Design And Optimization Of Multi-rendezvous Manoeuvres Based On Reinforcement Learning And Convex Optimization
作者: Antonio López Rivera, Lucrezia Marcovaldi, Jesús Ramírez, Alex Cuenca, David Bermejo
分类: eess.SY
发布日期: 2024-11-18
备注: 18 pages, 12 figures, 5 tables
期刊: Proceedings of the International Astronautical Congress, 75, 2024
💡 一句话要点
提出基于强化学习和凸优化的多目标交会轨迹设计与优化框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标交会 航天器路由 强化学习 凸优化 序列凸规划
📋 核心要点
- 多目标交会问题是航天器任务规划中的NP-hard难题,需要确定访问目标的最佳顺序和相应的最优轨迹。
- 该论文提出了一种结合强化学习和凸优化的框架,利用强化学习训练的路由策略来改进组合优化过程。
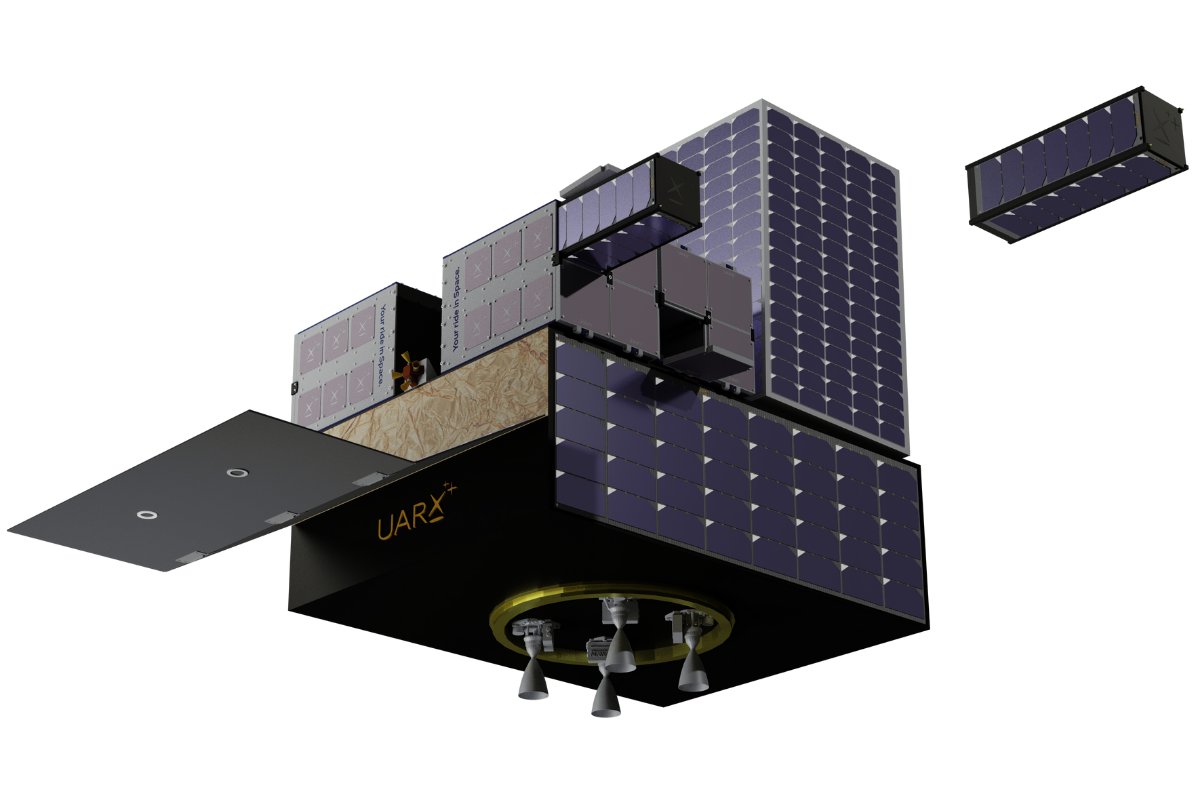
- 实验结果表明,该框架能够有效地应用于航天器路由问题,并成功应用于UARX Space OSSIE任务。
📝 摘要(中文)
本文提出了一种用于设计和优化多目标交会轨迹的框架,该框架结合了启发式组合优化和序列凸规划。该框架具有高度模块化特性,能够利用高级方法和手工启发式算法获得的候选解。通过集成基于注意力机制并使用强化学习训练的路由策略,来改进组合优化过程的性能,证明了强化学习方法可以有效应用于航天器路由问题。最后,将该框架应用于UARX Space OSSIE任务,能够全面探索任务设计空间,为各种任务场景找到最优的航行路线和轨迹。
🔬 方法详解
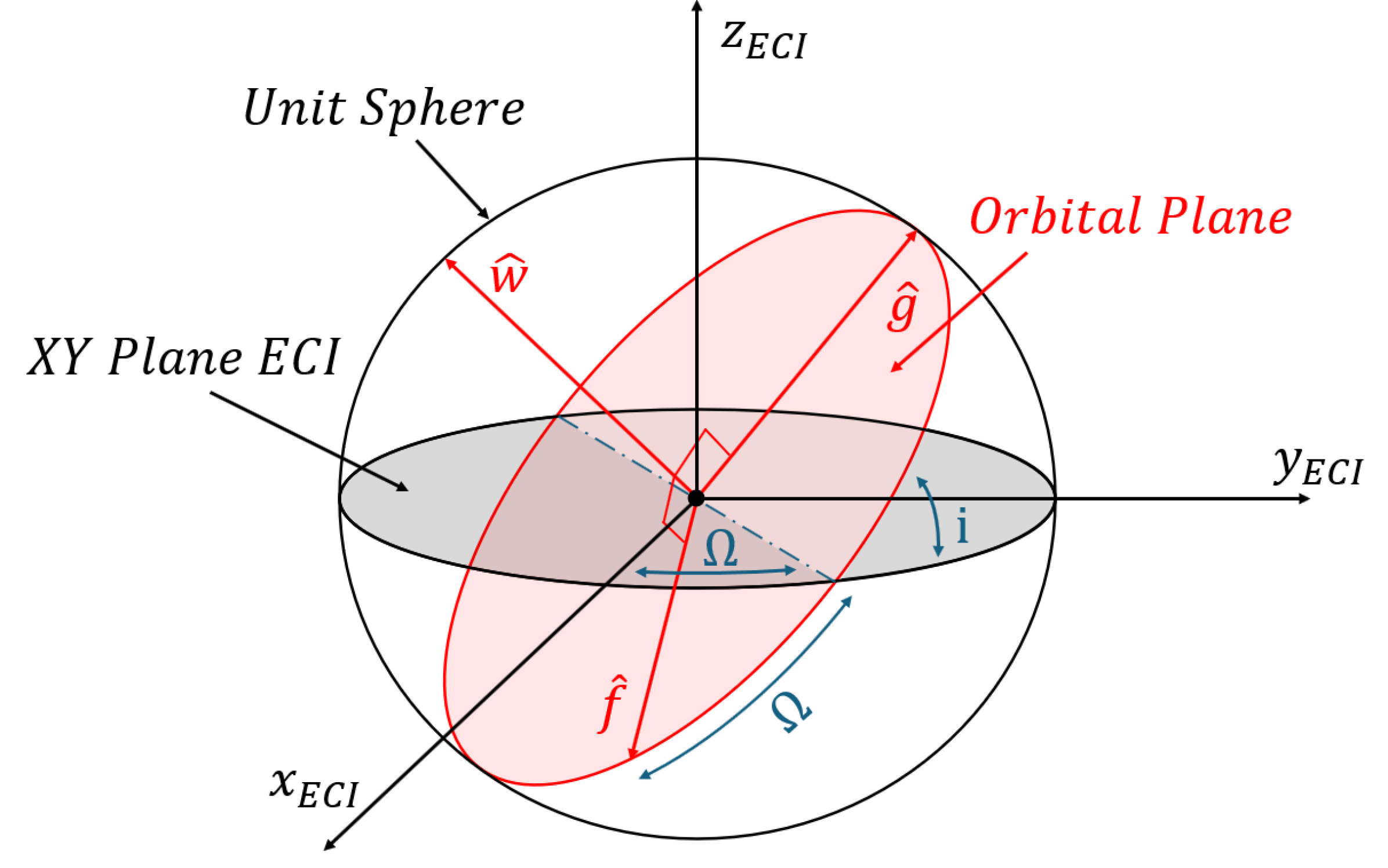
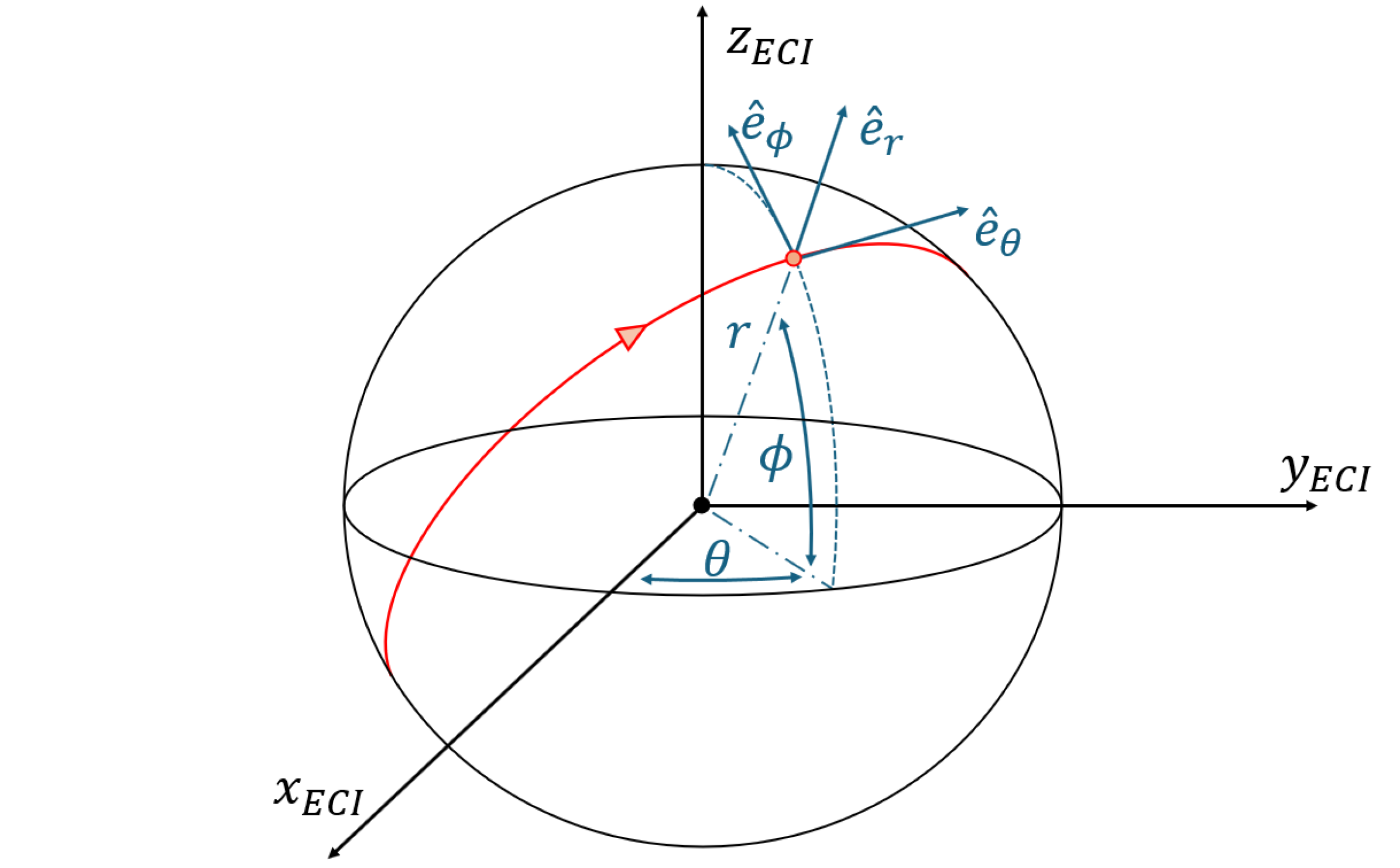
问题定义:论文旨在解决多目标交会任务中的航天器路由问题,这是一个NP-hard问题。现有方法在确定最优目标访问顺序和轨迹时面临计算复杂度高、难以找到全局最优解的挑战。传统方法可能依赖于手工设计的启发式算法,但这些算法在复杂场景下性能受限。
核心思路:论文的核心思路是结合强化学习的全局搜索能力和凸优化的局部优化能力。强化学习用于学习一个路由策略,该策略能够预测访问目标的最佳顺序。然后,使用序列凸规划来优化每个目标之间的轨迹,从而得到整体的最优轨迹。这种结合利用了强化学习在组合优化问题上的优势,以及凸优化在求解非线性规划问题上的高效性。
技术框架:整体框架包含以下几个主要模块:1) 基于强化学习的路由策略学习模块:使用注意力机制构建路由策略网络,通过强化学习算法(具体算法未知)进行训练,学习预测目标访问顺序。2) 组合优化模块:利用训练好的路由策略生成候选的目标访问顺序。3) 序列凸规划模块:对于每个候选的访问顺序,使用序列凸规划方法优化航天器在各个目标之间的转移轨迹。4) 评估与选择模块:评估每个候选解的性能指标(如燃料消耗、任务时间等),选择最优的解。
关键创新:论文的关键创新在于将强化学习方法引入到航天器多目标交会问题的组合优化中。与传统的启发式算法相比,强化学习能够通过学习数据中的模式,自动发现更优的路由策略。此外,该框架的模块化设计使得可以灵活地集成不同的优化算法和启发式方法。
关键设计:论文中关键的设计包括:1) 使用注意力机制构建路由策略网络,以便更好地处理目标之间的关系。2) 使用强化学习算法训练路由策略网络,奖励函数的设计需要考虑燃料消耗、任务时间等因素。3) 使用序列凸规划方法优化轨迹,需要选择合适的凸松弛方法和约束条件。具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文将提出的框架应用于UARX Space OSSIE任务,结果表明该框架能够有效地探索任务设计空间,并为各种任务场景找到最优的航行路线和轨迹。虽然论文中没有给出具体的性能数据和对比基线,但强调了该框架在实际任务中的可行性和有效性。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于在轨服务、星座部署、空间碎片清除等领域。通过优化航天器的路由和轨迹,可以降低任务成本、提高任务效率,并减少空间碎片带来的风险。该方法具有广泛的应用前景,能够为未来的航天任务提供更高效、更可靠的解决方案。
📄 摘要(原文)
Optimizing space vehicle routing is crucial for critical applications such as on-orbit servicing, constellation deployment, and space debris de-orbiting. Multi-target Rendezvous presents a significant challenge in this domain. This problem involves determining the optimal sequence in which to visit a set of targets, and the corresponding optimal trajectories: this results in a demanding NP-hard problem. We introduce a framework for the design and refinement of multi-rendezvous trajectories based on heuristic combinatorial optimization and Sequential Convex Programming. Our framework is both highly modular and capable of leveraging candidate solutions obtained with advanced approaches and handcrafted heuristics. We demonstrate this flexibility by integrating an Attention-based routing policy trained with Reinforcement Learning to improve the performance of the combinatorial optimization process. We show that Reinforcement Learning approaches for combinatorial optimization can be effectively applied to spacecraft routing problems. We apply the proposed framework to the UARX Space OSSIE mission: we are able to thoroughly explore the mission design space, finding optimal tours and trajectories for a wide variety of mission scenarios.