Lyapunov-based reinforcement learning for distributed control with stability guarantee
作者: Jingshi Yao, Minghao Han, Xunyuan Yin
分类: eess.SY
发布日期: 2024-12-14
备注: 28 pages, 10 figures, journal, Computers and Chemical Engineering
💡 一句话要点
提出一种基于Lyapunov稳定性的强化学习方法,用于具有稳定性保证的非线性系统分布式控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Lyapunov稳定性 强化学习 分布式控制 非线性系统 无模型控制
📋 核心要点
- 现有分布式控制方法难以保证非线性系统的闭环稳定性,且对系统模型依赖性强。
- 利用Lyapunov稳定性理论,设计局部强化学习控制策略,保证分布式控制的闭环稳定性。
- 通过基准化学过程验证,该方法在保证稳定性的前提下,实现了有效的分布式控制。
📝 摘要(中文)
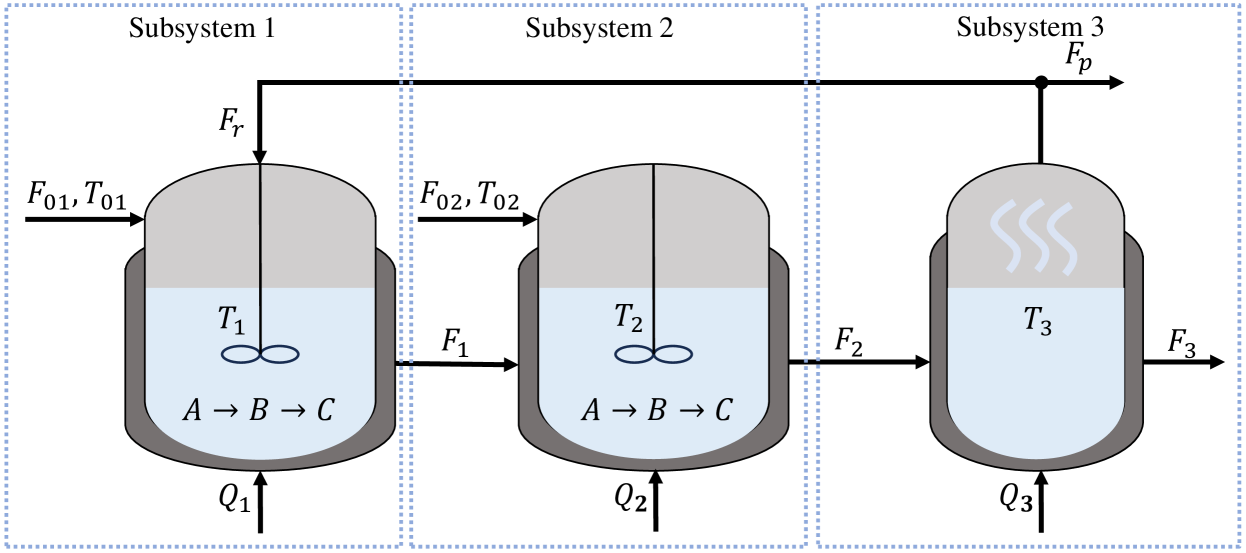
本文提出了一种基于Lyapunov的强化学习方法,用于具有相互作用子系统的非线性系统的分布式控制,并保证闭环稳定性。具体而言,我们进行了详细的稳定性分析,并推导了基于Lyapunov定理的无模型分布式控制方案下确保闭环稳定性的充分条件。基于Lyapunov的条件用于指导每个子系统的局部强化学习控制策略的设计。局部控制器仅在训练阶段交换标量值信息,一旦训练完成并在在线实施控制器后,它们无需通信。使用包含两个反应器和一个分离器的基准化学过程评估了所提出方法的有效性和性能。
🔬 方法详解
问题定义:针对由相互作用的子系统组成的非线性系统,如何在分布式控制框架下,设计控制器以保证闭环系统的稳定性,同时避免对系统模型的精确依赖。现有方法通常需要精确的系统模型或难以保证稳定性。
核心思路:利用Lyapunov稳定性理论,将稳定性条件转化为强化学习的约束或奖励函数,从而引导局部控制器的学习。每个子系统独立学习其控制策略,并通过交换标量信息进行协调,最终实现全局稳定。
技术框架:该方法包含以下几个主要阶段:1) 详细的稳定性分析,基于Lyapunov定理推导出闭环系统稳定的充分条件;2) 将稳定性条件转化为局部强化学习控制策略设计的指导原则;3) 每个子系统利用局部强化学习算法学习其控制策略,训练过程中子系统间交换标量信息;4) 训练完成后,将学习到的局部控制器部署到在线系统中,无需子系统间通信。
关键创新:该方法的核心创新在于将Lyapunov稳定性理论与强化学习相结合,从而在无模型的情况下,保证了分布式控制系统的闭环稳定性。与传统的强化学习方法相比,该方法能够显式地考虑系统的稳定性约束,避免了因探索不当而导致的系统不稳定。
关键设计:关键设计包括:1) Lyapunov函数的选择,需要根据具体的系统特性进行选择;2) 如何将Lyapunov稳定性条件转化为强化学习的奖励函数或约束条件,例如,可以将Lyapunov函数的导数作为奖励函数的组成部分,或者将Lyapunov函数的水平集作为状态空间的约束;3) 局部强化学习算法的选择,可以选择任何合适的强化学习算法,例如Q-learning、SARSA或Actor-Critic方法。
🖼️ 关键图片

📊 实验亮点
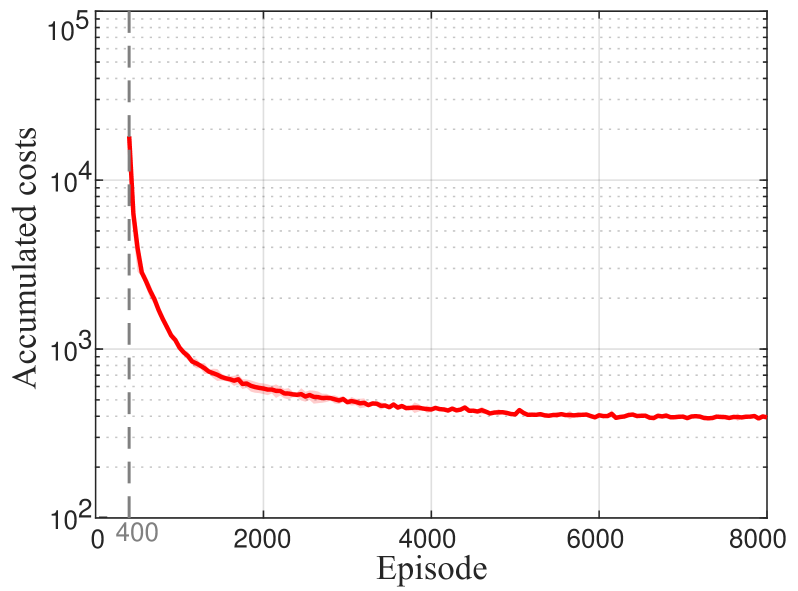
通过对包含两个反应器和一个分离器的基准化学过程进行评估,验证了所提出方法的有效性和性能。实验结果表明,该方法能够在保证闭环稳定性的前提下,实现对化学过程的有效控制。与其他分布式控制方法相比,该方法无需精确的系统模型,且具有更强的鲁棒性。
🎯 应用场景
该方法可应用于各种复杂系统的分布式控制,例如智能电网、多机器人系统、交通网络和化工过程等。通过保证系统的稳定性,可以提高系统的可靠性和安全性,降低运行成本,并实现更高效的资源利用。该方法在工业控制领域具有广阔的应用前景。
📄 摘要(原文)
In this paper, we propose a Lyapunov-based reinforcement learning method for distributed control of nonlinear systems comprising interacting subsystems with guaranteed closed-loop stability. Specifically, we conduct a detailed stability analysis and derive sufficient conditions that ensure closed-loop stability under a model-free distributed control scheme based on the Lyapunov theorem. The Lyapunov-based conditions are leveraged to guide the design of local reinforcement learning control policies for each subsystem. The local controllers only exchange scalar-valued information during the training phase, yet they do not need to communicate once the training is completed and the controllers are implemented online. The effectiveness and performance of the proposed method are evaluated using a benchmark chemical process that contains two reactors and one separator.