GreenLight-Gym: Reinforcement learning benchmark environment for control of greenhouse production systems
作者: Bart van Laatum, Eldert J. van Henten, Sjoerd Boersma
分类: eess.SY, cs.LG, math.OC
发布日期: 2024-10-06 (更新: 2025-05-09)
备注: This submission replaces our previous pre-print with the version accepted to the 2025 IFAC conference. A new Git repository (https://github.com/BartvLaatum/GreenLight-Gym) accompanies this paper; the repository for the prior version remains live at https://github.com/YourOrg/GreenLightGym. The earlier pre-print is still available on ArXiv under the previous submission number
期刊: IFAC-PapersOnLine 59 (23), (2025), 437-442
DOI: 10.1016/j.ifacol.2025.11.827
💡 一句话要点
GreenLight-Gym:温室生产系统控制的强化学习基准环境
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 温室控制 作物生产 基准环境 仿真 智能农业 GreenLight模型
📋 核心要点
- 温室作物生产控制面临复杂环境和不确定性挑战,传统控制方法难以优化。
- GreenLight-Gym通过高效的C++实现和灵活的Python接口,为强化学习控制提供基准环境。
- 实验表明,该环境能有效训练强化学习控制器,并在参数不确定性下表现良好,加速温室控制创新。
📝 摘要(中文)
本研究提出了GreenLight-Gym,这是一个新的、快速的、开源的基准环境,用于开发温室作物生产控制中的强化学习(RL)方法。它构建于最先进的GreenLight模型之上,采用可微分的C++实现,并利用CasADi框架进行高效的数值积分。GreenLight-Gym将仿真速度提高了17倍,优于原始GreenLight实现。一个模块化的Python环境包装器能够灵活地配置控制任务和基于RL的控制器。通过使用两种著名的RL算法在参数不确定性下学习控制器,证明了这种灵活性。GreenLight-Gym为推进RL方法和评估各种条件下的温室控制解决方案提供了一个标准化的基准。鼓励温室控制社区使用和扩展此基准,以加速温室作物生产的创新。
🔬 方法详解
问题定义:论文旨在解决温室作物生产控制中,现有方法难以应对复杂环境和参数不确定性的问题。传统控制方法往往依赖于精确的模型,难以适应温室环境的动态变化。此外,缺乏标准化的基准环境阻碍了强化学习方法在温室控制领域的应用和发展。
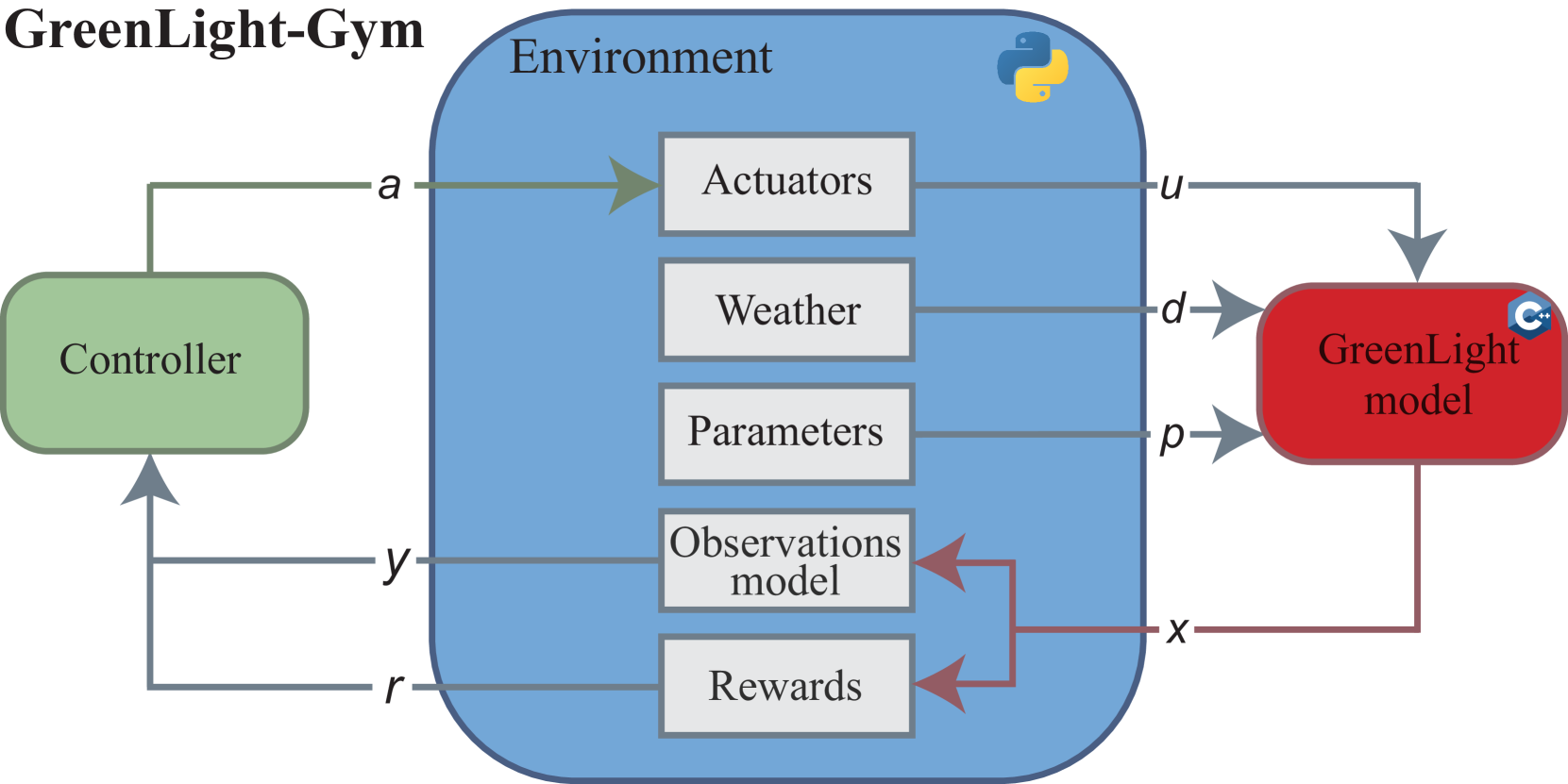
核心思路:论文的核心思路是构建一个快速、灵活且易于使用的强化学习基准环境,名为GreenLight-Gym。该环境基于GreenLight模型,并采用可微分的C++实现,以提高仿真速度。同时,提供模块化的Python接口,方便用户配置控制任务和强化学习控制器。
技术框架:GreenLight-Gym的整体架构包括三个主要部分:GreenLight模型的核心C++实现,CasADi框架用于高效数值积分,以及Python环境包装器。C++实现负责温室环境的仿真,CasADi框架加速计算过程,Python包装器提供灵活的配置选项,方便用户定义控制任务、选择强化学习算法和评估控制器性能。
关键创新:GreenLight-Gym的关键创新在于其高效的仿真速度和灵活的配置能力。通过采用可微分的C++实现和CasADi框架,仿真速度比原始GreenLight实现提高了17倍。模块化的Python接口允许用户轻松配置不同的控制任务和强化学习算法,从而促进了强化学习方法在温室控制领域的应用。
关键设计:GreenLight-Gym的关键设计包括:1) 使用CasADi框架进行数值积分,提高仿真效率;2) 提供多种预定义的控制任务,例如温度控制、湿度控制等;3) 支持多种强化学习算法,例如PPO、DQN等;4) 提供评估指标,例如作物产量、能源消耗等,方便用户评估控制器性能。
🖼️ 关键图片
📊 实验亮点
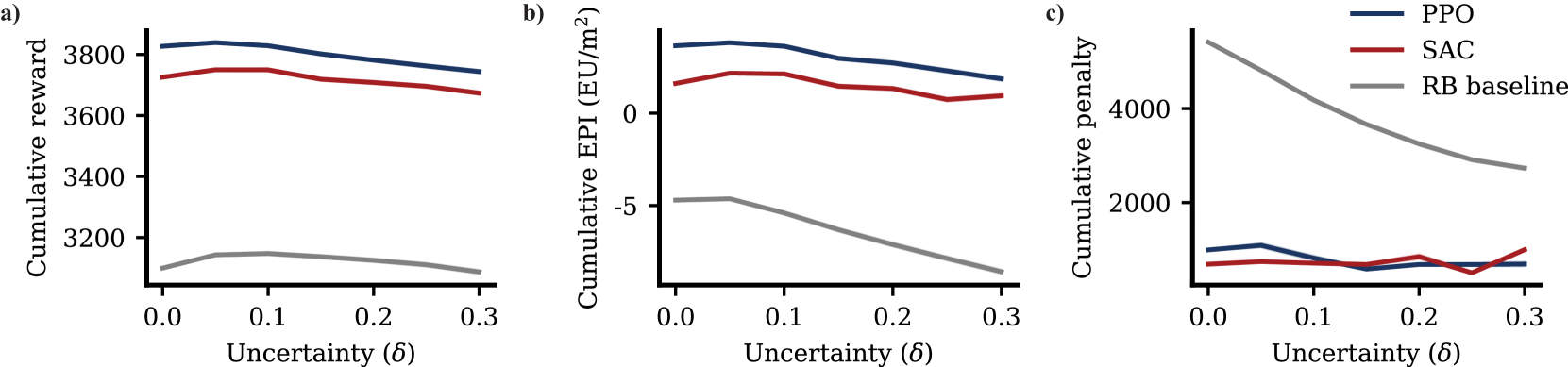
实验结果表明,GreenLight-Gym能够有效训练强化学习控制器,并在参数不确定性下表现良好。通过使用PPO和DQN算法,成功学习了温室环境的控制策略,实现了作物产量和能源效率的优化。与传统控制方法相比,强化学习控制器在复杂环境和不确定性条件下表现出更强的鲁棒性和适应性。
🎯 应用场景
GreenLight-Gym可应用于温室作物生产的智能化控制,通过强化学习优化环境参数,提高作物产量和质量,降低能源消耗。该环境还可用于研究不同控制策略对作物生长的影响,为温室设计和管理提供决策支持。未来,可扩展到其他农业生产系统,促进农业智能化发展。
📄 摘要(原文)
This study presents GreenLight-Gym, a new, fast, open-source benchmark environment for developing reinforcement learning (RL) methods in greenhouse crop production control. Built on the state-of-the-art GreenLight model, it features a differentiable C++ implementation leveraging the CasADi framework for efficient numerical integration. GreenLight-Gym improves simulation speed by a factor of 17 over the original GreenLight implementation. A modular Python environment wrapper enables flexible configuration of control tasks and RL-based controllers. This flexibility is demonstrated by learning controllers under parametric uncertainty using two well-known RL algorithms. GreenLight-Gym provides a standardized benchmark for advancing RL methodologies and evaluating greenhouse control solutions under diverse conditions. The greenhouse control community is encouraged to use and extend this benchmark to accelerate innovation in greenhouse crop production.