Real-Time Integrated Dispatching and Idle Fleet Steering with Deep Reinforcement Learning for A Meal Delivery Platform
作者: Jingyi Cheng, Shadi Sharif Azadeh
分类: eess.SY, cs.AI
发布日期: 2025-01-10
💡 一句话要点
提出基于深度强化学习的集成调度与空闲车队引导框架,提升外卖平台效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 订单调度 车队管理 空闲车辆引导 马尔可夫决策过程
📋 核心要点
- 外卖平台面临实时调度和车队管理难题,现有方法难以兼顾效率、公平性和未来需求。
- 论文提出基于深度强化学习的双重控制框架,集成订单调度和空闲车辆引导,实现前瞻性决策。
- 实验表明,该框架能有效提升交付效率和工作负载公平性,缓解服务网络中的供应不足问题。
📝 摘要(中文)
为了实现高质量的服务和盈利能力,Uber Eats和Grubhub等外卖平台必须战略性地运营其车队,以确保当前订单的及时交付,同时减轻次优决策对未来快递员人手不足的影响。本研究旨在通过提出一个基于强化学习(RL)的战略双重控制框架,解决外卖平台的实时订单调度和空闲快递员引导问题。为了解决这些问题固有的顺序性,我们将订单调度和快递员引导建模为马尔可夫决策过程。通过深度强化学习(DRL)框架进行训练,我们利用显式预测的需求作为输入的一部分来获得战略策略。在我们的双重控制框架中,调度和引导策略以集成方式迭代训练。这些前瞻性策略可以实时执行并提供决策,同时共同考虑对本地和网络层面的影响。为了提高调度公平性,我们提出了卷积深度Q网络来构建公平的快递员嵌入。为了同时重新平衡服务网络内的供需,我们建议利用平均场近似的供需知识在本地层面重新分配空闲快递员。利用基于RL的战略双重控制框架生成的策略,我们发现交付效率和快递员之间工作负载分配的公平性得到了提高,并且服务网络内的供应不足状况得到了缓解。我们的研究揭示了设计基于RL的框架,从而为外卖平台和其他按需服务实现前瞻性实时运营。
🔬 方法详解
问题定义:论文旨在解决外卖平台中实时订单调度和空闲快递员引导问题。现有方法通常难以同时优化当前订单的交付效率、快递员的工作负载公平性,以及未来一段时间内的供需平衡。尤其是在需求波动较大的情况下,静态的调度策略容易导致某些区域快递员短缺,影响整体服务质量。
核心思路:论文的核心思路是将订单调度和空闲快递员引导问题建模为马尔可夫决策过程(MDP),并利用深度强化学习(DRL)训练一个能够预测未来需求并做出前瞻性决策的策略。通过集成调度和引导策略,并以迭代的方式进行训练,该框架能够同时优化局部和全局层面的性能。
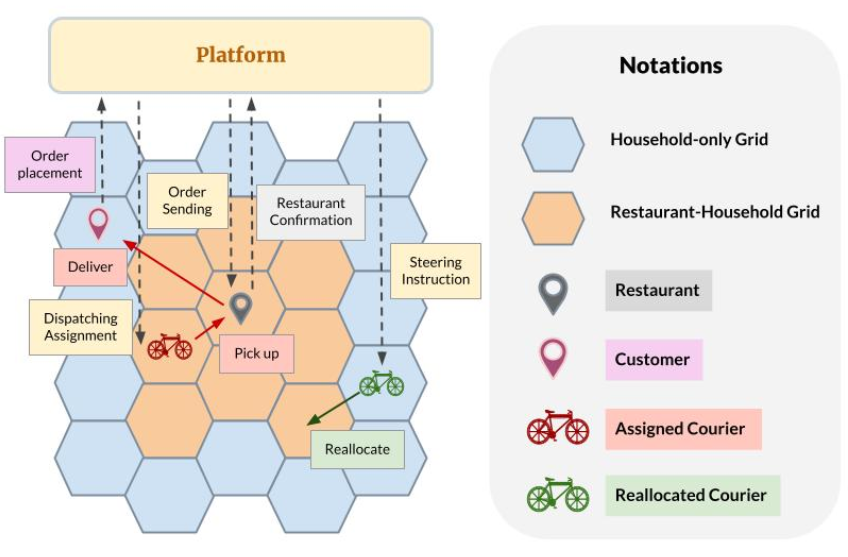
技术框架:该框架包含两个主要模块:订单调度模块和空闲快递员引导模块。两个模块共享一个深度强化学习模型,该模型以当前状态(包括订单信息、快递员位置、预测需求等)作为输入,输出调度和引导决策。调度模块负责将订单分配给合适的快递员,引导模块负责将空闲快递员重新分配到需求较高的区域。两个模块的策略以迭代的方式进行训练,以实现协同优化。
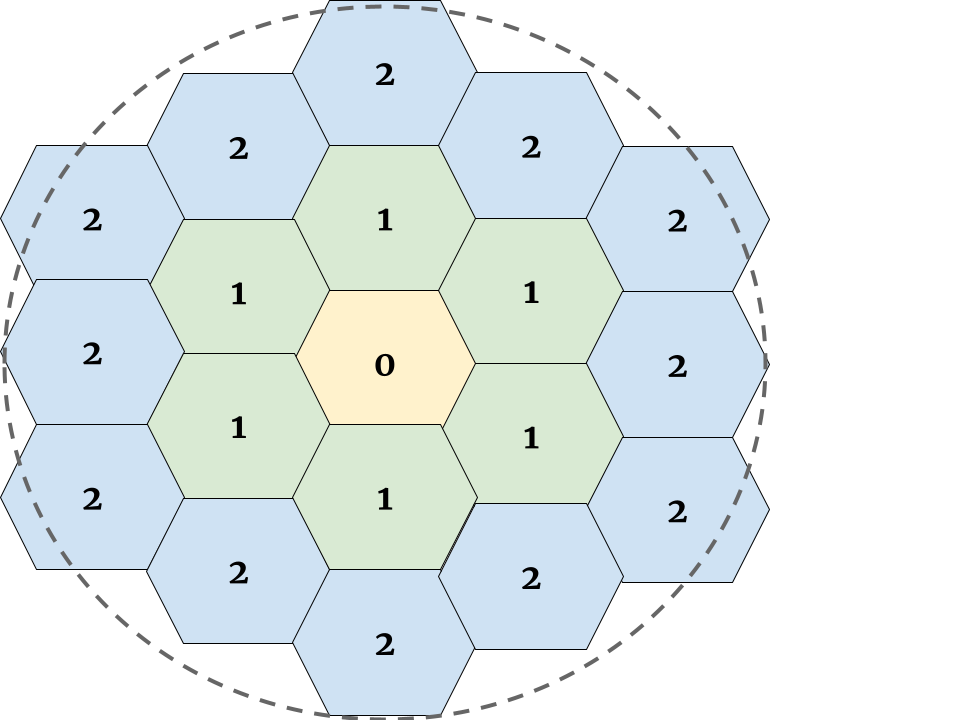
关键创新:论文的关键创新在于提出了一个集成的双重控制框架,能够同时优化订单调度和空闲快递员引导。此外,论文还提出了利用卷积深度Q网络(CDQN)构建公平的快递员嵌入,以提高调度公平性。利用平均场近似的供需知识来指导空闲快递员的重新分配,从而实现供需平衡。
关键设计:论文使用深度Q网络(DQN)作为强化学习模型的基础,并针对具体问题进行了改进。例如,使用卷积层来提取快递员的特征,并使用平均场近似来估计供需关系。损失函数的设计也考虑了效率和公平性两个方面。具体的参数设置和网络结构在论文中有详细描述,但未在摘要中体现。
🖼️ 关键图片

📊 实验亮点
论文实验结果表明,所提出的基于深度强化学习的双重控制框架能够显著提高交付效率和工作负载公平性。具体而言,与传统方法相比,该框架能够减少平均交付时间,并降低快递员之间工作负载的差异性。此外,该框架还能有效缓解服务网络中的供应不足状况,提高整体服务质量。
🎯 应用场景
该研究成果可应用于各种按需服务平台,如外卖、网约车、跑腿服务等。通过优化调度和车队管理,可以提高服务效率、降低运营成本、提升用户满意度,并实现更公平的资源分配。该方法也为其他涉及动态资源分配的优化问题提供了借鉴。
📄 摘要(原文)
To achieve high service quality and profitability, meal delivery platforms like Uber Eats and Grubhub must strategically operate their fleets to ensure timely deliveries for current orders while mitigating the consequential impacts of suboptimal decisions that leads to courier understaffing in the future. This study set out to solve the real-time order dispatching and idle courier steering problems for a meal delivery platform by proposing a reinforcement learning (RL)-based strategic dual-control framework. To address the inherent sequential nature of these problems, we model both order dispatching and courier steering as Markov Decision Processes. Trained via a deep reinforcement learning (DRL) framework, we obtain strategic policies by leveraging the explicitly predicted demands as part of the inputs. In our dual-control framework, the dispatching and steering policies are iteratively trained in an integrated manner. These forward-looking policies can be executed in real-time and provide decisions while jointly considering the impacts on local and network levels. To enhance dispatching fairness, we propose convolutional deep Q networks to construct fair courier embeddings. To simultaneously rebalance the supply and demand within the service network, we propose to utilize mean-field approximated supply-demand knowledge to reallocate idle couriers at the local level. Utilizing the policies generated by the RL-based strategic dual-control framework, we find the delivery efficiency and fairness of workload distribution among couriers have been improved, and under-supplied conditions have been alleviated within the service network. Our study sheds light on designing an RL-based framework to enable forward-looking real-time operations for meal delivery platforms and other on-demand services.