Physical Informed-Inspired Deep Reinforcement Learning Based Bi-Level Programming for Microgrid Scheduling
作者: Yang Li, Jiankai Gao, Yuanzheng Li, Chen Chen, Sen Li, Mohammad Shahidehpour, Zhe Chen
分类: eess.SY
发布日期: 2024-10-15
备注: Accepted by IEEE Transactions on Industry Applications (Paper Id: 2023-KDSEM-1058)
💡 一句话要点
提出基于物理信息深度强化学习的双层规划微网调度模型,协调运营者和用户利益
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 微网调度 双层规划 深度强化学习 A3C算法 AutoML 优先经验回放 需求响应 热灵活性
📋 核心要点
- 传统微网调度方法难以应对复杂运行条件,且基于KKT的方法存在非凸限制,难以协调运营者和用户利益。
- 论文提出基于物理信息深度强化学习的双层规划模型,上层使用改进的A3C算法,下层使用DOCPLEX优化器,交替迭代求解。
- 实验结果表明,该方法能有效协调微网中多方利益,并在经济性和计算效率上优于其他强化学习方法。
📝 摘要(中文)
本文提出了一种基于物理信息深度强化学习(DRL)的双层规划微网调度模型,旨在协调复杂多变运行条件下微网中运营者和用户的利益,同时考虑了温控负载的热灵活性和需求响应。为了克服基于KKT方法的非凸限制,提出了一种基于DRL理论的优化求解方法,通过层间交替迭代来处理双层规划问题。具体而言,结合了异步优势行动者-评论家(A3C)算法和自动机器学习优先经验回放(AutoML-PER)策略,设计了一种改进的A3C算法,称为AutoML-PER-A3C,以解决上层问题;而DOCPLEX优化器被用于解决下层问题。在该求解过程中,AutoML用于自动优化超参数,PER通过提取最有价值的样本来提高学习效率和质量。测试结果表明,所提出的方法通过充分利用各种灵活性资源,成功地协调了微网中多个利益相关者之间的利益。此外,在经济可行性和计算效率方面,该方案大大超过了其他先进的强化学习方法。
🔬 方法详解
问题定义:微网调度问题旨在优化微网的运行,以满足用户需求并降低运营成本。传统方法,特别是基于KKT条件的优化方法,在处理非凸问题时面临挑战,并且难以适应微网运行的复杂性和不确定性。此外,协调微网运营者和用户之间的利益也是一个关键问题,需要考虑需求响应和灵活资源。
核心思路:论文的核心思路是利用深度强化学习(DRL)来解决双层规划问题,从而克服传统优化方法的局限性。通过将微网调度问题建模为马尔可夫决策过程(MDP),并使用DRL算法学习最优调度策略,可以有效地处理复杂性和不确定性。双层规划结构允许分别优化运营者和用户的目标,并通过迭代协调实现整体最优。
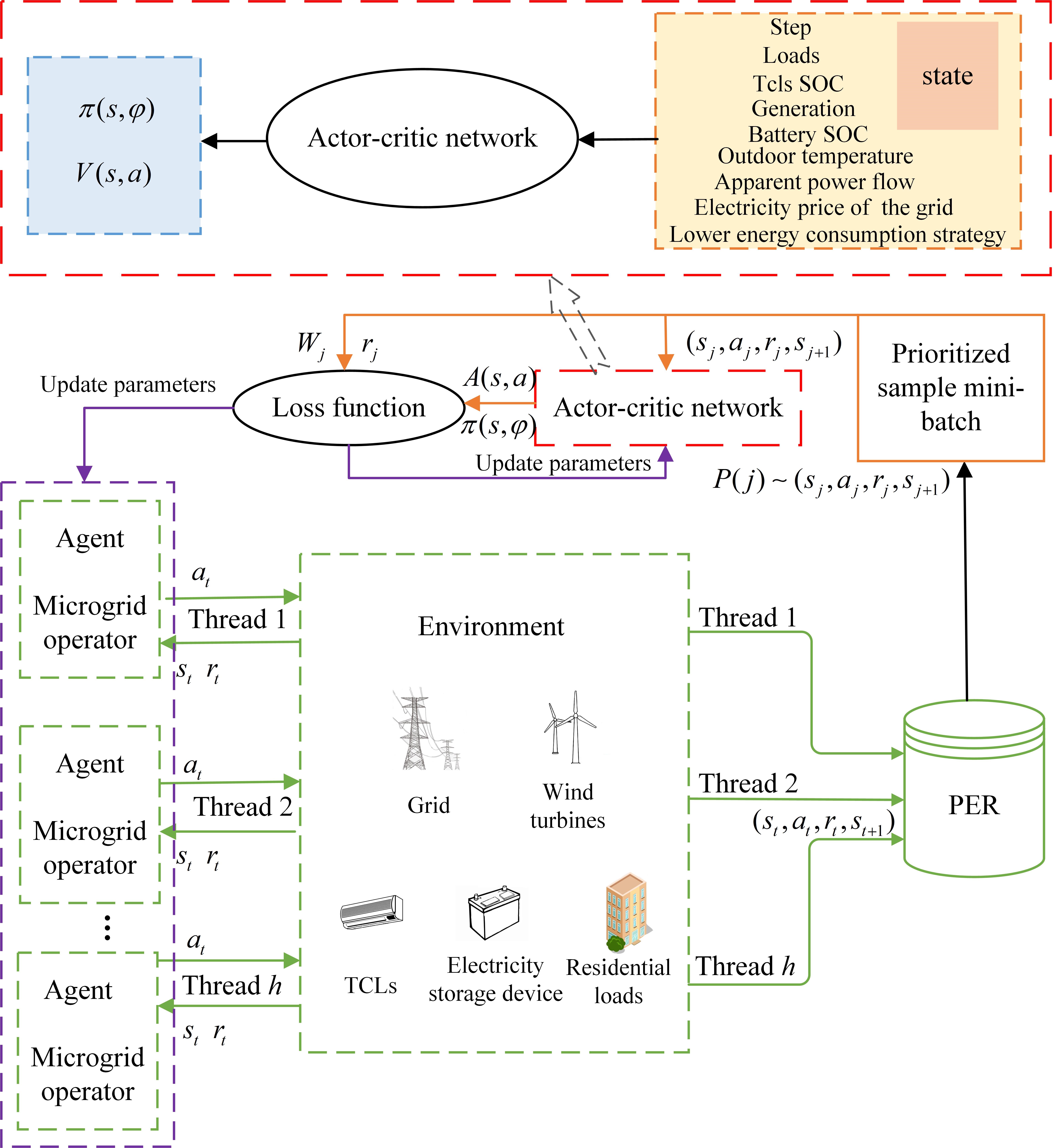
技术框架:该方法采用双层规划框架。上层问题由微网运营商解决,目标是最大化自身利益,使用改进的A3C算法(AutoML-PER-A3C)进行求解。下层问题由用户解决,目标是最小化自身成本,使用DOCPLEX优化器进行求解。上下层之间通过迭代进行协调,直到达到收敛。AutoML用于自动优化A3C算法的超参数,PER用于提高学习效率。
关键创新:该方法的关键创新在于将AutoML和PER策略集成到A3C算法中,提出了AutoML-PER-A3C算法。AutoML能够自动搜索最优超参数,提高算法的泛化能力。PER能够优先选择更有价值的样本进行学习,提高学习效率和质量。此外,使用DRL解决双层规划问题也是一个创新点,避免了传统方法对非凸问题的处理难题。
关键设计:A3C算法的网络结构包括Actor网络和Critic网络,分别用于学习策略和评估价值函数。AutoML使用贝叶斯优化等方法搜索A3C算法的学习率、折扣因子等超参数。PER使用优先级队列存储经验样本,并根据样本的TD误差确定优先级。损失函数包括Actor网络的策略梯度损失和Critic网络的均方误差损失。DOCPLEX优化器使用线性规划或混合整数规划等方法求解下层问题。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的AutoML-PER-A3C算法在微网调度问题上优于传统的A3C算法和其他强化学习方法。在经济性方面,该方法能够显著降低微网的运营成本。在计算效率方面,该方法能够更快地找到最优调度策略。具体数据未知,但原文强调了“vastly exceeds other advanced reinforcement learning methods”。
🎯 应用场景
该研究成果可应用于实际微网的优化调度,提高能源利用效率,降低运营成本,并促进可再生能源的消纳。通过协调微网运营者和用户之间的利益,可以提高微网的可靠性和稳定性。此外,该方法还可以推广到其他能源系统的优化调度问题,例如智能电网、区域能源系统等。
📄 摘要(原文)
To coordinate the interests of operator and users in a microgrid under complex and changeable operating conditions, this paper proposes a microgrid scheduling model considering the thermal flexibility of thermostatically controlled loads and demand response by leveraging physical informed-inspired deep reinforcement learning (DRL) based bi-level programming. To overcome the non-convex limitations of karush-kuhn-tucker (KKT)-based methods, a novel optimization solution method based on DRL theory is proposed to handle the bi-level programming through alternate iterations between levels. Specifically, by combining a DRL algorithm named asynchronous advantage actor-critic (A3C) and automated machine learning-prioritized experience replay (AutoML-PER) strategy to improve the generalization performance of A3C to address the above problems, an improved A3C algorithm, called AutoML-PER-A3C, is designed to solve the upper-level problem; while the DOCPLEX optimizer is adopted to address the lower-level problem. In this solution process, AutoML is used to automatically optimize hyperparameters and PER improves learning efficiency and quality by extracting the most valuable samples. The test results demonstrate that the presented approach manages to reconcile the interests between multiple stakeholders in MG by fully exploiting various flexibility resources. Furthermore, in terms of economic viability and computational efficiency, the proposal vastly exceeds other advanced reinforcement learning methods.