Action-Attentive Deep Reinforcement Learning for Autonomous Alignment of Beamlines
作者: Siyu Wang, Shengran Dai, Jianhui Jiang, Shuang Wu, Yufei Peng, Junbin Zhang
分类: eess.SY, cs.LG
发布日期: 2024-11-19
备注: 17 pages, 5 figures
💡 一句话要点
提出基于动作注意力的深度强化学习方法,用于光束线自动对准。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 光束线对准 深度强化学习 动作注意力 同步辐射 自动化控制
📋 核心要点
- 光束线对准是同步辐射实验的关键步骤,传统手动对准耗时且易出错,现有自动化方法未能充分利用光束状态信息和元件特性。
- 论文提出一种基于动作注意力的深度强化学习方法,通过智能体学习调整策略,同时考虑光束状态差异和光学元件的影响。
- 在模拟光束线上实验表明,该方法优于现有方法,动作注意力机制的有效性通过消融实验得到验证。
📝 摘要(中文)
同步辐射光源在材料科学、生物学和化学等领域发挥着关键作用。光束线作为同步辐射的关键子系统,用于调节和引导辐射到样品进行分析。然而,光束线的对准是一个复杂且耗时的过程,主要由经验丰富的工程师手动完成。光学元件的微小错位会严重影响光束的性质,导致次优的实验结果。现有的自动化方法,如贝叶斯优化(BO)和强化学习(RL),虽然提高了性能,但仍存在局限性。它们没有充分考虑当前和目标光束性质之间的关系,而这对于确定调整至关重要。此外,光学元件的物理特性也被忽略,例如需要调整特定设备来控制输出光束的光斑大小或位置。本文通过将光束线对准建模为马尔可夫决策过程(MDP),并使用RL训练智能体来解决这个问题。智能体根据当前和目标光束状态计算调整值,执行动作,并迭代直到达到最佳参数。设计了一个具有动作注意力的策略网络,通过考虑状态差异和光学元件的影响来改进决策。在两个模拟光束线上的实验表明,我们的算法优于现有方法,消融研究突出了基于动作注意力的策略网络的有效性。
🔬 方法详解
问题定义:论文旨在解决同步辐射光束线自动对准问题。现有方法,如贝叶斯优化和传统强化学习,在光束线对准方面存在不足,未能充分考虑当前和目标光束状态之间的关系,也忽略了光学元件的物理特性,导致对准效率和精度不高。人工对准则依赖专家经验,效率低且容易出错。
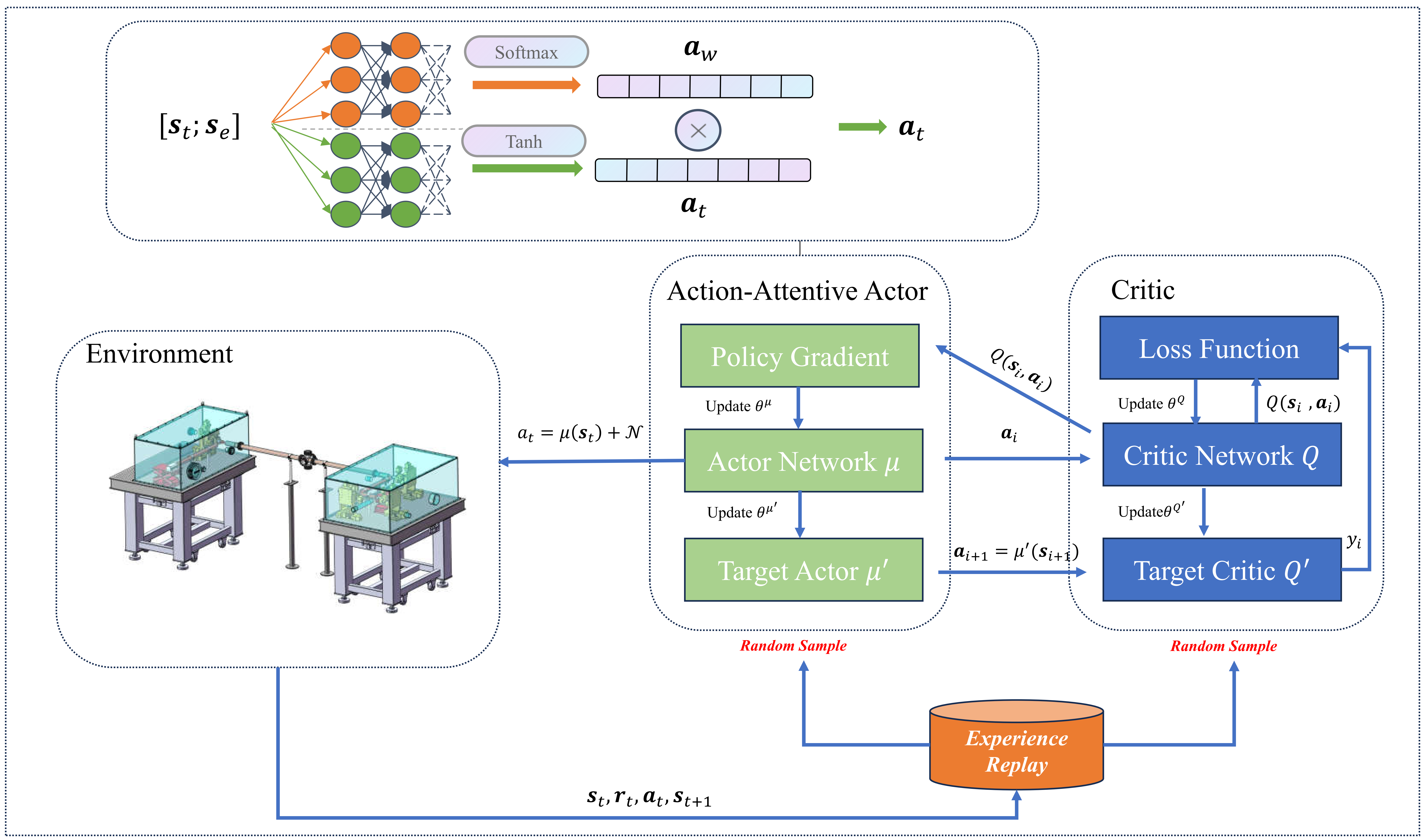
核心思路:论文的核心思路是将光束线对准问题建模为马尔可夫决策过程(MDP),并利用强化学习训练智能体。智能体通过观察当前光束状态和目标光束状态的差异,以及考虑不同光学元件对光束的影响,学习最优的调整策略。动作注意力机制的引入,使得智能体能够更加关注对光束性质影响最大的光学元件,从而提高对准效率。
技术框架:整体框架包括以下几个主要模块:1) 环境建模:将光束线建模为MDP环境,包括状态空间(光束参数)、动作空间(光学元件调整)和奖励函数(基于光束状态与目标的接近程度)。2) 智能体设计:采用深度强化学习算法训练智能体,智能体负责根据当前状态选择动作。3) 策略网络:使用深度神经网络作为策略网络,输入为当前和目标光束状态的差异,输出为每个光学元件的调整值。4) 动作执行与反馈:智能体执行动作后,环境更新状态,并返回奖励信号,用于更新策略网络。
关键创新:论文的关键创新在于引入了动作注意力机制。传统的强化学习方法通常平等地对待所有动作,而忽略了不同光学元件对光束性质的影响差异。动作注意力机制通过学习每个光学元件的重要性权重,使得智能体能够更加关注对光束性质影响最大的元件,从而提高对准效率和精度。这种机制允许网络学习哪些动作对于达到目标状态最为重要,并相应地调整策略。
关键设计:策略网络采用深度神经网络结构,包括输入层、隐藏层和输出层。输入层接收当前和目标光束状态的差异,隐藏层提取特征,输出层输出每个光学元件的调整值。动作注意力机制通过一个注意力模块实现,该模块根据输入特征计算每个光学元件的注意力权重,并将权重应用于输出层的调整值。奖励函数的设计至关重要,通常采用光束状态与目标状态之间的距离作为奖励信号,并加入稀疏奖励以鼓励探索。
🖼️ 关键图片

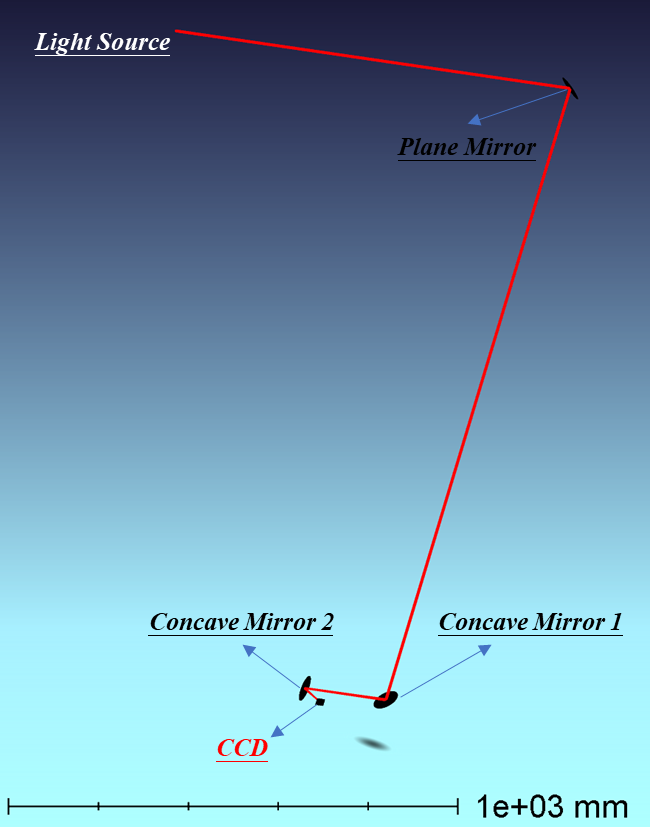
📊 实验亮点
实验结果表明,所提出的基于动作注意力的深度强化学习方法在两个模拟光束线上均优于现有的贝叶斯优化和传统强化学习方法。具体而言,该方法能够更快地达到目标光束状态,并且具有更高的对准精度。消融研究进一步验证了动作注意力机制的有效性,证明其能够显著提高对准效率。
🎯 应用场景
该研究成果可应用于各种同步辐射光源的光束线自动对准,提高实验效率和数据质量。此外,该方法也可推广到其他需要精确控制和调整的复杂系统,例如激光系统、光学成像系统等,具有广泛的应用前景和实际价值。未来,该技术有望实现光束线的完全自动化运行,减少对人工干预的依赖。
📄 摘要(原文)
Synchrotron radiation sources play a crucial role in fields such as materials science, biology, and chemistry. The beamline, a key subsystem of the synchrotron, modulates and directs the radiation to the sample for analysis. However, the alignment of beamlines is a complex and time-consuming process, primarily carried out manually by experienced engineers. Even minor misalignments in optical components can significantly affect the beam's properties, leading to suboptimal experimental outcomes. Current automated methods, such as bayesian optimization (BO) and reinforcement learning (RL), although these methods enhance performance, limitations remain. The relationship between the current and target beam properties, crucial for determining the adjustment, is not fully considered. Additionally, the physical characteristics of optical elements are overlooked, such as the need to adjust specific devices to control the output beam's spot size or position. This paper addresses the alignment of beamlines by modeling it as a Markov Decision Process (MDP) and training an intelligent agent using RL. The agent calculates adjustment values based on the current and target beam states, executes actions, and iterates until optimal parameters are achieved. A policy network with action attention is designed to improve decision-making by considering both state differences and the impact of optical components. Experiments on two simulated beamlines demonstrate that our algorithm outperforms existing methods, with ablation studies highlighting the effectiveness of the action attention-based policy network.