Deep Reinforcement Learning for Scalable Multiagent Spacecraft Inspection
作者: Kyle Dunlap, Nathaniel Hamilton, Kerianne L. Hobbs
分类: eess.SY
发布日期: 2024-12-13
💡 一句话要点
提出基于深度强化学习的可扩展多智能体航天器检查方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 航天器检查 可扩展观测空间 深度强化学习 自主控制
📋 核心要点
- 现有航天器任务管理面临挑战,人类操作员负担重,亟需自主控制方法。
- 论文提出一种可扩展的观测空间,使智能体在航天器数量变化时仍能有效通信。
- 通过航天器检查任务验证,该方法能使智能体更高效地完成任务,优于无信息交流的基线。
📝 摘要(中文)
随着在轨航天器数量的持续增加,人类操作员管理每个任务变得越来越具有挑战性。因此,需要自主控制方法来减轻操作员的负担。强化学习(RL)是一种自主控制方法,已被证明在各种复杂任务中取得了巨大成功。对于具有多个受控航天器(或智能体)的任务,智能体之间的通信和相互了解至关重要,这些信息通常作为输入观测值提供给神经网络控制器(NNC)。本文开发了一种可扩展的观测空间,该空间使用恒定的观测大小来提供有关所有其他智能体的信息,而不是修改观测值的大小来适应任务中航天器数量的变化。这种方法类似于激光雷达传感器,可以确定环境中其他物体的距离。该观测空间应用于航天器检查任务,其中使用RL训练多个副航天器以合作检查被动主航天器。预期可扩展的观测空间将使智能体能够比没有智能体间信息交流的基线解决方案更有效地完成任务。
🔬 方法详解
问题定义:论文旨在解决多智能体航天器检查任务中,随着智能体数量变化,传统强化学习方法观测空间维度不固定的问题。现有方法难以适应智能体数量的变化,需要针对不同数量的智能体重新设计观测空间和神经网络结构,泛化能力差。
核心思路:论文的核心思路是设计一种可扩展的观测空间,该观测空间的大小与智能体数量无关,始终保持恒定。每个智能体通过该观测空间获取其他智能体的信息,类似于激光雷达传感器获取周围物体距离信息的方式。这样,即使智能体数量发生变化,神经网络控制器(NNC)的输入维度也保持不变,从而提高了模型的泛化能力和可扩展性。
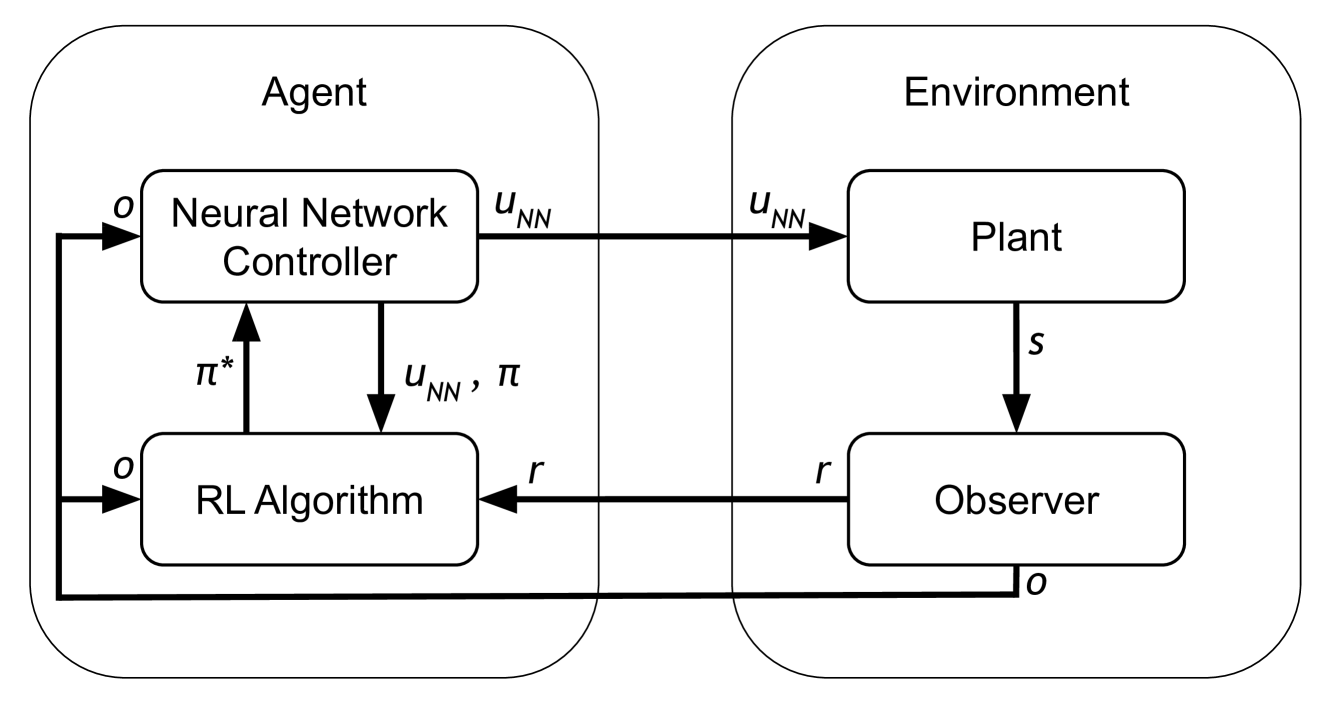
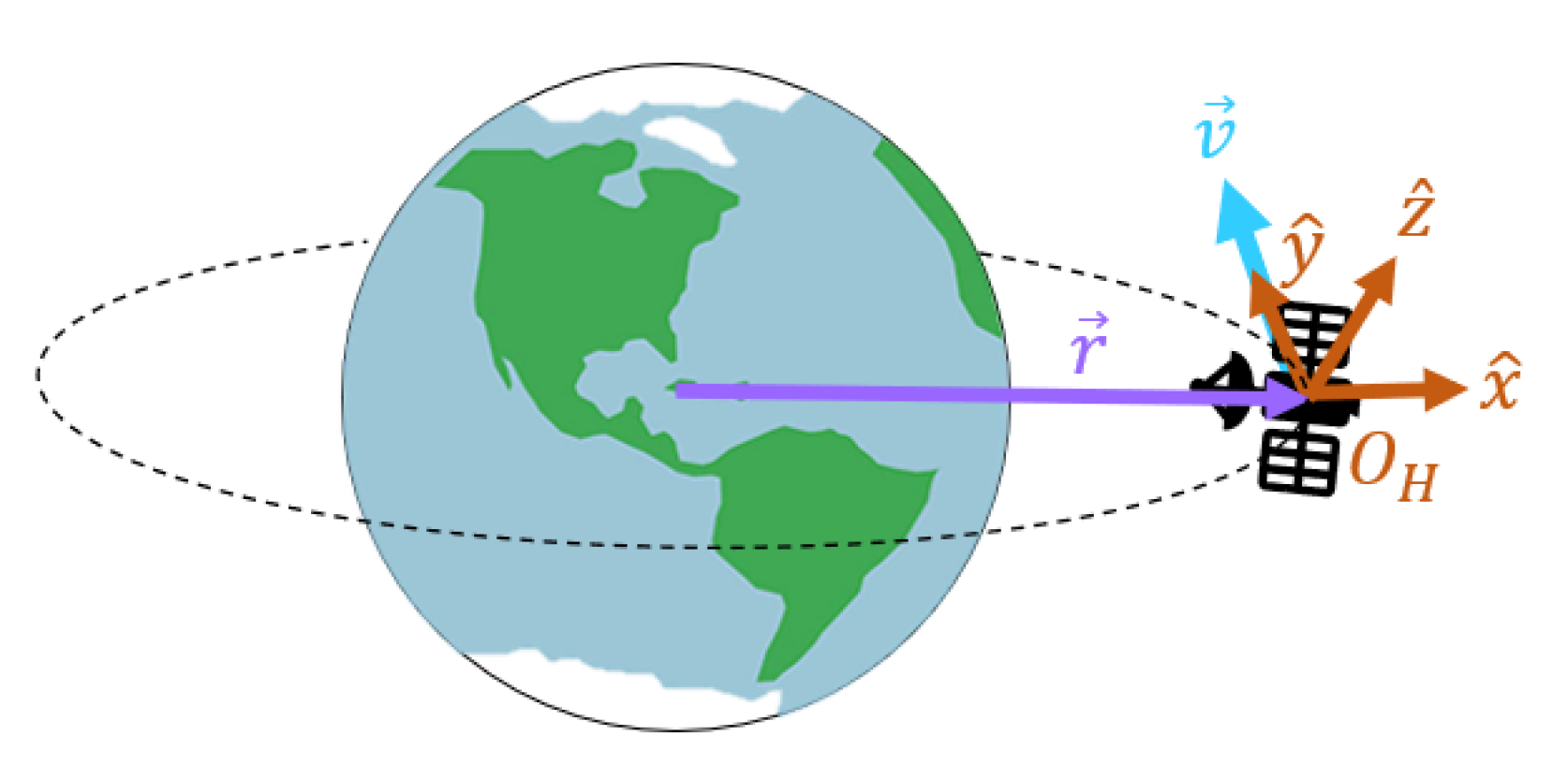
技术框架:整体框架采用多智能体强化学习(MARL)范式。每个副航天器作为一个智能体,通过与环境交互获取奖励,并使用深度强化学习算法训练神经网络控制器(NNC)。NNC根据当前状态(包括可扩展的观测空间)选择动作,控制航天器的姿态和位置。多个副航天器协同合作,完成对主航天器的检查任务。
关键创新:最重要的技术创新点在于可扩展的观测空间设计。该观测空间不依赖于智能体数量,而是通过一种相对位置和距离的表示方法,将其他智能体的信息编码到一个固定大小的向量中。这种设计使得模型能够适应不同数量的智能体,无需重新训练或修改网络结构。
关键设计:可扩展观测空间的关键设计在于使用相对距离和角度来表示其他智能体的位置。具体来说,对于每个智能体,观测空间包含其他所有智能体相对于自身的距离和方位角。这些信息被归一化到[0, 1]范围内,并作为神经网络的输入。损失函数采用标准的强化学习损失函数,例如Actor-Critic算法中的策略梯度损失和值函数损失。网络结构采用多层感知机(MLP),输入层的大小与可扩展观测空间的维度相同,输出层的大小与动作空间的维度相同。
🖼️ 关键图片

📊 实验亮点
论文通过航天器检查任务验证了所提出方法的可行性和有效性。实验结果表明,与没有智能体间信息交流的基线方法相比,使用可扩展观测空间的智能体能够更有效地完成任务,收敛速度更快,获得的奖励更高。具体的性能提升数据在论文中给出,表明该方法在多智能体协同任务中具有显著优势。
🎯 应用场景
该研究成果可应用于各种多智能体协同任务,例如编队飞行、协同搜索、环境监测等。在航天领域,可用于实现自主航天器集群的在轨服务、空间碎片清除、行星探测等任务,降低对地面控制的依赖,提高任务效率和安全性。该方法具有良好的可扩展性,能够适应未来大规模航天器集群的应用需求。
📄 摘要(原文)
As the number of spacecraft in orbit continues to increase, it is becoming more challenging for human operators to manage each mission. As a result, autonomous control methods are needed to reduce this burden on operators. One method of autonomous control is Reinforcement Learning (RL), which has proven to have great success across a variety of complex tasks. For missions with multiple controlled spacecraft, or agents, it is critical for the agents to communicate and have knowledge of each other, where this information is typically given to the Neural Network Controller (NNC) as an input observation. As the number of spacecraft used for the mission increases or decreases, rather than modifying the size of the observation, this paper develops a scalable observation space that uses a constant observation size to give information on all of the other agents. This approach is similar to a lidar sensor, where determines ranges of other objects in the environment. This observation space is applied to a spacecraft inspection task, where RL is used to train multiple deputy spacecraft to cooperate and inspect a passive chief spacecraft. It is expected that the scalable observation space will allow the agents to learn to complete the task more efficiently compared to a baseline solution where no information is communicated between agents.