行安全且高性能的最优控制问题。现有方法要么过于保守以保证安全,导致性能下降,要么过于激进追求性能,忽略了安全性。
核心思路:论文的核心思路是将控制 barrier 函数(CBF)与强化学习相结合,利用CBF保证安全性,同时通过强化学习优化性能。关键在于设计一种适用于高相对阶约束的CBF,并有效地平衡安全性和性能之间的关系。
技术框架:整体框架包括以下几个主要模块:1) 使用强化学习算法(如Actor-Critic)学习控制策略;2) 设计高阶倒数控制 barrier 函数(HO-RCBF)来保证状态约束的安全性;3) 引入梯度相似性概念,量化安全梯度和性能梯度之间的关系;4) 利用梯度操作和自适应机制,调整控制策略,在保证安全性的前提下提升性能。
关键创新:论文的关键创新在于:1) 提出了高阶倒数控制 barrier 函数(HO-RCBF),能够处理高相对阶状态约束,解决了传统CBF在高相对阶系统中的应用难题;2) 提出了梯度相似性的概念,为量化安全性和性能之间的关系提供了一种新的方法;3) 将梯度操作和自适应机制融入安全RL框架,实现了在保证安全性的前提下提升性能。
关键设计:HO-RCBF的设计需要仔细选择barrier函数的阶数和参数,以确保其能够有效地约束状态。梯度相似性的计算需要选择合适的距离度量方法。梯度操作和自适应机制需要根据具体的系统特性进行调整,以实现最佳的性能提升效果。强化学习算法的选择也会影响最终的控制性能,常用的算法包括DDPG、TD3等。
🖼️ 关键图片

📊 实验亮点
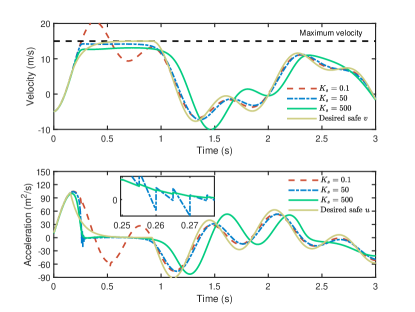
论文通过两个仿真例子验证了所提出方法的有效性。实验结果表明,该方法能够有效地处理高相对阶约束,增强系统的安全鲁棒性,并在保证安全性的前提下显著提高系统性能。具体的性能提升数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要安全保障的高动态系统控制,例如自动驾驶、机器人控制、航空航天等领域。通过学习增强的安全控制方法,可以在复杂和不确定的环境中实现安全可靠的自主运行,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Merely pursuing performance may adversely affect the safety, while a conservative policy for safe exploration will degrade the performance. How to balance the safety and performance in learning-based control problems is an interesting yet challenging issue. This paper aims to enhance system performance with safety guarantee in solving the reinforcement learning (RL)-based optimal control problems of nonlinear systems subject to high-relative-degree state constraints and unknown time-varying disturbance/actuator faults. First, to combine control barrier functions (CBFs) with RL, a new type of CBFs, termed high-order reciprocal control barrier function (HO-RCBF) is proposed to deal with high-relative-degree constraints during the learning process. Then, the concept of gradient similarity is proposed to quantify the relationship between the gradient of safety and the gradient of performance. Finally, gradient manipulation and adaptive mechanisms are introduced in the safe RL framework to enhance the performance with a safety guarantee. Two simulation examples illustrate that the proposed safe RL framework can address high-relative-degree constraint, enhance safety robustness and improve system performance.